|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese|
Notas de clase, hojas de trucos
Base de datos. Apuntes de clase: brevemente, los más importantes
Directorio / Notas de clase, hojas de trucos tabla de contenidos
Conferencia No. 1. Introducción 1. Sistemas de gestión de bases de datos Sistemas de gestión de bases de datos (DBMS) son productos de software especializados que permiten: 1) almacenar permanentemente cantidades de datos arbitrariamente grandes (pero no infinitas); 2) extraer y modificar estos datos almacenados de una forma u otra, utilizando las llamadas consultas; 3) crear nuevas bases de datos, es decir, describir estructuras de datos lógicos y establecer su estructura, es decir, proporcionar una interfaz de programación; 4) acceder a los datos almacenados por varios usuarios al mismo tiempo (es decir, proporcionar acceso al mecanismo de gestión de transacciones). Por consiguiente, la Base de datos son conjuntos de datos bajo el control de los sistemas de gestión. Ahora, los sistemas de gestión de bases de datos son los productos de software más complejos del mercado y forman su base. En el futuro, está previsto llevar a cabo desarrollos en una combinación de sistemas de gestión de bases de datos convencionales con programación orientada a objetos (POO) y tecnologías de Internet. Inicialmente, los DBMS se basaban en jerárquico и modelos de datos de red, es decir, permitido trabajar solo con estructuras de árbol y gráfico. En el proceso de desarrollo en 1970, aparecieron los sistemas de gestión de bases de datos propuestos por Codd, basados en modelo de datos relacionales. 2. Bases de datos relacionales El término "relacional" proviene de la palabra inglesa "relación" - "relación". En el sentido matemático más general (como puede recordarse del curso clásico de álgebra de conjuntos) respeto - es un conjunto R = {(x1,..., Xn) | X1 ∈Un1,...,Xn ∈ An}, donde un1,...,An son los conjuntos que forman el producto cartesiano. De este modo, relación R es un subconjunto del producto cartesiano de conjuntos: A1 x... xAn : R⊆A 1 x... xAn. Por ejemplo, considere las relaciones binarias del orden estricto "mayor que" y "menor que" en el conjunto de pares ordenados de números A 1 = A2 = {3, 4, 5}: R> = {(3, 4), (4, 5), (3, 5)} ⊂ A1 x un2; R< = {(5, 4), (4, 3), (5, 3)} ⊂ A1 x un2. Estas relaciones se pueden presentar en forma de tablas. Razón "mayor que">:
Relación "menor que" R<:
Así, vemos que en las bases de datos relacionales, una gran variedad de datos se organizan en forma de relaciones y se pueden presentar en forma de tablas. Cabe señalar que estas dos relaciones R> y R< no son equivalentes entre sí, es decir, las tablas correspondientes a estas relaciones no son iguales entre sí. Entonces, las formas de representación de datos en bases de datos relacionales pueden ser diferentes. ¿Cómo se manifiesta en nuestro caso esta posibilidad de representación diferente? Relaciones R> y R< - estos son conjuntos, y un conjunto es una estructura desordenada, lo que significa que en las tablas correspondientes a estas relaciones, las filas se pueden intercambiar entre sí. Pero al mismo tiempo, los elementos de estos conjuntos son conjuntos ordenados, en nuestro caso, pares ordenados de números 3, 4, 5, lo que significa que las columnas no se pueden intercambiar. Así, hemos demostrado que la representación de una relación (en el sentido matemático) como una tabla con un orden arbitrario de filas y un número fijo de columnas es una forma aceptable y correcta de representación de relaciones. Pero si consideramos las relaciones R> y R< desde el punto de vista de la información contenida en ellos, está claro que son equivalentes. Por lo tanto, en las bases de datos relacionales, el concepto de "relación" tiene un significado ligeramente diferente al de la relación en las matemáticas generales. Es decir, no está relacionado con el ordenamiento por columnas en una forma tabular de presentación. En su lugar, se introducen los llamados esquemas de relación "fila - encabezado de columna", es decir, a cada columna se le asigna un encabezado, después del cual se pueden intercambiar libremente. Así es como se verá nuestra relación R> y R< en una base de datos relacional. Una relación de orden estricto (en lugar de la relación R>):
Una relación de orden estricto (en lugar de la relación R<):
Ambas tablas-relaciones obtienen una nueva (en este caso, la misma, ya que al introducir cabeceras adicionales hemos borrado las diferencias entre las relaciones R> y R<) título. Entonces, vemos que con la ayuda de un truco tan simple como agregar los encabezados necesarios a las tablas, llegamos al hecho de que las relaciones R> y R< llegar a ser equivalentes entre sí. Así, concluimos que el concepto de "relación" en el sentido general matemático y relacional no coincide completamente, no son idénticos. Actualmente, los sistemas de gestión de bases de datos relacionales constituyen la base del mercado de la tecnología de la información. Se están realizando más investigaciones en la dirección de combinar diversos grados del modelo relacional. Conferencia n.° 2. Datos faltantes Se describen dos tipos de valores en los sistemas de gestión de bases de datos para detectar datos faltantes: vacíos (o valores vacíos) e indefinidos (o valores nulos). En alguna literatura (en su mayoría comercial), los valores nulos a veces se denominan valores vacíos o nulos, pero esto es incorrecto. El significado de los significados vacío e indefinido es fundamentalmente diferente, por lo que es necesario monitorear cuidadosamente el contexto del uso de un término en particular. 1. Valores vacíos (Empty-values) valor vacío es simplemente uno de los muchos valores posibles para algún tipo de datos bien definido. Enumeramos los más "naturales", inmediatos valores vacíos (es decir, valores vacíos que podríamos asignar por nuestra cuenta sin tener ninguna información adicional): 1) 0 (cero): el valor nulo está vacío para los tipos de datos numéricos; 2) falso (incorrecto): es un valor vacío para un tipo de datos booleano; 3) B'' - cadena de bits vacía para cadenas de longitud variable; 4) "" - cadena vacía para cadenas de caracteres de longitud variable. En los casos anteriores, puede determinar si un valor es nulo o no comparando el valor existente con la constante nula definida para cada tipo de datos. Pero los sistemas de gestión de bases de datos, debido a los esquemas implementados en ellos para el almacenamiento de datos a largo plazo, solo pueden funcionar con cadenas de longitud constante. Debido a esto, una cadena de bits vacía puede llamarse una cadena de ceros binarios. O una cadena que consta de espacios o cualquier otro carácter de control es una cadena de caracteres vacía. Estos son algunos ejemplos de cadenas vacías de longitud constante: 1) B'0'; 2) B'000'; 3) ' '. ¿Cómo puede saber si una cadena está vacía en estos casos? En los sistemas de administración de bases de datos, se usa una función lógica para probar el vacío, es decir, el predicado EstáVacío(<expresión>), que literalmente significa "comer vacío". Este predicado suele estar integrado en el sistema de gestión de la base de datos y se puede aplicar a cualquier tipo de expresión. Si no existe tal predicado en los sistemas de administración de bases de datos, puede escribir una función lógica usted mismo e incluirla en la lista de objetos de la base de datos que se está diseñando. Considere otro ejemplo donde no es tan fácil determinar si tenemos un valor vacío. Datos del tipo de fecha. ¿Qué valor en este tipo debe considerarse un valor vacío si la fecha puede variar en el rango de 01.01.0100. antes del 31.12.9999/XNUMX/XNUMX? Para hacer esto, se introduce una designación especial en el DBMS para constantes de fecha vacías {...}, si el valor de este tipo se escribe: {DD. MM. AA} o {AA. MM. DD}. Con este valor, se produce una comparación al comprobar el valor de vacío. Se considera que es un valor bien definido, "completo" de una expresión de este tipo, y el más pequeño posible. Cuando se trabaja con bases de datos, los valores nulos a menudo se usan como valores predeterminados o se usan cuando faltan valores de expresión. 2. Valores indefinidos (Valores nulos) Palabra Nulo usado para denotar valores indefinidos en bases de datos. Para comprender mejor qué valores se entienden como indefinidos, considere una tabla que es un fragmento de una base de datos:
Por lo tanto, valor indefinido o Valor nulo - esto es: 1) desconocido, pero habitual, es decir, valor aplicable. Por ejemplo, el Sr. Khairetdinov, que es el número uno en nuestra base de datos, sin duda tiene algunos datos de pasaporte (como una persona nacida en 1980 y ciudadano del país), pero no se conocen, por lo tanto, no están incluidos en la base de datos. . Por lo tanto, el valor Nulo se escribirá en la columna correspondiente de la tabla; 2) valor no aplicable. El Sr. Karamazov (No. 2 en nuestra base de datos) simplemente no puede tener ningún dato de pasaporte, porque en el momento de la creación de esta base de datos o el ingreso de datos en ella, él era un niño; 3) el valor de cualquier celda de la tabla, si no podemos decir si es aplicable o no. Por ejemplo, el Sr. Kovalenko, que ocupa la tercera posición en nuestra base de datos, no sabe el año de nacimiento, por lo que no podemos decir con certeza si tiene o no datos de pasaporte. Y, en consecuencia, los valores de dos celdas en la línea dedicada al Sr. Kovalenko serán de valor nulo (el primero, como desconocido en general, el segundo, como un valor cuya naturaleza se desconoce). Como cualquier otro tipo de dato, los valores nulos también tienen ciertas propiedades. Enumeramos los más significativos de ellos: 1) con el tiempo, la comprensión del valor nulo puede cambiar. Por ejemplo, para el Sr. Karamazov (No. 2 en nuestra base de datos) en 2014, es decir, al alcanzar la mayoría de edad, el valor Nulo cambiará a un valor específico y bien definido; 2) Se puede asignar un valor nulo a una variable o constante de cualquier tipo (numérica, cadena, booleana, fecha, hora, etc.); 3) el resultado de cualquier operación en expresiones con valores nulos como operandos es un valor nulo; 4) una excepción a la regla anterior son las operaciones de conjunción y disyunción bajo las condiciones de las leyes de absorción (para más detalles sobre las leyes de absorción, ver el párrafo 4 de la lección No. 2). 3. Valores nulos y la regla general para evaluar expresiones Hablemos más sobre acciones en expresiones que contienen valores nulos. La regla general para tratar con valores Nulos (que el resultado de operaciones sobre valores Nulos sea un valor Nulo) se aplica a las siguientes operaciones: 1) a la aritmética; 2) a las operaciones de negación bit a bit, conjunción y disyunción (excepto las leyes de absorción); 3) a operaciones con cadenas (por ejemplo, concatenación - concatenación de cadenas); 4) a operaciones de comparación (<, ≤, ≠, ≥, >). Demos ejemplos. Como resultado de aplicar las siguientes operaciones se obtendrán valores Nulos: 3 + Nulo, 1/ Nulo, (Ivanov' + '' + Nulo) ≔ Nulo Aquí, en lugar de la igualdad habitual, usamos operación de sustitución "≔" debido a la naturaleza especial de trabajar con valores Nulos. A continuación, este carácter también se utilizará en situaciones similares, lo que significa que la expresión a la derecha del carácter comodín puede reemplazar cualquier expresión de la lista a la izquierda del carácter comodín. La naturaleza de los valores nulos a menudo da como resultado que algunas expresiones produzcan un valor nulo en lugar del nulo esperado, por ejemplo: (x - x), y * (x - x), x * 0 ≔ Nulo cuando x = Nulo. El caso es que al sustituir, por ejemplo, el valor x = Nulo en la expresión (x - x), obtenemos la expresión (Nulo - Nulo), y la regla general para calcular el valor de la expresión que contiene valores Nulos entra en vigor, y se pierde información sobre el hecho de que aquí el valor Nulo corresponde a la misma variable. Podemos concluir que al calcular cualquier operación que no sea lógica, los valores nulos se interpretan como inaplicabley, por lo tanto, el resultado también es un valor Nulo. El uso de valores Null en operaciones de comparación conduce a resultados no menos inesperados. Por ejemplo, las siguientes expresiones también producen valores nulos en lugar de los valores booleanos verdaderos o falsos esperados: (Nulo < Nulo); (Nulo ≤ nulo); (Nulo = Nulo); (Nulo ≠ Nulo); (Nulo > Nulo); (Nulo ≥ Nulo) ≔ Nulo; Por lo tanto, concluimos que es imposible decir que un valor Nulo es igual o no igual a sí mismo. Cada nueva aparición de un valor Nulo se trata como independiente, y cada vez que los valores Nulo se tratan como valores desconocidos diferentes. En esto, los valores nulos son fundamentalmente diferentes de todos los demás tipos de datos, porque sabemos que era seguro decir sobre todos los valores pasados anteriormente y sus tipos que son iguales o no iguales entre sí. Entonces, vemos que los valores nulos no son los valores de las variables en el sentido habitual de la palabra. Por lo tanto, se vuelve imposible comparar los valores de variables o expresiones que contienen valores Nulos, ya que como resultado no recibiremos los valores booleanos Verdadero o Falso, sino valores Nulos, como en los siguientes ejemplos: (x < nulo); (X ≤ nulo); (x=Nulo); (x ≠ Nulo); (x > Nulo); (x ≥ Nulo) ≔ Nulo; Por lo tanto, por analogía con los valores vacíos, para verificar una expresión para valores Nulos, debe usar un predicado especial: EsNulo(<expresión>), que literalmente significa "es nulo". La función booleana devuelve True si la expresión contiene Null o es igual a Null, y False en caso contrario, pero nunca devuelve Null. El predicado IsNull se puede aplicar a variables y expresiones de cualquier tipo. Cuando se aplica a expresiones de tipo vacío, el predicado siempre devolverá False. Por ejemplo:
Entonces, de hecho, vemos que en el primer caso, cuando el predicado IsNull se tomó de cero, la salida resultó ser Falsa. En todos los casos, incluidos el segundo y el tercero, cuando los argumentos de la función lógica resultaron ser iguales al valor Nulo, y en el cuarto caso, cuando el argumento mismo fue inicialmente igual al valor Nulo, el predicado devolvió Verdadero. 4. Valores nulos y operaciones lógicas Por lo general, solo se admiten directamente tres operaciones lógicas en los sistemas de administración de bases de datos: negación ¬, conjunción & y disyunción ∨. Las operaciones de sucesión ⇒ y equivalencia ⇔ se expresan en función de ellas mediante sustituciones: (x ⇒ y) ≔ (¬x ∨ y); (x ⇔ y) ≔ (x ⇒ y) & (y ⇒ x); Tenga en cuenta que estas sustituciones se conservan por completo cuando se utilizan valores nulos. Curiosamente, usando el operador de negación "¬" cualquiera de las operaciones conjunción & o disyunción ∨ puede expresarse una a través de la otra de la siguiente manera: (x & y) ≔¬ (¬x ∨¬y); (x ∨ y) ≔ ¬(¬x & ¬y); Estas sustituciones, así como las anteriores, no se ven afectadas por los valores nulos. Y ahora presentamos las tablas de verdad de las operaciones lógicas de negación, conjunción y disyunción, pero además de los valores habituales de Verdadero y Falso, también usamos el valor Nulo como operandos. Por conveniencia, introducimos la siguiente notación: en lugar de Verdadero, escribiremos t, en lugar de Falso - f, y en lugar de Nulo - n. 1. Negación XX.
Vale la pena señalar los siguientes puntos interesantes con respecto a la operación de negación usando valores nulos: 1) ¬¬x ≔ x - la ley de la doble negación; 2) ¬Nulo ≔ Nulo - El valor Nulo es un punto fijo. 2. Conjunción x e y.
Esta operación también tiene sus propias propiedades: 1) x & y ≔ y & x - conmutatividad; 2) x & x ≔ x - idempotencia; 3) Falso & y ≔ Falso, aquí Falso es un elemento absorbente; 4) True & y ≔ y, aquí True es el elemento neutro. 3. Disyunción x ∨ y.
características: 1) x ∨ y ≔ y ∨ x - conmutatividad; 2) x ∨ x ≔ x - idempotencia; 3) Falso ∨ y ≔ y, aquí Falso es el elemento neutro; 4) Verdadero ∨ y ≔ Verdadero, aquí Verdadero es un elemento absorbente. Una excepción a la regla general son las reglas para calcular las operaciones lógicas conjunción & y disyunción ∨ bajo las condiciones de acción leyes de absorción: (Falso & y) ≔ (x & Falso) ≔ Falso; (Verdadero ∨ y) ≔ (x ∨ Verdadero) ≔ Verdadero; Estas reglas adicionales están formuladas para que al reemplazar un valor Nulo con Falso o Verdadero, el resultado aún no dependa de este valor. Como se mostró anteriormente para otros tipos de operaciones, el uso de valores nulos en operaciones booleanas también puede generar valores inesperados. Por ejemplo, la lógica a primera vista se rompe en la ley de la exclusión del tercero (x ∨ ¬x) y la ley de la reflexividad (x = x), ya que para x ≔ Null tenemos: (x ∨ ¬x), (x = x) ≔ Nulo. ¡Las leyes no se cumplen! Esto se explica de la misma forma que antes: cuando se sustituye un valor Nulo en una expresión, se pierde la información de que ese valor lo reporta la misma variable, y entra en vigor la regla general para trabajar con valores Nulos. Así, concluimos: al realizar operaciones lógicas con valores Null como operando, estos valores son determinados por los sistemas de gestión de bases de datos como aplicable pero desconocido. 5. Comprobación de valores nulos y condiciones Entonces, de lo anterior, podemos concluir que en la lógica de los sistemas de gestión de bases de datos no hay dos valores lógicos (Verdadero y Falso), sino tres, porque el valor Nulo también se considera como uno de los posibles valores lógicos. Es por eso que a menudo se lo denomina valor desconocido, el valor desconocido. Sin embargo, a pesar de esto, solo se implementa la lógica de dos valores en los sistemas de administración de bases de datos. Por lo tanto, una condición con un valor Nulo (una condición indefinida) debe ser interpretada por la máquina como Verdadera o Falsa. De forma predeterminada, el lenguaje DBMS reconoce una condición con un valor Nulo como Falso. Ilustramos esto con los siguientes ejemplos de la implementación de declaraciones condicionales If y While en sistemas de gestión de bases de datos: Si P entonces A si no B; Esta entrada significa: si P se evalúa como Verdadero, entonces se realiza la acción A, y si P se evalúa como Falso o Nulo, entonces se realiza la acción B. Ahora aplicamos la operación de negación a este operador, obtenemos: Si ¬P entonces B si no A; A su vez, este operador significa lo siguiente: si ¬P se evalúa como Verdadero, entonces se realiza la acción B, y si ¬P se evalúa como Falso o Nulo, entonces se realizará la acción A. Y nuevamente, como podemos ver, cuando aparece un valor Nulo, nos encontramos con resultados inesperados. ¡El punto es que las dos declaraciones If en este ejemplo no son equivalentes! Aunque uno de ellos se obtiene del otro negando la condición y reordenando las ramas, es decir, por la operación estándar. ¡Tales operadores son generalmente equivalentes! Pero en nuestro ejemplo, vemos que el valor Nulo de la condición P en el primer caso corresponde al comando B, y en el segundo - A. Ahora considere la acción de la declaración condicional while: Mientras P hace A; B; ¿Cómo funciona este operador? Mientras P sea Verdadero, se ejecutará la acción A, y tan pronto como P sea Falso o Nulo, se ejecutará la acción B. Pero los valores nulos no siempre se interpretan como falsos. Por ejemplo, en las restricciones de integridad, las condiciones indefinidas se reconocen como verdaderas (las restricciones de integridad son condiciones que se imponen a los datos de entrada y garantizan su corrección). Esto se debe a que, en tales restricciones, solo se deben rechazar los datos deliberadamente falsos. Y de nuevo, en los sistemas de gestión de bases de datos, hay un especial función de sustitución IfNull(restricciones de integridad, True), con el que se pueden representar explícitamente valores nulos y condiciones indefinidas. Reescribamos las declaraciones condicionales If y While usando esta función: 1) If IfNull (P, False) entonces A else B; 2) Mientras que IfNull( P, False) haga A; B; Entonces, la función de sustitución IfNull(expresión 1, expresión 2) devuelve el valor de la primera expresión si no contiene un valor Nulo, y el valor de la segunda expresión en caso contrario. Cabe señalar que no se imponen restricciones sobre el tipo de la expresión devuelta por la función IfNull. Por lo tanto, al usar esta función, puede anular explícitamente cualquier regla para trabajar con valores nulos. Clase n.º 3. Objetos de datos relacionales 1. Requisitos para la forma tabular de representación de las relaciones 1. El primer requisito para la forma tabular de la representación de las relaciones es la finitud. Trabajar con infinitas tablas, relaciones o cualquier otra representación y organización de datos es inconveniente, rara vez justifica el esfuerzo realizado y, además, esta dirección tiene poca aplicación práctica. Pero además de esto, bastante esperado, existen otros requisitos. 2. El encabezado de la tabla que representa la relación debe constar necesariamente de una línea: el encabezado de las columnas y con nombres únicos. No se permiten encabezados de varios niveles. Por ejemplo, estos:
Todos los encabezados de varios niveles se reemplazan por encabezados de un solo nivel al seleccionar los encabezados apropiados. En nuestro ejemplo, la tabla después de las transformaciones especificadas se verá así:
Vemos que el nombre de cada columna es único, por lo que se pueden intercambiar como quieras, es decir, su orden se vuelve irrelevante. Y esto es muy importante porque es la tercera propiedad. 3. El orden de las líneas debe ser irrelevante. Sin embargo, este requisito tampoco es estrictamente restrictivo, ya que cualquier tabla puede reducirse fácilmente a la forma requerida. Por ejemplo, puede ingresar una columna adicional que determinará el orden de las filas. En este caso, nada cambiará por la permutación de las líneas. Aquí hay un ejemplo de una tabla de este tipo:
4. No debe haber filas duplicadas en la tabla que representa la relación. Si hay filas duplicadas en la tabla, esto se puede solucionar fácilmente introduciendo una columna adicional responsable del número de duplicados de cada fila, por ejemplo:
La siguiente propiedad también es bastante esperada, porque subyace a todos los principios de programación y diseño de bases de datos relacionales. 5. Los datos de todas las columnas deben ser del mismo tipo. Y además, deben ser de tipo simple. Expliquemos qué son los tipos de datos simples y complejos. Un tipo de dato simple es aquel cuyos valores de datos no son compuestos, es decir, no contienen partes constituyentes. Por lo tanto, ni las listas, ni las matrices, ni los árboles, ni los objetos compuestos similares deben estar presentes en las columnas de la tabla. Tales objetos son tipo de datos compuesto - en los sistemas de gestión de bases de datos relacionales, ellos mismos se presentan en forma de tablas-relaciones independientes. 2. Dominios y atributos Los dominios y atributos son conceptos básicos en la teoría de la creación y gestión de bases de datos. Expliquemos qué es. Formalmente, dominio de atributo (denotado por señor(a)), donde a es un atributo, se define como el conjunto de valores válidos del mismo tipo del atributo correspondiente a. Este tipo debe ser simple, es decir: dom(a) ⊆ {x | tipo(x) = tipo(a)}; Atributo (denotado a) se define a su vez como un par ordenado que consta del nombre de atributo name(a) y el dominio de atributo dom(a), es decir: a = (nombre(a): dom(a)); Esta definición usa ":" en lugar del habitual "," (como en las definiciones estándar de pares ordenados). Esto se hace para enfatizar la asociación del dominio del atributo y el tipo de datos del atributo. Estos son algunos ejemplos de diferentes atributos: а1 = (Curso: {1, 2, 3, 4, 5}); а2 = (MasaKg: {x | tipo(x) = real, x 0}); а3 = (LongitudSm: {x | tipo(x) = real, x 0}); Tenga en cuenta que los atributos a2 y un3 los dominios coinciden formalmente. Pero el significado semántico de estos atributos es diferente, porque comparar los valores de masa y longitud no tiene sentido. Por lo tanto, un dominio de atributo está asociado no solo con el tipo de valores válidos, sino también con un significado semántico. En la forma tabular de una relación, el atributo se muestra como un encabezado de columna en la tabla y el dominio del atributo no se especifica, pero está implícito. Se parece a esto:
Es fácil ver que aquí cada uno de los encabezados1,2,3 columnas de una tabla que representa una relación es un atributo separado. 3. Esquemas de relaciones. tuplas de valor con nombre En la teoría y práctica de DBMS, los conceptos de un esquema de relación y un valor con nombre de una tupla en un atributo son básicos. Vamos a traerlos. esquema de relación (denotado por S) se define como un conjunto finito de atributos con nombres únicos, es decir: S = {un | a ∈ S}; En cada tabla que representa una relación, todos los encabezados de columna (todos los atributos) se combinan en el esquema de la relación. El número de atributos en un esquema de relación determina степень lo relación y se denota como la cardinalidad del conjunto: |S|. Un esquema de relación puede estar asociado con un nombre de esquema de relación. En una forma tabular de representación de relaciones, como puede ver fácilmente, el esquema de relaciones no es más que una fila de encabezados de columnas.
S = {un1,2,3,4} - esquema de relación de esta tabla. El nombre de la relación se muestra como un encabezado esquemático de la tabla. En forma de texto, el esquema de relación se puede representar como una lista de nombres de atributos, por ejemplo: Estudiantes (número de libro de clase, apellido, nombre, patronímico, fecha de nacimiento). Aquí, como en la forma tabular, los dominios de los atributos no se especifican sino que están implícitos. De la definición se sigue que el esquema de una relación también puede estar vacío (S = ∅). Es cierto que esto es posible solo en teoría, ya que en la práctica el sistema de gestión de bases de datos nunca permitirá la creación de un esquema de relación vacío. Valor de tupla con nombre en el atributo (denotado por ejército de reserva)) se define por analogía con un atributo como un par ordenado que consta de un nombre de atributo y un valor de atributo, es decir: t(a) = (nombre(a) : x), x ∈ dom(a); Vemos que el valor del atributo se toma del dominio del atributo. En la forma tabular de una relación, cada valor con nombre de una tupla en un atributo es una celda de tabla correspondiente:
Aquí t(a1), t(un2), t(un3) - valores nombrados de tupla t en atributos a1Y2Y3. Los ejemplos más simples de valores de tupla con nombre en atributos: (Curso: 5), (Puntuación: 5); Aquí Course y Score son los nombres de dos atributos, respectivamente, y 5 es uno de sus valores tomado de sus dominios. Por supuesto, aunque estos valores son iguales en ambos casos, son semánticamente diferentes, ya que los conjuntos de estos valores en ambos casos difieren entre sí. 4. Tuplas. Tipos de tuplas El concepto de una tupla en los sistemas de gestión de bases de datos ya se puede encontrar intuitivamente en el punto anterior, cuando hablamos sobre el valor con nombre de una tupla en varios atributos. Asi que, cortejo (denotado por t, De inglés. tupla - "tupla") con el esquema de relación S se define como el conjunto de valores con nombre de esta tupla en todos los atributos incluidos en este esquema de relación S. En otras palabras, los atributos se toman de ámbito de una tupla, def(t), es decir.: t ≡ t(S) = {t(a) | a ∈ def(t) ⊆ S;. Es importante que no más de un valor de atributo corresponda a un nombre de atributo. En la forma tabular de la relación, una tupla será cualquier fila de la tabla, es decir:
Aquí t1(S) = {t(un1), t(un2), t(un3), t(un4)} y T2(S) = {t(un5), t(un6), t(un7), t(un8)} - tuplas. Las tuplas en el DBMS difieren en tipos dependiendo de su dominio de definición. Las tuplas se llaman: 1) parcial, si su dominio de definición está incluido o coincide con el esquema de la relación, es decir, def(t) ⊆ S. Este es un caso común en la práctica de bases de datos; 2) completar, en el caso de que su dominio de definición coincida completamente, es igual al esquema de relación, es decir def(t) = S; 3) incompleto, si el dominio de definición está completamente incluido en el esquema de relaciones, es decir, def(t) ⊂ S; 4) en ninguna parte definida, si su dominio de definición es igual al conjunto vacío, es decir, def(t) = ∅. Vamos a explicar con un ejemplo. Digamos que tenemos una relación dada por la siguiente tabla.
Deja aquí t1 = {10, 20, 30},t2 = {10, 20, nulo}, t3 = {Nulo, Nulo, Nulo}. Entonces es fácil ver que la tupla t1 - completa, ya que su dominio de definición es def(t1) = {a, b, c} = S. Tupla t2 - incompleto, def(t2) = { a, b} ⊂ S. Finalmente, la tupla t3 - no definido en ninguna parte, ya que su def(t3) = ∅. Cabe señalar que una tupla no definida en ninguna parte es un conjunto vacío, no obstante asociado con un esquema de relación. A veces, una tupla definida en ninguna parte se denota: ∅ (S). Como ya hemos visto en el ejemplo anterior, una tupla de este tipo es una fila de la tabla que consta solo de valores nulos. Curiosamente, la comparable, es decir, posiblemente iguales, son solo tuplas con el mismo esquema de relación. Por lo tanto, por ejemplo, dos tuplas no definidas en ninguna parte con diferentes esquemas de relación no serán iguales, como cabría esperar. Serán diferentes al igual que sus patrones de relación. 5. Relaciones. Tipos de relación Y finalmente, definamos la relación como una especie de punta de la pirámide, compuesta por todos los conceptos anteriores. Asi que, respeto (denotado por r, De inglés. relación) con el esquema de relación S se define como un conjunto necesariamente finito de tuplas que tienen el mismo esquema de relación S. Así: r ≡ r(S) = {t(S) | t∈r}; Por analogía con los esquemas de relación, el número de tuplas en una relación se llama relación de poder y denotada como la cardinalidad del conjunto: |r|. Las relaciones, como las tuplas, difieren en tipos. Entonces la relación se llama: 1) parcial, si se cumple la siguiente condición para cualquier tupla incluida en la relación: [def(t) ⊆ S]. Este es (como con las tuplas) el caso general; 2) completar, en caso de que ∀t ∈ r(S) tenemos [def(t) = S]; 3) incompleto, si ∃t ∈ r(S) def(t) ⊂ S; 4) en ninguna parte definida, si ∀t ∈ r(S) [def(t) = ∅]. Prestemos especial atención a las relaciones no definidas en ninguna parte. A diferencia de las tuplas, trabajar con este tipo de relaciones implica un poco de sutileza. El punto es que las relaciones definidas en ninguna parte pueden ser de dos tipos: pueden estar vacías o pueden contener una única tupla definida en ninguna parte (tales relaciones se denotan por {∅(S)}). comparable (por analogía con las tuplas), es decir, posiblemente iguales, son sólo relaciones con el mismo esquema de relación. Por lo tanto, las relaciones con diferentes esquemas de relación son diferentes. En forma tabular, una relación es el cuerpo de la tabla, a la que corresponde la línea, el encabezado de las columnas, es decir, literalmente, toda la tabla, junto con la primera fila que contiene los encabezados. Lección N° 4. Álgebra relacional. operaciones unarias Álgebra relacional, como puedes imaginar, es un tipo especial de álgebra en el que todas las operaciones se realizan en modelos de datos relacionales, es decir, en relaciones. En términos tabulares, una relación incluye filas, columnas y una fila, el encabezado de las columnas. Por lo tanto, las operaciones unarias naturales son operaciones de seleccionar ciertas filas o columnas, así como cambiar los encabezados de las columnas, cambiar el nombre de los atributos. 1. Operación de selección unaria La primera operación unaria que veremos es operación de búsqueda - la operación de seleccionar filas de una tabla que representa una relación, según algún principio, es decir, seleccionar filas-tuplas que satisfacen una determinada condición o condiciones. Operador de obtención denotado por σ , condición de muestreo - P , es decir, el operador σ siempre se toma con una determinada condición sobre las tuplas P, y la propia condición P se escribe según el esquema de la relación S. Teniendo en cuenta todo esto, la operación de búsqueda sobre el esquema de la relación S en relación a la relación r se verá así: σ r(S) ≡ σ r = {t(S) |t ∈ r & P t} = {t(S) |t ∈ r & IfNull(P t, False}; El resultado de esta operación será una nueva relación con el mismo esquema de relación S, formada por aquellas tuplas t(S) de la relación-operando original que satisfagan la condición de selección P t. Es claro que para aplicar algún tipo de condición a una tupla, es necesario sustituir los valores de los atributos de la tupla en lugar de los nombres de los atributos. Para comprender mejor cómo funciona esta operación, veamos un ejemplo. Sea dado el siguiente esquema de relación: S: Sesión (Nº de Libro de Notas, Apellidos, Materia, Grado). Tomemos la condición de selección de la siguiente manera: P = (Asunto = ‘Informática’ y Evaluación > 3). Necesitamos extraer de la relación-operando inicial aquellas tuplas que contengan información sobre los alumnos que aprobaron la asignatura "Informática" por al menos tres puntos. Sea también dada la siguiente tupla de esta relación: t0(S) ∈ r(S): {(Libro de calificaciones #: 100), (Apellido: 'Ivanov'), (Asunto: 'Bases de datos'), (Puntuación: 5)}; Aplicando nuestra condición de selección a la tupla t0obtenemos: Pt0 = ('Bases de datos' = 'Informática' y 5 > 3); En esta tupla en particular, no se cumple la condición de selección. En general, el resultado de esta muestra en particular σ<Materia = 'Informática' y Grado > 3 > Sesión habrá una tabla de "Sesión", en la que se dejan las filas que cumplen la condición de selección. 2. Operación de proyección unaria Otra operación unaria estándar que estudiaremos es la operación de proyección. Operación de proyección es la operación de seleccionar columnas de una tabla que representa una relación, según algún atributo. Es decir, la máquina elige esos atributos (es decir, literalmente esas columnas) de la relación de operandos original que se especificaron en la proyección. operador de proyección denotado por [S'] o π . Aquí S' es un subesquema del esquema original de la relación S, es decir, algunas de sus columnas. ¿Qué significa esto? Esto significa que S' tiene menos atributos que S, porque solo quedaron en S' aquellos atributos para los que se cumplió la condición de proyección. Y en la tabla que representa la relación r(S'), hay tantas filas como en la tabla r(S), y hay menos columnas, ya que solo quedan las correspondientes a los atributos restantes. Así, el operador de proyección π< S'> aplicado a la relación r(S) da como resultado una nueva relación con un esquema de relación diferente r(S' ), consistente en proyecciones t(S) [S' ] de tuplas de la relación original relación. ¿Cómo se definen estas proyecciones de tuplas? Proyeccion de cualquier tupla t(S) de la relación original r(S) con el subcircuito S' se determina mediante la siguiente fórmula: t(S) [S'] = {t(a)|a ∈ def(t) ∩ S'}, S' ⊆S. Es importante tener en cuenta que las tuplas duplicadas se excluyen del resultado, es decir, no habrá filas duplicadas en la tabla que representen la nueva. Con todo lo anterior en mente, una operación de proyección en términos de sistemas de gestión de bases de datos se vería así: π r(S) ≡ π r ≡ r(S) [S'] ≡ r [S' ] = {t(S) [S'] | t ∈ r}; Veamos un ejemplo que ilustra cómo funciona la operación de búsqueda. Deje que la relación "Sesión" y el esquema de esta relación sean dados: S: Sesión (número de libro de clase, Apellido, Materia, Grado); Nos interesarán solo dos atributos de este esquema, a saber, el "Libro de calificaciones #" y el "Apellido" del estudiante, por lo que el subesquema S se verá así: S': (Número de libro registro, Apellido). Es necesario proyectar la relación inicial r(S) sobre el subcircuito S'. A continuación, se nos dará una tupla t0(S) de la relación original: t0(S) ∈ r(S): {(Libro de calificaciones #: 100), (Apellido: 'Ivanov'), (Asunto: 'Bases de datos'), (Puntuación: 5)}; Por lo tanto, la proyección de esta tupla sobre el subcircuito dado S' se verá así: t0(S) S': {(Número de libro de cuentas: 100), (Apellido: 'Ivanov')}; Si hablamos de la operación de proyección en términos de tablas, entonces la proyección Sesión [número de libro de notas, Apellido] de la relación original es la tabla Sesión, de la que se eliminan todas las columnas, excepto dos: número de libro de notas y Apellido. Además, también se han eliminado todas las líneas duplicadas. 3. Operación de cambio de nombre unario Y la última operación unaria que veremos es operación de cambio de nombre de atributo. Si hablamos de la relación como una tabla, entonces se necesita la operación de cambio de nombre para cambiar los nombres de todas o algunas de las columnas. operador de cambio de nombre se ve así: ρ<φ>, aquí φ - renombrar función. Esta función establece una correspondencia biunívoca entre los nombres de atributos de esquema S y Ŝ, donde respectivamente S es el esquema de la relación original y Ŝ es el esquema de la relación con atributos renombrados. Así, el operador ρ<φ> aplicado a la relación r(S) da una nueva relación con el esquema Ŝ, que consta de tuplas de la relación original con solo atributos renombrados. Escribamos la operación de renombrar atributos en términos de sistemas de gestión de bases de datos: ρ<φ> r(S) ≡ ρ<φ>r = {ρ<φ> t(S)| t ∈ r}; Aquí hay un ejemplo del uso de esta operación: Consideremos la relación Sesión que ya nos es familiar, con el esquema: S: Sesión (número de libro de clase, Apellido, Materia, Grado); Introduzcamos un nuevo esquema de relación Ŝ, con diferentes nombres de atributos que nos gustaría ver en lugar de los existentes: Ŝ : (Nº ZK, Apellido, Asunto, Puntuación); Por ejemplo, un cliente de la base de datos quería ver otros nombres en su relación lista para usar. Para implementar este orden, debe diseñar la siguiente función de cambio de nombre: φ : (número de libro registro, Apellido, Materia, Grado) → (Nº ZK, Apellido, Materia, Calificación); De hecho, solo es necesario cambiar el nombre de dos atributos, por lo que es legal escribir la siguiente función de cambio de nombre en lugar de la actual: φ : (número de libro de registro, Grado) → (No. ZK, Puntuación); Además, dejemos que también se dé la tupla ya familiar que pertenece a la relación Sesión: t0(S) ∈ r(S): {(Libro de calificaciones #: 100), (Apellido: 'Ivanov'), (Asunto: 'Bases de datos'), (Puntuación: 5)}; Aplique el operador de cambio de nombre a esta tupla: ρ<φ>t0(S): {(ZK#: 100), (Apellido: 'Ivanov'), (Asunto: 'Bases de datos'), (Puntuación: 5)}; Entonces, esta es una de las tuplas de nuestra relación, cuyos atributos han sido renombrados. En términos tabulares, la relación ρ < Número del libro de calificaciones, Grado → "No. ZK, Puntuación > Sesión - esta es una nueva tabla obtenida de la tabla de relaciones "Sesión" al cambiar el nombre de los atributos especificados. 4. Propiedades de las operaciones unarias Las operaciones unarias, como cualquier otra, tienen ciertas propiedades. Consideremos el más importante de ellos. La primera propiedad de las operaciones unarias de selección, proyección y cambio de nombre es la propiedad que caracteriza la razón de las cardinalidades de las relaciones. (Recuérdese que la cardinalidad es el número de tuplas en una u otra relación.) Es claro que aquí estamos considerando, respectivamente, la relación inicial y la relación obtenida como resultado de aplicar una u otra operación. Tenga en cuenta que todas las propiedades de las operaciones unarias se derivan directamente de sus definiciones, por lo que pueden explicarse fácilmente e incluso, si se desea, deducirse de forma independiente. Por lo tanto: 1) relación de potencia: a) para la operación de selección: | σ r |≤ |r|; b) para la operación de proyección: | r[S'] | ≤ |r|; c) para la operación de cambio de nombre: | ρ<φ>r | = |r|; En total, vemos que para dos operadores, a saber, para el operador de selección y el operador de proyección, el poder de las relaciones originales - operandos es mayor que el poder de las relaciones obtenidas de los originales aplicando las operaciones correspondientes. Esto se debe a que la selección que acompaña a estas dos operaciones de selección y proyección excluye algunas filas o columnas que no cumplen las condiciones de selección. En el caso de que todas las filas o columnas cumplan las condiciones, no hay disminución de la potencia (es decir, el número de tuplas), por lo que la desigualdad en las fórmulas no es estricta. En el caso de la operación de renombrado, la potencia de la relación no cambia, debido a que al cambiar de nombre no se excluyen tuplas de la relación; 2) propiedad idempotente: a) para la operación de muestreo: σ σ r = σ ; b) para la operación de proyección: r [S'] [S'] = r [S']; c) para la operación de cambio de nombre, en el caso general, no se aplica la propiedad de idempotencia. Esta propiedad significa que aplicar el mismo operador dos veces seguidas a cualquier relación es equivalente a aplicarlo una vez. Para la operación de renombrar atributos de relación, en general, se puede aplicar esta propiedad, pero con reservas y condiciones especiales. La propiedad de idempotencia se usa muy a menudo para simplificar la forma de una expresión y llevarla a una forma más económica y real. Y la última propiedad que consideraremos es la propiedad de monotonicidad. Es interesante notar que bajo cualquier condición los tres operadores son monótonos; 3) propiedad de monotonicidad: a) para una operación de búsqueda: r1 ⊆ r2 ⇒σ r1 ⇒ σ r2; b) para la operación de proyección: r1 ⊆ r2 ⇒ r1[S'] ⊆ r2 [S']; c) para la operación de cambio de nombre: r1 ⊆ r2 ⇒ ρ<φ>r1 ⊆ ρ<φ>r2; El concepto de monotonicidad en el álgebra relacional es similar al mismo concepto del álgebra general ordinaria. Aclaremos: si inicialmente las relaciones r1 yr2 estaban relacionados entre sí de tal manera que r ⊆ r2, incluso después de aplicar cualquiera de los tres operadores de selección, proyección o cambio de nombre, esta relación se mantendrá. Lección N° 5. Álgebra relacional. Operaciones Binarias 1. Operaciones de unión, intersección, diferencia Cualquier operación tiene sus propias reglas de aplicabilidad que deben observarse para que las expresiones y acciones no pierdan su significado. Las operaciones binarias de teoría de conjuntos de unión, intersección y diferencia solo pueden aplicarse a dos relaciones necesariamente con el mismo esquema de relación. El resultado de tales operaciones binarias serán relaciones formadas por tuplas que satisfagan las condiciones de las operaciones, pero con el mismo esquema de relación que los operandos. 1. El resultado operaciones sindicales dos relaciones r1(S) y r2(S) habrá una nueva relación r3(S) que consta de aquellas tuplas de relaciones r1(S) y r2(S) que pertenecen a al menos una de las relaciones originales y con el mismo esquema de relación. Entonces la intersección de las dos relaciones es: r3(S) = r1(S) r2(S) = {t(S) | t∈r1 ∪t ∈r2}; Para mayor claridad, aquí hay un ejemplo en términos de tablas: Se dan dos relaciones: r1(S):
r2(S):
Vemos que los esquemas de la primera y segunda relaciones son iguales, solo que tienen diferente número de tuplas. La unión de estas dos relaciones será la relación r3(S), que corresponderá a la siguiente tabla: r3(S) = r1(S) r2(S):
Entonces, el esquema de la relación S no ha cambiado, solo ha aumentado el número de tuplas. 2. Pasemos a la consideración de la siguiente operación binaria: operaciones de intersección dos relaciones Como sabemos por la geometría escolar, la relación resultante incluirá solo aquellas tuplas de las relaciones originales que están presentes simultáneamente en ambas relaciones r1(S) y r2(S) (nuevamente, tenga en cuenta el mismo patrón de relación). La operación de la intersección de dos relaciones se verá así: r4(S) = r1(S)∩r2(S) = {t(S) | t ∈ r1 & t ∈ r2}; Y nuevamente, considere el efecto de esta operación en las relaciones presentadas en forma de tablas: r1(S):
r2(S):
Según la definición de la operación por intersección de relaciones r1(S) y r2(S) habrá una nueva relación r4(S), cuya vista de tabla se vería así: r4(S) = r1(S)∩r2(S):
En efecto, si nos fijamos en las tuplas de la primera y segunda relaciones iniciales, sólo hay una común entre ellas: {b, 2}. Se convirtió en la única tupla de la nueva relación r4(S) 3. Operación de diferencia dos relaciones se define de manera similar a las operaciones anteriores. Las relaciones de operandos, como en las operaciones anteriores, deben tener los mismos esquemas de relación, entonces la relación resultante incluirá todas aquellas tuplas de la primera relación que no estén en la segunda, es decir: r5(S) = r1(S)\r2(S) = {t(S) | t ∈ r1 & t ∉ r2}; Las ya conocidas relaciones r1(S) y r2(S), en una vista tabular con este aspecto: r1(S):
r2(S):
Consideraremos ambos operandos en la operación de intersección de dos relaciones. Entonces, siguiendo esta definición, la relación resultante r5(S) se verá así: r5(S) = r1(S)\r2(S):
Las operaciones binarias consideradas son básicas, otras operaciones, más complejas, se basan en ellas. 2. Producto cartesiano y operaciones de unión natural La operación de producto cartesiano y la operación de unión natural son operaciones binarias del tipo producto y se basan en la operación de unión de dos relaciones que discutimos anteriormente. Aunque la acción de la operación del producto cartesiano puede parecer familiar para muchos, comenzaremos con la operación del producto natural, ya que es un caso más general que la primera operación. Entonces, considere la operación de unión natural. Cabe señalar de inmediato que los operandos de esta acción pueden ser relaciones con diferentes esquemas, en contraste con las tres operaciones binarias de unión, intersección y cambio de nombre. Si consideramos dos relaciones con diferentes esquemas de relación r1(S1) y r2(S2), entonces su compuesto natural habrá una nueva relación r3(S3), que constará únicamente de aquellas tuplas de operandos que coincidan en la intersección de los esquemas de relación. En consecuencia, el esquema de la nueva relación será más grande que cualquiera de los esquemas de relaciones de los originales, ya que es su conexión, "pegado". Por cierto, las tuplas que son idénticas en dos relaciones de operandos, según las cuales se produce este "pegado", se denominan conectable. Escribamos la definición de la operación de unión natural en el lenguaje de fórmulas de los sistemas de gestión de bases de datos: r3(S3) = r1(S1)xr2(S2) = {t(S1 ∪S2) | t[S1] ∈r1 &t(S2) ∈r2}; Consideremos un ejemplo que ilustra bien el trabajo de una conexión natural, su "pegado". Sean dos relaciones r1(S1) y r2(S2), en la forma tabular de representación, respectivamente, igual: r1(S1):
r2(S2):
Vemos que estas relaciones tienen tuplas que coinciden en la intersección de los esquemas S1 y S2 relaciones. Vamos a enumerarlos: 1) tupla {a, 1} de relación r1(S1) coincide con la tupla {1, x} de la relación r2(S2); 2) tupla {b, 1} de r1(S1) también coincide con la tupla {1, x} de r2(S2); 3) la tupla {c, 3} coincide con la tupla {3, z}. Por lo tanto, bajo unión natural, la nueva relación r3(S3) se obtiene "pegando" exactamente estas tuplas. Así que r3(S3) en una vista de tabla se verá así: r3(S3) = r1(S1)xr2(S2):
Resulta por definición: esquema S3 no coincide con el esquema S1, ni con el esquema S2, "pegamos" los dos esquemas originales mediante la intersección de tuplas para obtener su unión natural. Mostremos esquemáticamente cómo se unen las tuplas al aplicar la operación de unión natural. Sea la relación r1 tiene una forma condicional:
y la razón r2 - vista:
Entonces su conexión natural se vería así:
Vemos que el "pegado" de relaciones-operandos ocurre de acuerdo con el mismo esquema que dimos anteriormente, considerando el ejemplo. operación conexión cartesiana es un caso especial de la operación de unión natural. Más específicamente, al considerar el efecto de la operación del producto cartesiano sobre las relaciones, estipulamos deliberadamente que en este caso solo podemos hablar de esquemas de relaciones que no se cruzan. Como resultado de aplicar ambas operaciones se obtienen relaciones con esquemas iguales a la unión de esquemas de relaciones de operandos, solo que todos los pares posibles de sus tuplas caen en el producto cartesiano de dos relaciones, ya que los esquemas de operandos en ningún caso deben cruzarse. Así, con base en lo anterior, escribimos una fórmula matemática para la operación del producto cartesiano: r4(S4) = r1(T1)xr2(S2) = {t(S1 ∪S2) | t[S1] ∈r1 &t(S2) ∈r2}, S1 ∩S2= ∅; Ahora veamos un ejemplo para mostrar cómo se verá el esquema de relación resultante al aplicar la operación de producto cartesiano. Sean dos relaciones r1(S1) y r2(S2), que se presentan en forma tabular de la siguiente manera: r1(S1):
r2(S2):
Entonces vemos que ninguna de las tuplas de relaciones r1(S1) y r2(S2), de hecho, no coincide en su intersección. Por lo tanto, en la relación resultante r4(S4) caerán todos los posibles pares de tuplas de la primera y segunda relación de operandos. Obtener: r4(S4) = r1(T1)xr2(S2):
Hemos obtenido un nuevo esquema de relación r4(S4) no por "pegado" de tuplas como en el caso anterior, sino por enumeración de todos los posibles pares diferentes de tuplas que no coinciden en la intersección de los esquemas originales. Nuevamente, como en el caso de la unión natural, damos un ejemplo esquemático de la operación del producto cartesiano. Sea r1 establecer de la siguiente manera:
y la razón r2 dado:
Entonces, su producto cartesiano se puede representar esquemáticamente de la siguiente manera:
Es de esta forma que se obtiene la relación resultante al aplicar la operación producto cartesiano. 3. Propiedades de las operaciones binarias De las definiciones anteriores de las operaciones binarias de unión, intersección, diferencia, producto cartesiano y unión natural, se siguen las propiedades. 1. La primera propiedad, como en el caso de las operaciones unarias, ilustra relación de poder relaciones: 1) para la operación de unión: |r1 ∪r2| ≤ |r1| + |r2|; 2) para la operación de intersección: |r1 ∩r2 | ≤ mín(|r1|, |r2|); 3) para la operación diferencia: |r1 \r2| ≤ |r1|; 4) para la operación del producto cartesiano: |r1 xr2| = |r1| |r2|; 5) para la operación de unión natural: |r1 xr2| ≤ |r1| |r2|. La razón de potencias, como recordamos, caracteriza cómo cambia el número de tuplas en las relaciones después de aplicar una u otra operación. Entonces ¿Qué vemos? Energía asociaciones dos relaciones r1 yr2 menor que la suma de las cardinalidades de las relaciones-operandos originales. ¿Por qué está pasando esto? La cosa es que cuando fusionas, las tuplas coincidentes desaparecen, superponiéndose entre sí. Entonces, refiriéndose al ejemplo que consideramos después de pasar por esta operación, puede ver que en la primera relación había dos tuplas, en la segunda - tres, y en la resultante - cuatro, es decir, menos de cinco (la suma de las cardinalidades de las relaciones-operandos). Por la tupla coincidente {b, 2}, estas relaciones están "pegadas". Potencia de resultado intersecciones dos relaciones es menor o igual que la cardinalidad mínima de las relaciones de operandos originales. Pasemos a la definición de esta operación: sólo aquellas tuplas que están presentes en ambas relaciones iniciales entran en la relación resultante. Esto significa que la cardinalidad de la nueva relación no puede exceder la cardinalidad de la relación-operando cuyo número de tuplas es el menor de los dos. Y la potencia del resultado puede ser igual a esta cardinalidad mínima, ya que siempre se admite el caso de que todas las tuplas de una relación de menor cardinalidad coincidan con algunas tuplas de la segunda relación-operando. En caso de operación diferencias todo es bastante trivial. De hecho, si todas las tuplas que también están presentes en la segunda relación se "sustraen" de la primera relación-operando, entonces su número (y, en consecuencia, su poder) disminuirá. En el caso de que ni una sola tupla de la primera relación coincida con ninguna tupla de la segunda relación, es decir, no hay nada que "restar", su poder no disminuirá. Curiosamente, si la operación producto cartesiano la potencia de la relación resultante es exactamente igual al producto de las potencias de las dos relaciones de operandos. Está claro que esto sucede porque todos los posibles pares de tuplas de las relaciones originales se escriben en el resultado y no se excluye nada. Y finalmente, la operación. conexión natural se obtiene una relación cuya cardinalidad es mayor o igual al producto de las cardinalidades de las dos relaciones originales. Nuevamente, esto sucede porque las relaciones de operandos están "pegadas" por tuplas coincidentes, y las que no coinciden se excluyen del resultado por completo. 2. Propiedad de idempotencia: 1) para la operación de unión: r ∪ r = r; 2) para la operación de intersección: r ∩ r = r; 3) para la operación diferencia: r \ r ≠ r; 4) para la operación del producto cartesiano (en el caso general, la propiedad no es aplicable); 5) para la operación de unión natural: r x r = r. Curiosamente, la propiedad de idempotencia no es cierta para todas las operaciones anteriores, y para la operación del producto cartesiano, no es aplicable en absoluto. De hecho, si combinas, cruzas o conectas naturalmente cualquier relación consigo misma, no cambiará. Pero si restas de una relación exactamente igual a ella, el resultado será una relación vacía. 3. Propiedad conmutativa: 1) para la operación de unión: r1 ∪r2 = r2 ∪r1; 2) para la operación de intersección: r ∩ r = r ∩ r; 3) para la operación diferencia: r1 \r2 ≠r2 \r1; 4) para la operación del producto cartesiano: r1 xr2 = r2 xr1; 5) para la operación de unión natural: r1 xr2 = r2 xr1. La propiedad de conmutatividad se cumple para todas las operaciones excepto para la operación diferencia. Esto es fácil de entender, porque su composición (tuplas) no cambia al reorganizar las relaciones en los lugares. Y al aplicar la operación diferencia, es importante cuál de las relaciones de operandos viene primero, porque depende de qué tuplas de qué relación se tomará como referencia, es decir, con qué tuplas se compararán otras tuplas para su exclusión. 4. Propiedad de asociatividad: 1) para la operación de unión: (r1 ∪r2)∪r3 = r1 ∪(r2 ∪r3); 2) para la operación de intersección: (r1 ∩r2)∩r3 = r1 ∩(r2 ∩r3); 3) para la operación diferencia: (r1 \r2)\r3 ≠r1 \(r2 \r3); 4) para la operación del producto cartesiano: (r1 xr2)xr3 = r1 x(r)2 xr3); 5) para la operación de unión natural: (r1 xr2)xr3 = r1 x(r)2 xr3). Y nuevamente vemos que la propiedad se ejecuta para todas las operaciones excepto para la operación de diferencia. Esto se explica de la misma forma que en el caso de aplicar la propiedad de conmutatividad. En general, a las operaciones de unión, intersección, diferencia y unión natural no les importa en qué orden se encuentran las relaciones entre operandos. Pero cuando las relaciones se "quitan" entre sí, el orden juega un papel dominante. Con base en las propiedades y el razonamiento anteriores, se puede sacar la siguiente conclusión: las tres últimas propiedades, a saber, la propiedad de idempotencia, conmutatividad y asociatividad, son verdaderas para todas las operaciones que hemos considerado, excepto para la operación de la diferencia de dos relaciones , para los cuales ninguna de las tres propiedades indicadas se cumplió en absoluto, y solo en un caso se encontró que la propiedad era inaplicable. 4. Opciones de operación de conexión Tomando como base las operaciones unarias de selección, proyección, renombrado y operaciones binarias de unión, intersección, diferencia, producto cartesiano y unión natural consideradas anteriormente (todas ellas denominadas generalmente operaciones de conexión), podemos introducir nuevas operaciones derivadas de los conceptos y definiciones anteriores. Esta actividad se llama compilar. unir opciones de operación. La primera variante de este tipo de operaciones de combinación es la operación conexión interna de acuerdo con la condición de conexión especificada. La operación de una reunión interna, por alguna condición específica, se define como una operación derivada de las operaciones del producto cartesiano y la selección. Escribimos la fórmula definición de esta operación: r1(S1) X P r2(S2) = σ (r1 xr2), Calle1 ∩S2 =∅; Aquí P = P<S1 ∪S2> - una condición impuesta a la unión de dos esquemas de las relaciones originales-operandos. Es por esta condición que las tuplas se seleccionan de las relaciones r1 yr2 en la relación resultante. Tenga en cuenta que la operación de unión interna se puede aplicar a relaciones con diferentes esquemas de relación. Estos esquemas pueden ser cualquiera, pero en ningún caso deben cruzarse. Las tuplas de los operandos-relación originales que son el resultado de la operación de unión interna se denominan tuplas unibles. Para ilustrar visualmente el funcionamiento de la operación de unión interna, daremos el siguiente ejemplo. Seamos dadas dos relaciones r1(S1) y r2(S2) con diferentes esquemas de relación: r1(S1):
r2(S2):
La siguiente tabla dará el resultado de aplicar la operación de unión interna sobre la condición P = (b1 = b2). r1(S1) X P r2(S2):
Entonces, vemos que el "pegado" de las dos tablas que representan la relación realmente sucedió precisamente para aquellas tuplas en las que se cumple la condición de la operación de unión interna P = (b1 = b2). Ahora, basándonos en la operación de unión interna ya presentada, podemos introducir la operación izquierda combinación externa и unión externa derecha. Vamos a explicar. El resultado de la operación combinación externa izquierda es el resultado de la combinación interna, completada con tuplas no combinables de la relación fuente izquierda-operando. De manera similar, el resultado de una operación de combinación externa derecha se define como el resultado de una operación de combinación interna aumentada con tuplas no combinables de la relación fuente-operando derecha. La pregunta de cómo se reponen las relaciones resultantes de las operaciones de las uniones externas izquierda y derecha es bastante esperada. Las tuplas de una relación-operando se complementan en el esquema de otra relación-operando Valores nulos. Vale la pena señalar que las operaciones de combinación externa izquierda y derecha introducidas de esta manera son operaciones derivadas de la operación de combinación interna. Para escribir las fórmulas generales para las operaciones de combinación externa izquierda y derecha, realizaremos algunas construcciones adicionales. Seamos dadas dos relaciones r1(S1) y r2(S2) con diferentes esquemas de relaciones S1 y S2, que no se cruzan entre sí. Como ya hemos estipulado que las operaciones de combinación interna izquierda y derecha son derivadas, podemos obtener las siguientes fórmulas auxiliares para determinar la operación de combinación externa izquierda: 1) r3 (S2 ∪S1) ≔r1(S1) X Pr2(S2); r 3 (S2 ∪S1) es simplemente el resultado de la unión interna de las relaciones r1(S1) y r2(S2). La combinación externa izquierda es una operación derivada de la combinación interna, por lo que comenzamos nuestras construcciones con ella; 2) r4(S1) ≔r 3(S2 ∪S1) [S1]; Así, con la ayuda de una operación de proyección unaria, hemos seleccionado todas las tuplas combinables de la relación-operando inicial izquierda r1(S1). El resultado se designa r4(S1) para facilitar su uso; 3) r5 (S1) ≔r1(S1)\r4(S1); Aquí r1(S1) son todas tuplas de la relación fuente izquierda-operando, y r4(S1) - sus propias tuplas, solo conectadas. Así, usando la operación binaria de la diferencia, con respecto a r5(S1) obtuvimos todas las tuplas no combinables de la relación del operando izquierdo; 4) r6(S2)≔{∅(S2)}; {∅(S2)} es una nueva relación con el esquema (S2) que contiene solo una tupla y está formado por valores nulos. Por conveniencia, denotamos esta relación como r6(S2); 5) r7 (S2 ∪S1) ≔r5(S1)xr6(S2); Aquí hemos tomado las tuplas no conectadas de la relación del operando izquierdo (r5(S1)) y los complementó sobre el esquema de la segunda relación-operando S2 Valores nulos, es decir, cartesiano multiplicó la relación que consiste en estas mismas tuplas no unibles por la relación r6(S2) definida en el apartado cuatro; 6) r1(S1) →x P r2(S2) ≔ (r1 x P r2)∪r7 (S2 ∪S1); Esto es izquierda combinación externa, obtenido, como puede verse, por la unión del producto cartesiano de las relaciones originales-operandos r1 yr2 y relaciones r7 (S2 ∪ S1) definido en el apartado XNUMX. Ahora tenemos todos los cálculos necesarios para determinar no solo la operación de la combinación externa izquierda, sino por analogía y para determinar la operación de la combinación externa derecha. Asi que: 1) operación izquierda combinación externa en forma estricta se ve así: r1(S1) →x P r2(S2) ≔ (r1 x P r2) ∪ [(r1 \(r1 x P r2) [S1]) x {∅(S2)}]; 2) operación unión externa derecha se define de manera similar a la operación de combinación externa izquierda y tiene la siguiente forma: r1(S1) →x P r2(S2) ≔ (r1 x P r2) ∪ [(r2 \(r1 x P r2) [S2]) x {∅(S1)}]; Estas dos operaciones derivadas tienen solo dos propiedades que vale la pena mencionar. 1. Propiedad de conmutatividad: 1) para la operación de combinación externa izquierda: r1(S1) →x P r2(S2) ≠r2(S2) →x P r1(S1); 2) para la operación de unión externa derecha: r1(S1) ←x P r2(S2) ≠r2(S2) ←x P r1(S1) Entonces, vemos que la propiedad de conmutatividad no se cumple para estas operaciones de forma general, pero al mismo tiempo, las operaciones de los enlaces externos izquierdo y derecho son mutuamente inversas entre sí, es decir, se cumple lo siguiente: 1) para la operación de combinación externa izquierda: r1(S1) →x P r2(S2) = r2(S2) →x P r1(S1); 2) para la operación de unión externa derecha: r1(S1) ←x P r2(S2) = r2(S2) ←x Pr1(S1). 2. La propiedad principal de las operaciones de combinación externa izquierda y derecha es que permiten restaurar la relación inicial-operando según el resultado final de una determinada operación de unión, es decir, se realizan: 1) para la operación de combinación externa izquierda: r1(S1) = (r1 →x P r2) [S1]; 2) para la operación de unión externa derecha: r2(S2) = (r1 ←x P r2) [S2]. Así, vemos que la primera relación-operando original puede restaurarse a partir del resultado de la operación de combinación izquierda-derecha, y más específicamente, aplicando al resultado de esta combinación (r1 xr2) la operación unaria de proyección sobre el esquema S1,[S1]. Y de manera similar, la segunda relación-operando original se puede restaurar aplicando la combinación externa derecha (r1 xr2) la operación unaria de proyección sobre el esquema de la relación S2. Demos un ejemplo para una consideración más detallada del funcionamiento de las operaciones de las uniones externas izquierda y derecha. Introduzcamos las ya conocidas relaciones r1(S1) y r2(S2) con diferentes esquemas de relación: r1(S1):
r2(S2):
Tupla no unible de relación izquierda-operando r2(S2) es una tupla {d, 4}. Siguiendo la definición, son ellos los que deben complementar el resultado de la conexión interna de las dos relaciones originales de operandos. Condición de unión interna de las relaciones r1(S1) y r2(S2) también dejamos lo mismo: P = (b1 = b2). Entonces el resultado de la operación. izquierda combinación externa quedará la siguiente tabla: r1(S1) →x P r2(S2):
De hecho, como podemos ver, como resultado del impacto de la operación de combinación externa izquierda, el resultado de la operación de combinación interna se repuso con tuplas no combinables de la izquierda, es decir, en nuestro caso, la primera relación- operando La reposición de la tupla en el esquema de la segunda fuente (derecha) relación-operando, por definición, sucedió con la ayuda de valores nulos. Y similar al resultado. unión externa derecha por lo mismo que antes, la condición P = (b1 = b2) de las relaciones originales-operandos r1(S1) y r2(S2) es la siguiente tabla: r1(S1) ←x P r2(S2):
En efecto, en este caso, el resultado de la operación de unión interna debe ser reabastecido con tuplas no unibles de la derecha, en nuestro caso, la segunda relación-operando inicial. Tal tupla, como no es difícil de ver, en la segunda relación r2(S2) uno, a saber, {2, y}. A continuación, actuamos sobre la definición de la operación de la combinación externa derecha, complementamos la tupla del primer operando (izquierdo) en el esquema del primer operando con valores nulos. Finalmente, veamos la tercera versión de las operaciones de combinación anteriores. Operación de unión externa completa. Esta operación puede considerarse no solo como una operación derivada de operaciones de combinación interna, sino también como una unión de operaciones de combinación externa izquierda y derecha. Operación de unión externa completa se define como el resultado de completar la misma combinación interna (como en el caso de la definición de combinaciones externas izquierda y derecha) con tuplas no combinables de las relaciones de operandos iniciales izquierda y derecha. Con base en esta definición, damos la forma de formulario de esta definición: r1(S1) ↔x P r2(S2) = (r1 →x P r2)∪(r1 ←x P r2); La operación de combinación externa completa también tiene una propiedad similar a la de las operaciones de combinación externa izquierda y derecha. Solo debido a la naturaleza recíproca original de la operación de unión externa completa (después de todo, se definió como la unión de las operaciones de unión externa izquierda y derecha), realiza propiedad de conmutatividad: r1(S1) ↔x P r2(S2)=r2(S2) ↔x P r1(S1); Y para completar la consideración de las opciones para las operaciones de combinación, veamos un ejemplo que ilustra el funcionamiento de una operación de combinación externa completa. Introducimos dos relaciones r1(S1) y r2(S2) y la condición de unión. Dejar r1(S1)
r2(S2):
Y sea la condición de conexión de las relaciones r1(S1) y r2(S2) será: P = (b1 = b2), como en los ejemplos anteriores. Entonces, el resultado de la operación de unión externa completa de las relaciones r1(S1) y r2(S2) por la condición P = (b1 = b2) se tendrá la siguiente tabla: r1(S1) ↔x P r2(S2):
Entonces, vemos que la operación de combinación externa completa justifica claramente su definición como la unión de los resultados de las operaciones de combinación externa izquierda y derecha. La relación resultante de la operación de unión interna se complementa con tuplas simultáneamente no unibles como la izquierda (primero, r1(S1)) y derecha (segundo, r2(S2)) de la relación-operando original. 5. Operaciones de derivados Por lo tanto, hemos considerado varias variantes de las operaciones de unión, a saber, las operaciones de unión interna, izquierda, derecha y unión externa completa, que son derivadas de las ocho operaciones originales del álgebra relacional: operaciones unarias de selección, proyección, cambio de nombre y operaciones binarias de unión, intersección, diferencia, producto cartesiano y conexión natural. Pero incluso entre estas operaciones originales hay ejemplos de operaciones derivadas. 1. Por ejemplo, operación intersecciones dos razones es una derivada de la operación de la diferencia de las mismas dos razones. Mostrémoslo. La operación de intersección se puede expresar mediante la siguiente fórmula: r1(S)∩r2(S) = r1 \r1 \r2 o, lo que da el mismo resultado: r1(S)∩r2(S) = r2 \r2 \r1; 2. Otro ejemplo, la derivada de la operación básica de las ocho operaciones originales es la operación conexión natural. En su forma más general, esta operación se deriva de la operación binaria del producto cartesiano y las operaciones unarias de selección, proyección y cambio de nombre de atributos. Sin embargo, a su vez, la operación de reunión interna es una operación derivada de la misma operación del producto cartesiano de relaciones. Por lo tanto, para mostrar que la operación de combinación natural es una operación derivada, considere el siguiente ejemplo. Comparemos los ejemplos anteriores de operaciones de combinación natural e interna. Seamos dadas dos relaciones r1(S1) y r2(S2) que actuarán como operandos. Son iguales: r1(S1):
r2(S2):
Como ya hemos recibido anteriormente, el resultado de la operación de unión natural de estas relaciones será una tabla de la siguiente forma: r3(S3) ≔r1(S1)xr2(S2):
Y el resultado de la reunión interna de las mismas relaciones r1(S1) y r2(S2) por la condición P = (b1 = b2) se tendrá la siguiente tabla: r4(S4) ≔r1(S1) X P r2(S2):
Comparemos estos dos resultados, las nuevas relaciones resultantes r3(S3) y r4(S4). Está claro que la operación de unión natural se expresa a través de la operación de unión interna, pero, lo que es más importante, con una condición de unión de una forma especial. Escribamos una fórmula matemática que describa la acción de la operación de unión natural como una derivada de la operación de unión interna. r1(S1)xr2(S2) = { ρ<ϕ1> r1 x E ρ< ϕ2>r2}[S1 ∪S2], donde E- condición de conectividad tuplas; mi= ∀a ∈S1 ∩S2 [EsNulo(b1) & EsNulo(2) ∪b1 = b2]; b1 = ϕ1 (nombre(a)), b2 = ϕ2 (nombra un)); Aquí está uno de funciones de cambio de nombre ϕ1 es idéntico, y otra función de cambio de nombre (a saber, ϕ2) cambia el nombre de los atributos donde se cruzan nuestros esquemas. La condición de conectividad E para tuplas se escribe en forma general, teniendo en cuenta la posible ocurrencia de valores nulos, porque la operación de unión interna (como se mencionó anteriormente) es una operación derivada de la operación del producto cartesiano de dos relaciones y la operación de selección unaria. 6. Expresiones del álgebra relacional Mostremos cómo las expresiones y operaciones del álgebra relacional consideradas anteriormente pueden usarse en la operación práctica de varias bases de datos. Pongamos, por ejemplo, que tenemos a nuestra disposición un fragmento de alguna base de datos comercial: Proveedores (Código de proveedor, Nombre del proveedor, Ciudad del proveedor); Instrumentos (Código de herramienta, Nombre de la herramienta,...); entregas (Código de proveedor, código de pieza); Los nombres de atributo subrayados[1] son atributos clave (es decir, identificativos), cada uno en su propia relación. Supongamos que a nosotros, como desarrolladores de esta base de datos y custodios de la información sobre este tema, se nos ordena obtener los nombres de los proveedores (Nombre del proveedor) y su ubicación (Ciudad del proveedor) en el caso de que estos proveedores no suministren ninguna herramienta con un nombre genérico "Alicates". Para determinar todos los proveedores que cumplen con este requisito en nuestra base de datos posiblemente muy grande, escribimos algunas expresiones de álgebra relacional. 1. Formamos una conexión natural de las relaciones "Proveedores" y "Suministros" para hacer coincidir con cada proveedor los códigos de las piezas suministradas por él. La nueva relación, el resultado de aplicar la operación de unión natural, para la conveniencia de una aplicación posterior, la denotamos por r1. Proveedores x Suministros ≔ r1 (Código del proveedor, Nombre del proveedor, Ciudad del proveedor, Entre paréntesis, hemos enumerado todos los atributos de las relaciones involucradas en esta operación de unión natural. Podemos ver que el atributo "Vendor ID" está duplicado, pero en el registro de resumen de la transacción, cada nombre de atributo debe aparecer solo una vez, es decir: Proveedores x Suministros ≔ r1 (Código del proveedor, Nombre del proveedor, Ciudad del proveedor, Código del instrumento); 2. Nuevamente formamos una conexión natural, solo que esta vez la relación obtenida en el párrafo uno y la relación Instrumentos. Hacemos esto para hacer coincidir el nombre de esta herramienta con cada código de herramienta obtenido en el párrafo anterior. r1 x Herramientas [Código de herramienta, Nombre de herramienta] ≔ r2 (Código del proveedor, Nombre del proveedor, Ciudad del proveedor, El resultado resultante se denotará por r2, se excluyen los atributos duplicados: r1 x Herramientas [Código de herramienta, Nombre de herramienta] ≔ r2 (Código del proveedor, Nombre del proveedor, Ciudad del proveedor, Código del instrumento, Nombre del instrumento); Tenga en cuenta que tomamos solo dos atributos de la relación Herramientas: "Código de herramienta" y "Nombre de herramienta". Para hacer esto, como se puede ver en la notación de la relación r2, aplicó la operación de proyección unaria: Herramientas [Código de la herramienta, Nombre de la herramienta], es decir, si la relación Herramientas se presentara como una tabla, el resultado de esta operación de proyección serían las dos primeras columnas con los encabezados "Código de la herramienta" y "Herramienta nombre "respectivamente". Es interesante notar que los primeros dos pasos que ya hemos considerado son bastante generales, es decir, pueden usarse para implementar cualquier otra solicitud. Pero los siguientes dos puntos, a su vez, representan pasos concretos para lograr la tarea específica que se nos presenta. 3. Escribir una operación de selección unaria según la condición <"Nombre de la herramienta" = "Pliers"> en relación con la relación r2obtenido en el párrafo anterior. Y nosotros, a su vez, aplicamos la operación de proyección unaria [Código del proveedor, Nombre del proveedor, Ciudad del proveedor] al resultado de esta operación para obtener todos los valores de estos atributos, porque necesitamos obtener esta información en función de la ordenar. Por lo tanto: (σ<Nombre de la herramienta = "Alicates"> r2) [Código del proveedor, Nombre del proveedor, Ciudad del proveedor] ≔ r3 (Código del proveedor, Nombre del proveedor, Ciudad del proveedor, Código de la herramienta, Nombre de la herramienta). En la relación resultante, denotada por r3, solo aquellos proveedores (con todos sus datos de identificación) resultaron suministrar herramientas con el nombre genérico "Pinzas". Pero en virtud de la orden, debemos señalar a aquellos proveedores que, por el contrario, no suministran dichas herramientas. Por lo tanto, pasemos al siguiente paso de nuestro algoritmo y escribamos la última expresión del álgebra relacional, que nos dará la información que estamos buscando. 4. Primero, hagamos la diferencia entre la razón "Proveedores" y la razón r3, y después de aplicar esta operación binaria, aplicamos la operación de proyección unaria sobre los atributos "Nombre del proveedor" y "Ciudad del proveedor". (Proveedores\r3) [Nombre del proveedor, Ciudad del proveedor] ≔ r4 (Código del proveedor, Nombre del proveedor, Ciudad del proveedor); El resultado se designa r4, esta relación incluía solo aquellas tuplas de la relación "Proveedores" original que corresponden a la condición de nuestro pedido. Entonces, hemos mostrado cómo, utilizando expresiones y operaciones de álgebra relacional, puede realizar todo tipo de acciones con bases de datos arbitrarias, realizar varias órdenes, etc. Lección No. 6. Lenguaje SQL Primero demos un poco de trasfondo histórico. El lenguaje SQL, diseñado para interactuar con bases de datos, apareció a mediados de la década de 1970. (las primeras publicaciones datan de 1974) y fue desarrollado por IBM como parte de un proyecto de sistema de gestión de base de datos relacional experimental. El nombre original del lenguaje es SEQUEL (Structured English Query Language) - solo refleja parcialmente la esencia de este lenguaje. Inicialmente, inmediatamente después de su invención y durante el período primario de funcionamiento del lenguaje SQL, su nombre era una abreviatura de la frase Lenguaje de consulta estructurado, que se traduce como "Lenguaje de consulta estructurado". Por supuesto, el lenguaje se centró principalmente en la formulación de consultas a bases de datos relacionales que sea conveniente y comprensible para los usuarios. Pero, de hecho, casi desde el principio, fue un lenguaje de base de datos completo que proporcionaba, además de los medios para formular consultas y manipular bases de datos, las siguientes características: 1) medios para definir y manipular el esquema de la base de datos; 2) medios para definir restricciones de integridad y activadores (que se mencionarán más adelante); 3) medios para definir vistas de bases de datos; 4) medios para definir estructuras de capa física que soporten la ejecución eficiente de solicitudes; 5) medios de autorización de acceso a las relaciones y sus campos. El lenguaje carecía de los medios para sincronizar explícitamente el acceso a los objetos de la base de datos desde el lado de las transacciones paralelas: desde el principio se supuso que el sistema de gestión de la base de datos realizaba implícitamente la sincronización necesaria. Actualmente, SQL ya no es una abreviatura, sino el nombre de un lenguaje independiente. Además, en la actualidad, el lenguaje de consulta estructurado se implementa en todos los sistemas comerciales de administración de bases de datos relacionales y en casi todos los DBMS que originalmente no se basaron en un enfoque relacional. Todas las empresas de fabricación afirman que su implementación se ajusta al estándar SQL y, de hecho, los dialectos implementados del lenguaje de consulta estructurado son muy parecidos. Esto no se logró de inmediato. Una característica de la mayoría de los sistemas de administración de bases de datos comerciales modernos que dificulta la comparación de los dialectos existentes de SQL es la falta de una descripción uniforme del lenguaje. Por lo general, la descripción se encuentra dispersa en varios manuales y se mezcla con una descripción de funciones de lenguaje específicas del sistema que no están directamente relacionadas con el lenguaje de consulta estructurado. No obstante, se puede decir que el conjunto básico de sentencias SQL, que incluye sentencias para determinar el esquema de la base de datos, obtener y manipular datos, autorizar el acceso a datos, soporte para incrustar SQL en lenguajes de programación y sentencias SQL dinámicas, está bien establecido en implementaciones comerciales y más o menos se ajusta al estándar. Con el tiempo y el trabajo en el lenguaje de consulta estructurado, ha sido posible lograr un estándar para una estandarización clara de la sintaxis y la semántica de las declaraciones de recuperación de datos, la manipulación de datos y la corrección de las restricciones de integridad de la base de datos. Se han especificado medios para definir las claves primaria y externa de las relaciones y las denominadas restricciones de verificación de integridad, que son un subconjunto de las restricciones de integridad de SQL verificadas inmediatamente. Las herramientas de definición de claves foráneas facilitan la formulación de los requisitos de la llamada integridad referencial de bases de datos (de la que hablaremos más adelante). Este requisito, común en las bases de datos relacionales, también podría formularse sobre la base del mecanismo general de las restricciones de integridad SQL, pero la formulación basada en el concepto de clave externa es más sencilla y comprensible. Entonces, teniendo en cuenta todo esto, en la actualidad, el lenguaje de consulta estructurado no es solo el nombre de un idioma, sino el nombre de toda una clase de lenguajes, ya que, a pesar de los estándares existentes, se implementan varios dialectos del lenguaje de consulta estructurado. en varios sistemas de gestión de bases de datos, que, por supuesto, tienen una base común. 1. La declaración Select es la declaración básica del lenguaje de consulta estructurado El lugar central en el lenguaje de consulta estructurado de SQL lo ocupa la instrucción Select, que implementa la operación más demandada cuando se trabaja con bases de datos: consultas. El operador Seleccionar evalúa expresiones de álgebra relacional y pseudo-relacional. En este curso, consideraremos la implementación de solo las operaciones unarias y binarias del álgebra relacional que ya hemos cubierto, así como la implementación de consultas usando las llamadas subconsultas. Por cierto, cabe señalar que en el caso de trabajar con operaciones de álgebra relacional pueden aparecer tuplas duplicadas en las relaciones resultantes. No existe una prohibición estricta contra la presencia de filas duplicadas en las relaciones en las reglas del lenguaje de consulta estructurado (a diferencia del álgebra relacional ordinaria), por lo que no es necesario excluir los duplicados del resultado. Entonces, veamos la estructura básica de la instrucción Select. Es bastante simple e incluye las siguientes frases estándar obligatorias: Seleccionar ... A partir del ... Dónde... ; En lugar de los puntos suspensivos en cada línea, debe haber relaciones, atributos y condiciones de una base de datos particular y tareas para ella. En el caso más general, la estructura básica de selección debería verse así: Seleccione seleccionar algunos atributos Desde de tal relación Dónde con tales y tales condiciones para el muestreo de tuplas Así, seleccionamos atributos del esquema de relaciones (encabezados de algunas columnas), al tiempo que indicamos a partir de qué relaciones (y, como podéis ver, puede haber varias) hacemos nuestra selección y, finalmente, en base a qué condiciones nos detenemos. nuestra elección en ciertas tuplas. Es importante notar que las referencias de atributos se hacen usando sus nombres. Así, se obtiene lo siguiente algoritmo de trabajo esta instrucción Select básica: 1) se recuerdan las condiciones para seleccionar tuplas de la relación; 2) se comprueba qué tuplas cumplen las propiedades especificadas. Tales tuplas se recuerdan; 3) se emiten los atributos enumerados en la primera línea de la estructura básica de la instrucción Select con sus valores. (Si hablamos de la forma tabular de la relación, entonces se mostrarán aquellas columnas de la tabla, cuyos encabezados se enumeraron como atributos necesarios; por supuesto, las columnas no se mostrarán por completo, en cada una de ellas solo esas tuplas que satisfizo las condiciones nombradas permanecerá.) Veamos un ejemplo. Sea dada la siguiente relación r1, como un fragmento de alguna base de datos de librería:
También se nos dará la siguiente expresión con la instrucción Select: Seleccione Título del libro, autor del libro Desde r1 Dónde Precio del libro > 200; El resultado de este operador será el siguiente fragmento de tupla: (Teléfono móvil, S. Rey). (En lo que sigue, consideraremos muchos ejemplos de implementaciones de consultas que usan esta estructura básica y estudiaremos su aplicación en gran detalle). 2. Operaciones unarias en el lenguaje de consulta estructurado En esta sección, consideraremos cómo las operaciones unarias ya familiares de selección, proyección y cambio de nombre se implementan en el lenguaje de consulta estructurado mediante el operador Seleccionar. Es importante tener en cuenta que si antes solo podíamos trabajar con operaciones individuales, incluso una sola instrucción Select en el caso general nos permite definir una expresión de álgebra relacional completa, y no solo una sola operación. Entonces, pasemos directamente al análisis de la representación de operaciones unarias en el lenguaje de consultas estructuradas. 1. Operación de muestreo. La operación de selección en SQL se implementa mediante la instrucción Select de la siguiente forma: Seleccione todos los atributos Desde nombre de la relación Dónde condición de selección; Aquí, en lugar de escribir "todos los atributos", puede usar el signo "*". En la teoría del lenguaje de consulta estructurado, este icono significa seleccionar todos los atributos del esquema de relación. La condición de selección aquí (y en todas las demás implementaciones de operaciones) se escribe como una expresión lógica con conectores estándar no (no), y (y), o (o). Se hace referencia a los atributos de relación por sus nombres. Considere un ejemplo. Definamos el siguiente esquema de relación: desempeño académico (Número de libro de calificaciones, Semestre, Código de materia, Valoración, Fecha); Aquí, como se mencionó anteriormente, los atributos subrayados forman la clave de relación. Compongamos una declaración Select de la siguiente forma, que implementa la operación de selección unaria: Seleccione * Del rendimiento académico Donde Gradebook # = 100 y Semestre = 6; Es claro que como resultado de esta declaración, la máquina mostrará el progreso de un estudiante con un registro número cien para el sexto semestre. 2. Operación de proyección. La operación de proyección en el lenguaje de consulta estructurado es incluso más fácil de implementar que la operación de búsqueda. Recuerde que al aplicar la operación de proyección, no se seleccionan filas (como al aplicar la operación de selección), sino columnas. Por lo tanto, basta con listar los encabezados de las columnas requeridas (es decir, nombres de atributos), sin especificar ninguna condición extraña. En total, obtenemos un operador de la siguiente forma: Seleccione lista de nombres de atributos Desde nombre de la relación; Después de aplicar esta instrucción, la máquina devolverá aquellas columnas de la tabla de relaciones cuyos nombres se especificaron en la primera línea de esta instrucción Select. Como mencionamos anteriormente, no es necesario excluir filas y columnas duplicadas de la relación resultante. Pero si en un pedido o en una tarea se requiere eliminar duplicados, debe usar una opción especial del lenguaje de consulta estructurado: distinto. Esta opción establece la eliminación automática de tuplas duplicadas de la relación. Con esta opción aplicada, la instrucción Select se verá así: Seleccione lista distinta de nombres de atributos Desde nombre de la relación; En SQL, existe una notación especial para los elementos opcionales de las expresiones: corchetes [...]. Por lo tanto, en su forma más general, la operación de proyección se verá así: Seleccione lista [distinta] de nombres de atributos Desde nombre de la relación; Sin embargo, si se garantiza que el resultado de aplicar la operación no contiene duplicados, o los duplicados aún son admisibles, entonces la opción distinto es mejor no especificar para no abarrotar el registro, es decir, por razones de desempeño del operador. Consideremos un ejemplo que ilustra la posibilidad de un XNUMX % de confianza en ausencia de duplicados. Sea dado el esquema de relaciones ya conocido por nosotros: desempeño académico (Número de libro de calificaciones, Semestre, Código de materia, Calificación, Fecha). Deje que se dé la siguiente instrucción Select: Seleccione Número de libro de calificaciones, Semestre, Código de materia Desde desempeño académico; Aquí, es fácil ver que los tres atributos devueltos por el operador forman la clave de la relación. Por eso la opción distinto se vuelve redundante, porque se garantiza que no habrá duplicados. Esto se deriva de un requisito sobre las claves llamado restricción única. Consideraremos esta propiedad con más detalle más adelante, pero si el atributo es clave, entonces no hay duplicados en él. 3. Cambiar el nombre de la operación. La operación de renombrar atributos en el lenguaje de consulta estructurado es bastante simple. Es decir, se materializa en la realidad mediante el siguiente algoritmo: 1) en la lista de nombres de atributos de la frase Select, se enumeran aquellos atributos que necesitan ser renombrados; 2) la palabra clave especial como se agrega a cada atributo especificado; 3) después de cada aparición de la palabra as, se indica el nombre del atributo correspondiente, al que es necesario cambiar el nombre original. Así, teniendo en cuenta todo lo anterior, el enunciado correspondiente a la operación de renombrado de atributos quedará así: Seleccione nombre de atributo 1 como nuevo nombre de atributo 1,... Desde nombre de la relación; Vamos a mostrar cómo funciona este operador con un ejemplo. Dejemos que se dé el esquema de relación que ya nos es familiar: desempeño académico (Número de libro de calificaciones, Semestre, Código de materia,Clasificación, Fecha); Tengamos una orden para cambiar los nombres de algunos atributos, a saber, en lugar de "Número de libro de cuenta" debería ser "Número de cuenta" y en lugar de "Puntuación" - "Puntuación". Escribamos cómo se verá la instrucción Select que implementa esta operación de cambio de nombre: Seleccione libro de registro como Número de registro, Semestre, Código de materia, Calificación como Puntaje, Fecha Desde desempeño académico; Por lo tanto, el resultado de aplicar este operador será un nuevo esquema de relación que difiere del esquema de relación "Logro" original en los nombres de dos atributos. 3. Operaciones binarias en el lenguaje de consultas estructuradas Al igual que las operaciones unarias, las operaciones binarias también tienen su propia implementación en el lenguaje de consulta estructurado o SQL. Entonces, consideremos la implementación en este lenguaje de las operaciones binarias que ya hemos pasado, a saber, las operaciones de unión, intersección, diferencia, producto cartesiano, unión natural, unión interna e izquierda, derecha, unión externa completa. 1. Operación sindical. Para implementar la operación de combinar dos relaciones, es necesario utilizar dos operadores Select simultáneamente, cada uno de los cuales corresponde a una de las relaciones-operandos originales. Y se debe aplicar una operación especial a estas dos instrucciones Select básicas Unión. Teniendo en cuenta todo lo anterior, escribamos cómo se verá la operación de unión usando la semántica del lenguaje de consulta estructurado: Seleccione enumerar los nombres de los atributos de la relación 1 Desde relación nombre 1 Unión Seleccione enumerar los nombres de los atributos de la relación 2 Desde relación nombre 2; Es importante tener en cuenta que las listas de nombres de atributos de las dos relaciones que se unen deben hacer referencia a atributos de tipos compatibles y enumerarse en un orden coherente. Si no se cumple con este requisito, su solicitud no se puede cumplir y la computadora mostrará un mensaje de error. Pero lo que es interesante notar es que los nombres de los atributos mismos en estas relaciones pueden ser diferentes. En este caso, a la relación resultante se le asignan los nombres de atributos especificados en la primera instrucción Select. También debe saber que el uso de la operación Unión excluye automáticamente todas las tuplas duplicadas de la relación resultante. Por lo tanto, si necesita conservar todas las filas duplicadas en el resultado final, en lugar de la operación Unión, debe usar una modificación de esta operación: la operación Union all. En este caso, la operación de combinar dos relaciones se verá así: Seleccione enumerar los nombres de los atributos de la relación 1 Desde relación nombre 1 Union all Seleccione enumerar los nombres de los atributos de la relación 2 Desde relación nombre 2; En este caso, las tuplas duplicadas no se eliminarán de la relación resultante. Usando la notación mencionada anteriormente para elementos opcionales y opciones en declaraciones Select, escribimos la forma más general de la operación de unir dos relaciones en el lenguaje de consulta estructurado: Seleccione enumerar los nombres de los atributos de la relación 1 Desde relación nombre 1 Unión [Todos] Seleccione enumerar los nombres de los atributos de la relación 2 Desde relación nombre 2; 2. Operación de intersección. La operación de intersección y la operación de diferencia de dos relaciones en el lenguaje de consulta estructurado se implementan de manera similar (consideramos el método de representación más simple, ya que cuanto más simple es el método, más económico, más relevante y, por lo tanto, más conveniente). en demanda). Entonces, analizaremos la forma de implementar la operación de intersección usando de llaves. Este método implica la participación de dos construcciones Select, pero no son iguales (como en la representación de la operación de unión), una de ellas es, por así decirlo, una "subconstrucción", "subciclo". Este operador suele llamarse subconsulta. Entonces, digamos que tenemos dos esquemas de relación (R1 y R2), definido aproximadamente como sigue: R1 (clave,...) y R2 (llave,...); A la hora de grabar esta operación, también utilizaremos la opción especial in, que literalmente significa "en" o (como en este caso particular) "contenido en". Entonces, teniendo en cuenta todo lo anterior, la operación de intersección de dos relaciones utilizando el lenguaje de consulta estructurado se escribirá de la siguiente manera: Seleccione * Desde R1 Dónde teclear (Seleccione ключ Desde R2); Así, vemos que la subconsulta en este caso será el operador entre paréntesis. Esta subconsulta en nuestro caso devuelve una lista de valores clave de la relación R2. Y, como se desprende de nuestra notación de operadores, del análisis de la condición de selección, solo aquellas tuplas de la relación R caerán en la relación resultante1, cuya clave está contenida en la lista de claves de la relación R2. Es decir, en la relación final, si recordamos la definición de intersección de dos relaciones, sólo quedarán aquellas tuplas que pertenecen a ambas relaciones. 3. Operación de diferencia. Como se mencionó anteriormente, la operación unaria de la diferencia de dos relaciones se implementa de manera similar a la operación de intersección. Aquí, además de la consulta principal con el operador Seleccionar, se utiliza una segunda consulta auxiliar, la llamada subconsulta. Pero a diferencia de la implementación de la operación anterior, al implementar la operación de diferencia, es necesario usar otra palabra clave, a saber no en, que en traducción literal significa "no en" o (como es apropiado traducir en nuestro caso bajo consideración) - "no está contenido en". Entonces, supongamos que, como en el ejemplo anterior, tenemos dos esquemas de relación (R1 y R2), aproximadamente dada por: R1 (clave,...) y R2 (llave,...); Como puede ver, los atributos clave se establecen nuevamente entre los atributos de estas relaciones. Por lo tanto, obtenemos el siguiente formulario para representar la operación de diferencia en el lenguaje de consulta estructurado: Seleccione * Desde R1 Dónde ключ no en (Seleccione ключ Desde R2); Así, sólo aquellas tuplas de la relación R1, cuya clave no está contenida en la lista de claves de la relación R2. Si consideramos la notación literalmente, entonces realmente resulta que de la relación R1 "restar" la relación R2. De aquí concluimos que la condición de selección en este operador está escrita correctamente (después de todo, se realiza la definición de la diferencia de dos relaciones) y el uso de claves, como en el caso de la implementación de la operación de intersección, está plenamente justificado. . Los dos usos del "método clave" que hemos visto son los más comunes. Con esto concluye el estudio del uso de claves en la construcción de operadores que representan relaciones. Todas las operaciones binarias restantes del álgebra relacional se escriben de otras formas. 4. Operación del producto cartesiano Como recordamos de las lecciones anteriores, el producto cartesiano de dos relaciones-operandos se compone de un conjunto de todos los pares posibles de valores con nombre de tuplas sobre atributos. Por lo tanto, en el lenguaje de consulta estructurado, la operación del producto cartesiano se implementa mediante una unión cruzada, denotada por la palabra clave unión cruzada, que literalmente se traduce como "unión cruzada" o "unión cruzada". Solo hay un operador Seleccionar en la estructura que representa la operación del producto cartesiano en el lenguaje de consulta estructurado y tiene la siguiente forma: Seleccione * Desde R1 unión cruzada R2 R Здесь1 y R2 - nombres de relaciones iniciales-operandos. Opción unión cruzada asegura que la relación resultante contendrá todos los atributos (todos, porque la primera línea del operador tiene el signo "*") correspondientes a todos los pares de tuplas de relación R1 y R2. Es muy importante recordar una característica de la implementación de la operación del producto cartesiano. Esta característica es consecuencia de la definición de la operación binaria del producto cartesiano. Recuérdalo: r4(S4) = r1(S1)xr2(S2) = {t(S1 ∪S2) | t[S1] ∈r1 &t(S2) ∈r2}, S1 ∩S2=∅; Como puede verse a partir de la definición anterior, los pares de tuplas se forman con esquemas de relación que necesariamente no se cruzan. Por lo tanto, cuando se trabaja en el lenguaje de consulta estructurado de SQL, se estipula invariablemente que las relaciones iniciales de los operandos no deben tener nombres de atributos coincidentes. Pero si estas relaciones aún tienen los mismos nombres, la situación actual se puede resolver fácilmente mediante la operación de cambio de nombre de atributo, es decir, en tales casos, solo necesita usar la opción as, que se mencionó anteriormente. Consideremos un ejemplo en el que necesitamos encontrar el producto cartesiano de dos relaciones que tienen algunos de los mismos nombres de atributos. Entonces, dadas las siguientes relaciones: R1 (A, B), R2 (ANTES DE CRISTO); Vemos que los atributos R1.B y R2.B tienen los mismos nombres. Con esto en mente, la instrucción Select que implementa esta operación de producto cartesiano en el lenguaje de consulta estructurado se verá así: Seleccione una, r1.B as B1,R2.B as B2,C Desde R1 unión cruzada R2; Por lo tanto, al usar la opción de renombrar como, la máquina no tendrá "preguntas" sobre los nombres coincidentes de las dos relaciones de operandos originales. 5. Operaciones de unión interna A primera vista, puede parecer extraño que consideremos la operación de unión interna antes que la operación de unión natural, porque cuando pasamos por las operaciones binarias, todo fue al revés. Pero al analizar la expresión de las operaciones en el lenguaje de consulta estructurado, se puede llegar a la conclusión de que la operación de combinación natural es un caso especial de la operación de combinación interna. Por eso es racional considerar estas operaciones en ese orden. Entonces, primero, recordemos la definición de la operación de unión interna que vimos anteriormente: r1(S1) X P r2(S2) = σ (r1 xr2), Calle1 ∩ S2 = ∅. Para nosotros, en esta definición, es especialmente importante que los esquemas considerados de relaciones-operandos S1 y S2 no debe cruzarse. Para implementar la operación de combinación interna en el lenguaje de consulta estructurado, hay una opción especial unión interna, que se traduce literalmente del inglés como "inner join" o "inner join". La instrucción Select en el caso de una operación de combinación interna se verá así: Seleccione * Desde R1 unión interna R2; Aquí, como antes, R1 y R2 - nombres de relaciones iniciales-operandos. Al implementar esta operación, no se debe permitir que se crucen los esquemas de relación-operandos. 6. Operación de unión natural Como ya hemos dicho, la operación de unión natural es un caso especial de la operación de unión interna. ¿Por qué? Sí, porque durante la acción de una unión natural, las tuplas de las relaciones de operandos originales se unen según una condición especial. Es decir, por la condición de igualdad de tuplas en la intersección de relaciones-operandos, mientras que con la acción de la operación unión interna, tal situación no podría permitirse. Dado que la operación de unión natural que estamos considerando es un caso especial de la operación de unión interna, para implementarla se utiliza la misma opción que para la operación anterior considerada, es decir, la opción unión interna. Pero dado que al compilar el operador Select para la operación de unión natural, también es necesario tener en cuenta la condición de igualdad de las tuplas de las relaciones de operandos originales en la intersección de sus esquemas, además de la opción indicada, la palabra clave Está aplicado on. Traducido del inglés, literalmente significa "sobre", y en relación con nuestro significado, se puede traducir como "sujeto a". La forma general de la instrucción Select para realizar una operación de unión natural es la siguiente: Seleccione * Desde relación nombre 1 unión interna relación nombre 2 on condición de igualdad de tuplas; Veamos un ejemplo. Se dan dos relaciones: R1 (A B C), R2 (B, C, D); La operación de unión natural de estas relaciones se puede implementar utilizando el siguiente operador: Seleccione una, r1.B,R1.CD Desde R1 unión interna R2 on R1.B=R2.B y R1.C=R2.C Como resultado de esta operación, los atributos especificados en la primera línea del operador Seleccionar, correspondientes a las tuplas iguales en la intersección especificada, se mostrarán en el resultado. Cabe señalar que aquí nos referimos a los atributos comunes B y C, no solo por su nombre. Esto debe hacerse no por la misma razón que en el caso de implementar la operación de producto cartesiano, sino porque de lo contrario no quedará claro a qué relación se refieren. Curiosamente, la redacción utilizada de la condición de unión (R1.B=R2.B y R1.C=R2.C) supone que los atributos compartidos de las relaciones de valor nulo unidas no están permitidos. Esto está integrado en el sistema de lenguaje de consulta estructurado desde el principio. 7. Operación de unión externa izquierda La expresión del lenguaje de consulta estructurado de SQL de la operación de unión externa izquierda se obtiene de la implementación de la operación de unión natural reemplazando la palabra clave interior por palabra clave exterior izquierdo. Así, en el lenguaje de consultas estructuradas, esta operación se escribirá de la siguiente manera: Seleccione * Desde relación nombre 1 unión exterior izquierda relación nombre 2 on condición de igualdad de tuplas; 8. Operación de combinación externa derecha La expresión para una operación de combinación externa derecha en lenguaje de consulta estructurado se obtiene realizando una operación de combinación natural reemplazando la palabra clave interior por palabra clave exterior derecho. Entonces, obtenemos que en el lenguaje de consulta estructurado SQL, la operación de la unión externa derecha se escribirá de la siguiente manera: Seleccione * Desde relación nombre 1 unión externa derecha relación nombre 2 on condición de igualdad de tuplas; 9. Operación de unión externa completa La expresión de Structured Query Language para una operación de combinación externa completa se obtiene, como en los dos casos anteriores, de la expresión para una operación de combinación natural reemplazando la palabra clave interior por palabra clave completo exterior. Así, en el lenguaje de consulta estructurado, esta operación se escribirá de la siguiente manera: Seleccione * Desde relación nombre 1 unión externa completa relación nombre 2 on condición de igualdad de tuplas; Es muy conveniente que estas opciones estén integradas en la semántica del lenguaje de consulta estructurado SQL, porque de lo contrario cada programador tendría que generarlas de forma independiente e ingresarlas en cada nueva base de datos. 4. Usando subconsultas Como se puede entender del material cubierto, el concepto de "subconsulta" en el lenguaje de consulta estructurado es un concepto básico y es bastante aplicable (a veces, por cierto, también se les llama consultas SQL. De hecho, la práctica de programación y trabajar con bases de datos muestra que compilar un sistema de subconsultas para resolver varias tareas relacionadas, una actividad que es mucho más gratificante en comparación con otros métodos de trabajo con información estructurada. Por lo tanto, consideremos un ejemplo para comprender mejor las acciones con subconsultas, su compilación y use. Sea el siguiente fragmento de una determinada base de datos, que se puede utilizar en cualquier institución educativa: Elementos (Código del objeto, Nombre del árticulo); Estudiantes (número de libro de registro, Nombre completo); Sesión (Código de materia, número del libro de calificaciones, Calificación); Formulemos una consulta SQL que devuelva una declaración que indique el número del libro de calificaciones, el apellido y las iniciales del estudiante, y la calificación de la materia denominada "Bases de datos". Las universidades necesitan recibir dicha información siempre y de manera oportuna, por lo que la siguiente consulta es quizás la unidad de programación más popular que utiliza tales bases de datos. Por conveniencia, supongamos además que los atributos "Apellido", "Nombre" y "Patronímico" no permiten valores nulos y no están vacíos. Este requisito es bastante comprensible y lógico, porque el primero de los datos para un nuevo estudiante que se ingresa en la base de datos de cualquier institución educativa es el de su apellido, nombre y patronímico. Y no hace falta decir que no puede haber una entrada en una base de datos de este tipo que contenga datos sobre un estudiante, pero al mismo tiempo se desconoce su nombre. Tenga en cuenta que el atributo "Nombre del elemento" del esquema de relación "Elementos" es una clave, por lo que, como se deduce de la definición (más sobre esto más adelante), todos los nombres de los elementos son únicos. Esto también es comprensible sin explicar la representación de la clave, porque todas las materias que se imparten en una institución educativa deben tener y tener nombres diferentes. Ahora, antes de comenzar a compilar el texto del operador mismo, presentaremos dos funciones que nos serán útiles a medida que avancemos. Primero, necesitaremos la función Trim, se escribe Trim ("cadena"), es decir, el argumento de esta función es una cadena. ¿Qué hace esta función? Devuelven el argumento en sí sin espacios al principio y al final de esta línea, es decir, esta función se usa, por ejemplo, en los casos: Trim ("Bogucharnikov") o Trim ("Maksimenko"), cuando los argumentos after o before son Vale la pena unos espacios extra. Y en segundo lugar, también es necesario considerar la función Izquierda, que se escribe Izquierda (cadena, número), es decir, una función de dos argumentos, uno de los cuales es, como antes, una cadena. Su segundo argumento es un número, indica cuántos caracteres del lado izquierdo de la cadena deben aparecer en el resultado. Por ejemplo, el resultado de la operación: Izquierda ("Mikhail, 1") + "." + Izquierda ("Zinovievich, 1") serán las iniciales "M. Z." Es para mostrar las iniciales de los alumnos que usaremos esta función en nuestra consulta. Entonces, comencemos a compilar la consulta deseada. Primero, hagamos una pequeña consulta auxiliar, que luego usaremos en la consulta principal principal: Seleccione Número del libro de calificaciones, Grado Desde Sesión Dónde Código del artículo = (Seleccione Código del objeto Desde Sujetos Dónde Nombre del elemento = "Bases de datos") as "Estimaciones" Bases de datos "; El uso de la opción as aquí significa que hemos creado un alias para esta consulta "Estimaciones de la base de datos". Hicimos esto por la conveniencia de seguir trabajando con esta solicitud. A continuación, en esta consulta, una subconsulta: Seleccione Código del objeto Desde Sujetos Dónde Nombre del elemento = "Bases de datos"; permite seleccionar de la relación "Sesión" aquellas tuplas que se relacionen con el tema en consideración, es decir, con bases de datos. Curiosamente, esta subconsulta interna solo puede devolver un valor, ya que el atributo "Nombre del elemento" es la clave de la relación "Elementos", es decir, todos sus valores son únicos. Y toda la consulta "Puntuaciones "Base de datos" le permite seleccionar de la relación "Sesión" datos sobre aquellos estudiantes (sus números de libro de calificaciones y calificaciones) que satisfacen la condición especificada en la subconsulta, es decir, información sobre el tema llamado "Base de datos". Ahora haremos la solicitud principal, utilizando los resultados ya recibidos. Seleccione Estudiantes. número de libro de registro, Trim (Apellido) + " " + Unidades (Nombre, 1) + "." + Unidades (Patronímico, 1) + "."as Nombre completo, Estimaciones "Bases de datos". Calificación Desde Estudiantes unión interna ( Seleccione Número del libro de calificaciones, Grado Desde Sesión Dónde Código del artículo = (Seleccione Código del objeto Desde Sujetos Dónde Nombre del elemento = "Bases de datos") ) como "Bases de datos de estimaciones". on Estudiantes. Libro de calificaciones # = calificaciones de la "base de datos". Número de libro de registro. Entonces, primero enumeramos los atributos que deberán mostrarse después de que se complete la consulta. Cabe mencionar que el atributo "Número de libro de calificaciones" es de la relación Estudiantes, de ahí - los atributos "Apellido", "Nombre" y "Patronímico". Es cierto que los dos últimos atributos no se deducen por completo, sino solo las primeras letras. También mencionamos el atributo 'Puntuación' de la consulta 'Puntuación de la base de datos' que ingresamos anteriormente. Seleccionamos todos estos atributos de la unión interna de la relación "Estudiantes" y la consulta "Calificaciones de la base de datos". Esta unión interna, como podemos ver, la tomamos bajo la condición de igualdad de los números del libro de registro. Como resultado de esta operación de combinación interna, las calificaciones se agregan a la relación Estudiantes. Cabe señalar que dado que los atributos "Apellido", "Nombre" y "Patronímico" por condición no permiten valores nulos y no están vacíos, la fórmula de cálculo que devuelve el atributo "Nombre" (Trim (Apellido) + " " + Unidades (Nombre, 1) + "." + Unidades (Patronímico, 1) + "."as Nombre completo), respectivamente, no requiere controles adicionales, se simplifica. Conferencia número 7. Relaciones básicas Como ya sabemos, las bases de datos son como una especie de contenedor, cuyo objetivo principal es almacenar datos presentados en forma de relaciones. Debe saber que, según su naturaleza y estructura, las relaciones se dividen en: 1) relaciones básicas; 2) relaciones virtuales. Las relaciones de vista base contienen solo datos independientes y no se pueden expresar en términos de ninguna otra relación de base de datos. En los sistemas comerciales de gestión de bases de datos, las relaciones básicas se suelen denominar simplemente como mesas en contraste con las representaciones correspondientes al concepto de relaciones virtuales. En este curso, consideraremos con cierto detalle solo las relaciones básicas, las técnicas principales y los principios para trabajar con ellas. 1. Tipos de datos básicos Los tipos de datos, como las relaciones, se dividen en basico и virtual. (Hablaremos de los tipos de datos virtuales un poco más adelante; dedicaremos un capítulo aparte a este tema). Tipos de datos básicos - estos son los tipos de datos que se definen inicialmente en los sistemas de gestión de bases de datos, es decir, están presentes allí de forma predeterminada (a diferencia de un tipo de datos definido por el usuario, que analizaremos inmediatamente después de pasar por el tipo de datos base). Antes de proceder a la consideración de los tipos de datos básicos reales, enumeramos qué tipos de datos hay en general: 1) datos numéricos; 2) datos lógicos; 3) cadena de datos; 4) datos que definen la fecha y la hora; 5) datos de identificación. De forma predeterminada, los sistemas de administración de bases de datos han introducido varios de los tipos de datos más comunes, cada uno de los cuales pertenece a uno de los tipos de datos enumerados. Llamémoslos. 1. En numérico se distingue el tipo de datos: 1) Número entero. Esta palabra clave generalmente denota un tipo de datos entero; 2) Real, correspondiente al tipo de dato real; 3) Decimales (n, m). Este es un tipo de datos decimal. Además, en la notación n es un número que fija el número total de dígitos del número, y m muestra cuántos caracteres de ellos hay después del punto decimal; 4) Dinero o moneda, introducido específicamente para la representación conveniente de datos del tipo de datos monetarios. 2. En lógico El tipo de datos generalmente asigna solo un tipo básico, esto es Lógico. 3. Cuerda el tipo de datos tiene cuatro tipos básicos (es decir, por supuesto, los más comunes): 1) Bit(n). Estas son cadenas de bits con longitud fija n; 2) Varbit(n). También son cadenas de bits, pero de longitud variable no superior a n bits; 3) Carácter(n). Estas son cadenas de caracteres con longitud constante n; 4) Varchar(n). Se trata de cadenas de caracteres, con una longitud variable que no supere los n caracteres. 4. Tipo fecha y hora incluye los siguientes tipos de datos básicos: 1) Fecha - tipo de datos de fecha; 2) Hora - tipo de dato que expresa la hora del día; 3) Fecha-hora es un tipo de datos que expresa tanto la fecha como la hora. 5. Identificación El tipo de datos contiene solo un tipo incluido de forma predeterminada en el sistema de administración de la base de datos, y ese es GUID (Identificador único global). Cabe señalar que todos los tipos de datos básicos pueden tener variantes de diferentes rangos de representación de datos. Para dar un ejemplo, las variantes del tipo de datos enteros de cuatro bytes pueden ser tipos de datos de ocho bytes (bigint) y dos bytes (smallint). Hablemos por separado sobre el tipo de datos GUID básico. Este tipo está destinado a almacenar valores de dieciséis bytes del llamado identificador único global. Todos los valores diferentes de este identificador se generan automáticamente cuando se llama a una función integrada especial NuevoId(). Esta designación proviene de la frase completa en inglés New Identification, que literalmente significa "nuevo valor de identificador". Cada valor de identificador generado en una computadora en particular es único dentro de todas las computadoras fabricadas. El identificador GUID se utiliza, en particular, para organizar la replicación de bases de datos, es decir, al crear copias de algunas bases de datos existentes. Dichos GUID pueden ser utilizados por desarrolladores de bases de datos junto con otros tipos básicos. Una posición intermedia entre el tipo GUID y otros tipos base está ocupada por otro tipo base especial: el tipo encimera. Se utiliza una palabra clave especial para designar datos de este tipo. Contador(x0, ∆x), que literalmente se traduce del inglés y significa "contador". Parámetro x0 establece el valor inicial, y Δx - paso de incremento. Los valores de este tipo de Contador son necesariamente números enteros. Cabe señalar que trabajar con este tipo de datos básicos incluye una serie de características muy interesantes. Por ejemplo, los valores de este tipo de contador no se establecen, como estamos acostumbrados cuando trabajamos con todos los demás tipos de datos, se generan a pedido, al igual que los valores del tipo de identificador único global. También es inusual que el tipo de contador solo se pueda especificar al definir la tabla, ¡y solo entonces! Este tipo no se puede utilizar en el código. También debe recordar que al definir una tabla, el tipo de contador solo se puede especificar para una columna. Los valores de los datos del contador se generan automáticamente cuando se insertan filas. Además, esta generación se realiza sin repetición, por lo que el contador siempre identificará de forma única cada línea. Pero esto crea algunos inconvenientes cuando se trabaja con tablas que contienen datos de contador. Si, por ejemplo, los datos en la relación dada por la tabla cambian y deben eliminarse o intercambiarse, los valores del contador pueden "confundir las tarjetas" fácilmente, especialmente si está trabajando un programador sin experiencia. Pongamos un ejemplo que ilustra tal situación. Sea dada la siguiente tabla que representa alguna relación, en la que se ingresan cuatro filas:
El contador le dio automáticamente a cada nueva línea un nombre único. Y ahora eliminemos la segunda y la cuarta línea de la tabla y luego agreguemos una línea adicional. Estas operaciones darán como resultado la siguiente transformación de la tabla de origen:
Por lo tanto, el contador eliminó las líneas segunda y cuarta junto con sus nombres únicos y no las "reasignó" a nuevas líneas, como cabría esperar. Además, el sistema de gestión de la base de datos nunca le permitirá cambiar el valor del contador manualmente, como tampoco le permitirá declarar varios contadores en una tabla al mismo tiempo. Normalmente, el contador se utiliza como sustituto, es decir, una clave artificial en la tabla. Es interesante saber que los valores únicos de un contador de cuatro bytes a una tasa de generación de un valor por segundo durarán más de 100 años. Veamos cómo se calcula: 1 año = 365 días * 24 h * 60 s * 60 s < 366 días * 24 h * 60 s * 60 s < 225 con. 1 segundo > 2-25 año 24*8 valores / 1 valor/segundo = 232 c > 27 año > 100 años. 2. Tipo de datos personalizado Un tipo de datos definido por el usuario se diferencia de todos los tipos básicos en que no se incorporó originalmente en el sistema de administración de la base de datos, no se declaró como un tipo de datos predeterminado. Este tipo puede ser creado por cualquier usuario y programador de base de datos de acuerdo con sus propias solicitudes y requisitos. Por tanto, un tipo de datos definido por el usuario es un subtipo de algún tipo base, es decir, es un tipo base con algunas restricciones en el conjunto de valores permitidos. En la notación de pseudocódigo, se crea un tipo de datos personalizado utilizando la siguiente declaración estándar: Crear subtipo nombre de subtipo Tipo de Propiedad nombre de tipo básico As restricción de subtipo; Entonces, en la primera línea, debemos especificar el nombre de nuestro nuevo tipo de datos definido por el usuario, en la segunda, cuál de los tipos de datos básicos existentes tomamos como modelo, creando el nuestro propio y, finalmente, en el tercero - aquellas restricciones que necesitamos agregar a las restricciones existentes en el conjunto de valores del tipo de datos base - muestra. Las restricciones de subtipo se escriben como una condición que depende del nombre del subtipo que se está definiendo. Para comprender mejor cómo funciona la instrucción Create, considere el siguiente ejemplo. Supongamos que necesitamos crear nuestro propio tipo de datos especializado, por ejemplo, para trabajar en el correo. Este será el tipo para trabajar con datos como números de código postal. Nuestros números se diferenciarán de los números decimales ordinarios de seis dígitos en que solo pueden ser positivos. Escribamos un operador para crear el subtipo que necesitamos: Crear subtipo Código postal Tipo de Propiedad decimal(6, 0) As Código postal > 0. ¿Por qué elegimos decimal (6, 0)? Recordando la forma usual del índice, vemos que tales números deben consistir en seis enteros de cero a nueve. Es por eso que tomamos el tipo decimal como el tipo de datos base. Es curioso notar que, en general, la condición impuesta sobre el tipo de datos base, es decir, la restricción de subtipo, puede contener los conectores lógicos not, and, or, y en general ser una expresión de cualquier complejidad arbitraria. Los subtipos de datos personalizados definidos de esta manera se pueden usar libremente junto con otros tipos de datos básicos tanto en el código del programa como al definir tipos de datos en las columnas de la tabla, es decir, los tipos de datos básicos y los tipos de datos de usuario son completamente iguales cuando se trabaja con ellos. En el entorno de desarrollo visual, aparecen en listas de tipos válidos junto con otros tipos de datos base. La probabilidad de que necesitemos un tipo de datos no documentado (definido por el usuario) al diseñar una nueva base de datos propia es bastante alta. De hecho, por defecto, solo los tipos de datos más comunes se integran en el sistema de gestión de la base de datos, adecuados, respectivamente, para resolver las tareas más comunes. Al compilar bases de datos de materias, es casi imposible hacerlo sin diseñar sus propios tipos de datos. Pero, curiosamente, con igual probabilidad, es posible que necesitemos eliminar el subtipo que creamos, para no abarrotar y complicar el código. Para ello, los sistemas de gestión de bases de datos suelen tener incorporado un operador especial. caer, que significa "quitar". La forma general de este operador para eliminar tipos personalizados innecesarios es la siguiente: Soltar subtipo el nombre del tipo personalizado; Los tipos de datos personalizados generalmente se recomiendan para los subtipos que son lo suficientemente generales. 3. Valores predeterminados Los sistemas de administración de bases de datos pueden tener la capacidad de crear valores predeterminados arbitrarios o, como también se les llama, valores predeterminados. Esta operación en cualquier entorno de programación tiene un peso bastante grande, ya que en casi cualquier tarea puede ser necesario introducir constantes, valores por defecto inmutables. Para crear un valor predeterminado en los sistemas de administración de bases de datos, se utiliza la función que ya nos es familiar al pasar un tipo de datos definido por el usuario Crear. Solo en el caso de crear un valor predeterminado, también se utiliza una palabra clave adicional tu préstamo estudiantil, que significa "predeterminado". En otras palabras, para crear un valor predeterminado en una base de datos existente, debe usar la siguiente declaración: Crear predeterminado nombre predeterminado As expresión constante; Está claro que en lugar de un valor constante al aplicar este operador, debe escribir el valor o expresión que queremos que sea el valor o expresión predeterminado. Y, por supuesto, debemos decidir con qué nombre nos conviene usarlo en nuestra base de datos y escribir este nombre en la primera línea del operador. Tenga en cuenta que, en este caso particular, esta instrucción Create sigue la sintaxis de Transact-SQL integrada en el sistema Microsoft SQL Server. Entonces, ¿qué tenemos? Hemos deducido que el valor predeterminado es una constante con nombre almacenada en bases de datos, al igual que su objeto. En el entorno de desarrollo visual, los valores predeterminados aparecen en la lista de valores predeterminados resaltados. Este es un ejemplo de cómo crear un valor predeterminado. Supongamos que para el correcto funcionamiento de nuestra base de datos es necesario que en ella funcione un valor con el significado de una vida ilimitada de algo. Luego debe ingresar en la lista de valores de esta base de datos el valor predeterminado que cumple con este requisito. Esto puede ser necesario, aunque solo sea porque cada vez que encuentre esta expresión bastante engorrosa en el texto del código, será extremadamente inconveniente volver a escribirla. Es por eso que usaremos la instrucción Crear anterior para crear un valor predeterminado, con el significado de una vida útil ilimitada de algo. Crear predeterminado "Sin límite de tiempo" As ‘9999-12-31 23: 59:59’ Aquí también se ha utilizado la sintaxis de Transact-SQL, según la cual los valores de las constantes de fecha y hora (en este caso, '9999-12-31 23:59:59') se escriben como cadenas de caracteres de una determinada dirección. La interpretación de las cadenas de caracteres como valores de fecha y hora está determinada por el contexto en el que se utilizan las cadenas. Por ejemplo, en nuestro caso particular, en la línea constante se escribe primero el valor límite del año y luego la hora. Sin embargo, a pesar de su utilidad, los valores predeterminados, como un tipo de datos definido por el usuario, a veces también pueden requerir que se eliminen. Los sistemas de gestión de bases de datos suelen tener un predicado incorporado especial, similar a un operador que elimina un tipo de datos más definido por el usuario que ya no se necesita. Este es un predicado Soltar y el operador en sí se ve así: Soltar predeterminado nombre predeterminado; 4. Atributos virtuales Todos los atributos en los sistemas de gestión de bases de datos se dividen (por absoluta analogía con las relaciones) en básicos y virtuales. así llamado atributos básicos son atributos almacenados que necesitan ser utilizados más de una vez, y por lo tanto, es recomendable guardar. Y a la vez, atributos virtuales no se almacenan, sino que se calculan los atributos. ¿Qué significa? Esto significa que los valores de los llamados atributos virtuales no se almacenan realmente, sino que se calculan sobre la marcha a través de los atributos base mediante fórmulas dadas. En este caso, los dominios de los atributos virtuales calculados se determinan automáticamente. Pongamos un ejemplo de una tabla que define una relación, en la que dos atributos son ordinarios, básicos, y el tercer atributo es virtual. Se calculará de acuerdo con una fórmula especialmente ingresada.
Entonces, vemos que los atributos "Peso Kg" y "Precio Rub por Kg" son atributos básicos, porque tienen valores ordinarios y están almacenados en nuestra base de datos. Pero el atributo "Costo" es un atributo virtual, porque está establecido por la fórmula de su cálculo y no se almacenará realmente en la base de datos. Es interesante notar que, debido a su naturaleza, los atributos virtuales no pueden tomar valores por defecto y, en general, el concepto mismo de un valor por defecto para un atributo virtual no tiene sentido y, por lo tanto, no es aplicable. Y también debe tener en cuenta que, aunque los dominios de los atributos virtuales se determinan automáticamente, el tipo de valores calculados a veces debe cambiarse del existente a algún otro. Para hacer esto, el lenguaje de los sistemas de administración de bases de datos tiene un predicado Convert especial, con la ayuda del cual se puede redefinir el tipo de la expresión calculada. Convert es la llamada función de conversión de tipo explícito. Está escrito de la siguiente manera: Convertir (tipo de dato, expresión); La expresión que es el segundo argumento de la función Convertir se calculará y generará como tales datos, cuyo tipo se indica mediante el primer argumento de la función. Considere un ejemplo. Supongamos que necesitamos calcular el valor de la expresión "2 * 2", pero necesitamos mostrar esto no como un número entero "4", sino como una cadena de caracteres. Para realizar esta tarea, escribimos la siguiente función Convert: Convertir (Carácter(1), 2 * 2). Por lo tanto, podemos ver que esta notación de la función Convertir dará exactamente el resultado que necesitamos. 5. El concepto de llaves Al declarar el esquema de una relación base, se pueden dar declaraciones de claves múltiples. Nos hemos encontrado con esto muchas veces antes. Finalmente, ha llegado el momento de hablar con más detalle sobre cuáles son las claves de relación, y no limitarse a frases generales y definiciones aproximadas. Entonces, demos una definición estricta de una clave de relación. Clave de esquema de relación es un subesquema del esquema original, que consta de uno o más atributos para los que se declara condición de unicidad valores en tuplas de relación. Para entender qué es la condición de unicidad, o, como también se le llama, restricción única, comencemos con la definición de una tupla y la operación unaria de proyectar una tupla en un subcircuito. Vamos a traerlos: t = t(S) = {t(a) | a ∈ def( t) ⊆ S} - definición de una tupla, t(S) [S' ] = {t(a) | a ∈ def (t) ∩ S'}, S' ⊆ S es la definición de la operación de proyección unaria; Está claro que la proyección de la tupla sobre el subesquema corresponde a una subcadena de la fila de la tabla. Entonces, ¿qué es exactamente una restricción de unicidad de atributo clave? La declaración de la clave K para el esquema de la relación S conduce a la formulación de la siguiente condición invariante, denominada, como ya hemos dicho, restricción de unicidad y denotado como: inversión < K → S > r(S): Inv < K → S > r(S) = ∀t1, t2 ∈ r(t 1[K]=t2 [K] → t 1(S) = t2(S)), K ⊆ S; Entonces, esta restricción de unicidad Inv < K → S > r(S) de la clave K significa que si dos tuplas cualesquiera t1 y t2pertenecientes a la relación r(S) son iguales en la proyección sobre la clave K, entonces esto implica necesariamente la igualdad de estas dos tuplas en la proyección sobre todo el esquema de la relación S. En otras palabras, todos los valores de la las tuplas que pertenecen a los atributos clave son únicas, únicas en su relación. Y el segundo requisito importante para una clave de relación es requisito de redundancia. ¿Qué significa? Este requisito significa que no se requiere que ningún subconjunto estricto de la clave sea único. En un nivel intuitivo, está claro que el atributo clave es ese atributo de relación que identifica de manera única y precisa cada tupla de la relación. Por ejemplo, en la siguiente relación dada por una tabla:
El atributo clave es el atributo "Libro de calificaciones #", porque diferentes estudiantes no pueden tener el mismo número de libro de calificaciones, es decir, este atributo está sujeto a una restricción única. Es interesante que en el esquema de cualquier relación puede ocurrir una variedad de claves. Enumeramos los principales tipos de llaves: 1) llave sencilla es una clave que consta de uno y no más atributos. Por ejemplo, en una hoja de examen de una materia en particular, una clave simple es el número de tarjeta de crédito, porque puede identificar de manera única a cualquier estudiante; 2) clave compuesta es una clave que consta de dos o más atributos. Por ejemplo, una clave compuesta en la lista de aulas es el número de edificio y el número de aula. Después de todo, no es posible identificar de manera única a cada audiencia con uno de estos atributos, y es bastante fácil hacerlo con su totalidad, es decir, con una clave compuesta; 3) súper clave es cualquier superconjunto de cualquier clave. Por tanto, el esquema de la relación misma es ciertamente una superclave. De esto podemos concluir que toda relación teóricamente tiene al menos una clave, y puede tener varias de ellas. Sin embargo, declarar una superclave en lugar de una clave normal es lógicamente ilegal, ya que implica relajar la restricción de unicidad aplicada automáticamente. Después de todo, la superclave, aunque tiene la propiedad de unicidad, no tiene la propiedad de no redundancia; 4) Clave primaria es simplemente la clave que se declaró primero cuando se definió la relación base. Es importante que se declare una y sólo una clave primaria. Además, los atributos de clave principal nunca pueden tomar valores nulos. Al crear una relación base en una entrada de pseudocódigo, la clave principal se denota clave principal y entre paréntesis el nombre del atributo, que es esta clave; 5) claves candidatas son todas las demás claves declaradas después de la clave principal. ¿Cuáles son las principales diferencias entre las claves candidatas y las claves primarias? Primero, puede haber varias claves candidatas, mientras que la clave principal, como se mencionó anteriormente, solo puede ser una. Y, en segundo lugar, si los atributos de la clave principal no pueden tomar valores Nulos, entonces esta condición no se impone a los atributos de las claves candidatas. En pseudocódigo, al definir una relación base, las claves candidatas se declaran usando las palabras llave candidata y entre paréntesis a continuación, como en el caso de declarar una clave primaria, se indica el nombre del atributo, que es la clave candidata dada; 6) clave externa es una clave declarada en una relación base que también se refiere a una clave primaria o candidata de la misma o alguna otra relación base. En este caso, la relación a la que se refiere la clave foránea se denomina referencia (o padre) actitud. Una relación que contiene una clave foránea se llama niño. En pseudocódigo, la clave foránea se denota como clave extranjera, entre paréntesis inmediatamente después de estas palabras, se indica el nombre del atributo de esta relación, que es una clave foránea, y luego se escribe la palabra clave referencias ("se refiere a") y especifique el nombre de la relación base y el nombre del atributo al que se refiere esta clave externa en particular. Además, al crear una relación base, para cada clave foránea, se escribe una condición, llamada restricción de integridad referencial, pero hablaremos de esto en detalle más adelante. Conferencia #8 El tema de esta lección será una discusión bastante detallada del operador de creación de relaciones de base. Analizaremos el operador en sí mismo en un registro de pseudocódigo, analizaremos todos sus componentes y su trabajo, y analizaremos los métodos de modificación, es decir, cambiar las relaciones básicas. 1. Símbolos metalingüísticos Al describir las construcciones sintácticas utilizadas para escribir el operador de creación de relaciones base en pseudocódigo, se utilizan varios métodos. símbolos metalingüísticos. Estos son todo tipo de paréntesis de apertura y cierre, varias combinaciones de puntos y comas, en una palabra, símbolos que cada uno tiene su propio significado y facilitan al programador la escritura del código. Presentemos y expliquemos el significado de los principales símbolos metalingüísticos que se utilizan con mayor frecuencia en el diseño de relaciones básicas. Asi que: 1) carácter metalingüístico "{}". Las construcciones sintácticas entre llaves son obligatorio unidades sintácticas. Al definir una relación base, los elementos requeridos son, por ejemplo, atributos base; sin declarar atributos base, no se puede diseñar ninguna relación. Por lo tanto, al escribir el operador de creación de relación base en pseudocódigo, los atributos base se enumeran entre llaves; 2) el símbolo metalingüístico "[]". En este caso, lo contrario es cierto: las construcciones de sintaxis entre corchetes representan opcional elementos de sintaxis. Las unidades sintácticas opcionales en el operador de creación de relación base, a su vez, son los atributos virtuales de las claves principal, candidata y foránea. Aquí, por supuesto, también hay sutilezas, pero hablaremos de ellas más adelante, cuando pasemos directamente al diseño del operador para crear la relación base; 3) símbolo metalingüístico "|". Este símbolo literalmente significa "o", como el símbolo análogo en matemáticas. El uso de este símbolo metalingüístico significa que hay que elegir entre dos o más construcciones separadas, respectivamente, por este símbolo; 4) símbolo metalingüístico "...". Una elipsis colocada inmediatamente después de cualquier unidad sintáctica significa la posibilidad repeticiones estos elementos sintácticos que preceden al símbolo metalingüístico; 5) símbolo metalingüístico ",..". Este símbolo significa casi lo mismo que el anterior. Solo cuando se utiliza el símbolo metalingüístico ",..", reiteración se producen construcciones sintácticas separado por comasque a menudo es mucho más conveniente. Con esto en mente, podemos hablar de la equivalencia de las siguientes dos construcciones sintácticas: unidad [, unidad]... и unidad,.. ; 2. Un ejemplo de creación de una relación básica en una entrada de pseudocódigo Ahora que hemos aclarado los significados de los principales símbolos metalingüísticos utilizados al escribir el operador de creación de relación base en pseudocódigo, podemos proceder a la consideración real de este operador en sí. Como puede entenderse a partir de las referencias anteriores, el operador para crear una relación base en la entrada de pseudocódigo incluye declaraciones de atributos base y virtuales, claves primarias, candidatas y foráneas. Además, como se mostrará y explicará anteriormente, este operador también cubre restricciones de valor de atributo y restricciones de tupla, así como las llamadas restricciones de integridad referencial. Las dos primeras restricciones, a saber, la restricción de valor de atributo y la restricción de tupla, se declaran después de la palabra reservada especial comprobar. Las restricciones de integridad referencial pueden ser de dos tipos: en actualización, que significa "al actualizar", y al borrar, que significa "en la eliminación". ¿Qué significa? Esto significa que al actualizar o eliminar atributos de relaciones a las que hace referencia una clave externa, se debe mantener la integridad del estado. (Hablaremos más sobre esto más adelante). El propio operador de creación de la relación base es utilizado por nosotros ya estudiado - el operador Crear, solo para crear una relación básica, se agrega la palabra clave mesa ("actitud"). Y, por supuesto, dado que la relación en sí es más grande e incluye todas las construcciones discutidas anteriormente, así como nuevas construcciones adicionales, el operador de creación será bastante impresionante. Entonces, escribamos en pseudocódigo la forma general del operador usado para crear relaciones básicas: Crear una tabla nombre de la relación base { nombre de atributo base tipo de valor de atributo base comprobar (límite de valor de atributo) {Nulo | no nulo} tu préstamo estudiantil (valor por defecto) },.. [nombre de atributo virtual as (fórmula de cálculo) ],.. [,comprobar (restricción de tupla)] [,clave principal (Nombre del Atributo,..)] [,llave candidata (Nombre del Atributo,..)]... [,clave extranjera (Nombre del Atributo,..) referencias nombre de relación de referencia (nombre de atributo,...) al actualizar { Restringir | Cascada | Establecer nulo} al eliminar { Restringir | Cascada | Establecer nulo} ] ... Así, vemos que se pueden declarar varios atributos básicos y virtuales, claves candidatas y foráneas, ya que tras las construcciones sintácticas correspondientes se encuentra un símbolo metalingüístico ",.." Después de la declaración de la clave principal, este símbolo no está presente, porque las relaciones de base, como se mencionó anteriormente, permiten solo una clave principal. A continuación, echemos un vistazo más de cerca al mecanismo de declaración. atributos básicos. Al describir cualquier atributo en el operador de creación de relación base, en el caso general, se especifica su nombre, tipo, restricciones en sus valores, bandera de validez de valores nulos y valores predeterminados. Es fácil ver que el tipo de un atributo y sus restricciones de valor determinan su dominio, es decir, literalmente, el conjunto de valores válidos para ese atributo en particular. Restricción de valor de atributo se escribe como una condición que depende del nombre del atributo. Aquí hay un pequeño ejemplo para que este material sea más fácil de entender: Crear una tabla nombre de la relación base Curso entero comprobar (1 <= Curso y Curso <= 5; Aquí, la condición "1 <= Encabezado y Encabezado <= 5" junto con la definición de un tipo de dato entero realmente condiciona completamente el conjunto de valores permitidos del atributo, es decir, literalmente, su dominio. La bandera de tolerancia de valores Null (Null | not Null) prohíbe (no Null) o, por el contrario, permite (Null) la aparición de valores Null entre los valores de los atributos. Tomando el ejemplo que acabamos de discutir, el mecanismo para aplicar indicadores de validez nula es el siguiente: Crear una tabla nombre de la relación base Curso entero comprobar (1 <= Curso y Curso <= 5); No nulo; Por lo tanto, el número de curso de un estudiante nunca puede ser nulo, no puede ser desconocido para los compiladores de la base de datos y no puede no existir. Valores predeterminados (tu préstamo estudiantil (valor predeterminado)) se utilizan al insertar una tupla en una relación si los valores de los atributos no se establecen explícitamente en la declaración de inserción. Es interesante señalar que los valores predeterminados también pueden ser valores nulos, siempre que los valores nulos para ese atributo en particular se declaren válidos. Ahora considere la definición atributo virtual en el operador de creación de relación base. Como dijimos anteriormente, establecer un atributo virtual consiste en establecer fórmulas para su cálculo a través de otros atributos base. Consideremos un ejemplo de declaración de un atributo virtual "Cost Rub". en forma de fórmula en función de los atributos básicos "Peso Kg" y "Precio Rub. por Kg". Crear una tabla nombre de la relación base Peso, kg base atributo valor tipo Peso Kg comprobar (restricción del valor del atributo Peso Kg) no nulo tu préstamo estudiantil (valor por defecto) Precio, frotar. por kg tipo de valor del atributo base Price Rub. por kg comprobar (limitación del valor del atributo Precio Rub. por Kg.) no nulo tu préstamo estudiantil (valor por defecto) ... Costo, frotar. as (Peso Kg * Precio Rub. por Kg) Un poco antes, analizamos las restricciones de atributos, que se escribieron como condiciones que dependen de los nombres de los atributos. Ahora considere el segundo tipo de restricciones declaradas al crear una relación base, a saber restricciones de tupla. ¿Qué es una restricción de tupla, en qué se diferencia de una restricción de atributo? Una restricción de tupla también se escribe como una condición que depende del nombre del atributo base, pero solo en el caso de una restricción de tupla, la condición puede depender de varios nombres de atributos al mismo tiempo. Considere un ejemplo que ilustra el mecanismo de trabajo con restricciones de tupla: Crear una tabla nombre de la relación base Peso mín. Kg. valor tipo de base atributo min Peso Kg comprobar (restricción del valor del atributo min Peso Kg) no nulo tu préstamo estudiantil (valor por defecto) Peso máx. kg valor tipo de base atributo max Peso Kg comprobar (restricción del valor del atributo max Peso Kg) no nulo tu préstamo estudiantil (valor por defecto) comprobar (0 < min Peso Kg y Peso mín. Kg < Peso máx. Kg); Por lo tanto, aplicar una restricción a una tupla equivale a sustituir los valores de la tupla por los nombres de los atributos. Pasemos a considerar el operador de creación de relación base. Una vez declarados, los atributos básicos y virtuales pueden declararse o no. Claves: primario, candidato y externo. Como dijimos anteriormente, un subesquema de una relación de base que en otra (o la misma) relación de base corresponde a una clave primaria o candidata en el contexto de la primera relación se denomina clave externa. Las claves foráneas representan mecanismo de enlace tuplas de unas relaciones sobre tuplas de otras relaciones, es decir, existen declaraciones de clave foránea asociadas a la imposición de las ya mencionadas denominadas restricciones de integridad referencial. (Esta restricción será el tema central de la próxima lección, ya que la integridad del estado (es decir, la integridad impuesta por las restricciones de integridad) es fundamental para el éxito de la relación base y de toda la base de datos). A su vez, declarar claves primarias y candidatas impone las restricciones de unicidad apropiadas en el esquema de relación base, que discutimos anteriormente. Y, por último, cabe decir sobre la posibilidad de borrar la relación base. A menudo, en la práctica del diseño de bases de datos, es necesario eliminar una relación antigua innecesaria para no saturar el código del programa. Esto se puede hacer usando el ya familiar operador Soltar. En su forma general completa, el operador de eliminación de relación base se ve así: Tabla de caída el nombre de la relación base; 3. Restricción de integridad por estado Restricción de integridad objeto de datos relacionales a partir de es el llamado invariante de datos. Al mismo tiempo, la integridad debe distinguirse con confianza de la seguridad, lo que, a su vez, implica la protección de los datos contra el acceso no autorizado a ellos con el fin de revelar, modificar o destruir datos. En general, las restricciones de integridad en los objetos de datos relacionales se clasifican por niveles de jerarquía estos mismos objetos de datos relacionales (la jerarquía de los objetos de datos relacionales es una secuencia de conceptos anidados: "atributo - tupla - relación - base de datos"). ¿Qué significa esto? Esto significa que las restricciones de integridad dependen de: 1) a nivel de atributo - a partir de valores de atributo; 2) a nivel de tupla: de los valores de la tupla, es decir, de los valores de varios atributos; 3) a nivel de relaciones - de una relación, es decir, de varias tuplas; 4) a nivel de base de datos - de varias relaciones. Entonces, ahora solo nos queda considerar con más detalle las restricciones de integridad sobre el estado de cada uno de los conceptos anteriores. Pero primero, demos los conceptos de soporte procesal y declarativo para las restricciones de integridad del estado. Por lo tanto, el soporte para las restricciones de integridad puede ser de dos tipos: 1) procesal, es decir, creado al escribir código de programa; 2) declarativo, es decir, creado al declarar ciertas restricciones para cada uno de los conceptos anidados anteriores. El soporte declarativo para las restricciones de integridad se implementa en el contexto de la instrucción Create para crear la relación base. Hablemos de esto con más detalle. Comencemos considerando el conjunto de restricciones desde la parte inferior de nuestra escalera jerárquica de objetos de datos relacionales, es decir, desde el concepto de atributo. Restricción de nivel de atributo incluye: 1) restricciones sobre el tipo de valores de atributo. Por ejemplo, una condición de número entero para valores, es decir, una condición de número entero para el atributo "Curso" de una de las relaciones base discutidas anteriormente; 2) una restricción de valor de atributo, escrita como una condición que depende del nombre del atributo. Por ejemplo, analizando la misma relación básica que en el párrafo anterior, vemos que en esa relación también existe una restricción a los valores de los atributos usando la opción comprobar, es decir.: comprobar (1 <= Curso y Curso <= 5); 3) La restricción a nivel de atributo incluye restricciones de valor nulo definidas por la conocida bandera de validez (nulo) o, por el contrario, inadmisibilidad (no nulo) de valores nulos. Como mencionamos anteriormente, las dos primeras restricciones definen la restricción de dominio del atributo, es decir, el valor de su conjunto de definición. Además, de acuerdo con la escalera jerárquica de los objetos de datos relacionales, debemos hablar de tuplas. Asi que, restricción de nivel de tupla se reduce a una restricción de tupla y se escribe como una condición que depende de los nombres de varios atributos básicos del esquema de relación, es decir, esta restricción de integridad de estado es mucho más pequeña y simple que la similar, solo corresponde al atributo. Y nuevamente, sería útil recordar el ejemplo de la relación básica que analizamos anteriormente, que tiene la restricción de tupla que necesitamos ahora, a saber: comprobar (0 < min Peso Kg y Peso mín. Kg < Peso máx. Kg); Y, finalmente, el último concepto significativo en el contexto de la restricción de integridad del estado es el concepto del nivel de relación. Como hemos dicho antes, restricción de nivel de relación incluye limitar los valores del primario (clave principal) y candidato (llave candidata) llaves. Es curioso que las restricciones impuestas a las bases de datos ya no son restricciones de integridad de estado, sino restricciones de integridad referencial. 4. Restricciones de integridad referencial Por lo tanto, la restricción de nivel de base de datos incluye la restricción de integridad referencial de clave externa (clave extranjera). Mencionamos esto brevemente cuando hablamos sobre las restricciones de integridad referencial al crear una relación base y claves externas. Ahora es el momento de hablar sobre este concepto con más detalle. Como dijimos antes, la clave foránea de la relación base declarada se refiere a la clave primaria o candidata de alguna otra relación base (la mayoría de las veces). Recuerde que en este caso, la relación a la que hace referencia la clave externa se llama referencia o de los padres, porque de alguna manera "genera" un atributo o múltiples atributos en la relación base de referencia. Y, a su vez, una relación que contiene una clave foránea se llama niño, también por razones obvias. Cuál es el restricción de integridad referencial? Y consiste en que cada valor de la clave foránea de la relación hijo debe corresponder necesariamente al valor de cualquier clave de la relación padre, a menos que el valor de la clave foránea contenga valores Nulos en algún atributo. Las tuplas de una relación hijo que violan esta condición se llaman colgando. De hecho, si la clave externa de la relación secundaria se refiere a un atributo que en realidad no existe en la relación principal, entonces no se refiere a nada. Son precisamente estas situaciones las que deben evitarse por todos los medios posibles, y eso significa mantener la integridad referencial. Pero, sabiendo que ninguna base de datos permitirá la creación de una tupla colgante, los desarrolladores se aseguran de que inicialmente no haya tuplas colgantes en la base de datos y que todas las claves disponibles se refieran a un atributo muy real de la relación principal. Sin embargo, hay situaciones en las que ya se forman tuplas colgantes durante el funcionamiento de la base de datos. ¿Cuáles son estas situaciones? Se sabe que cuando se eliminan tuplas de la relación principal o cuando se actualiza el valor clave de una tupla de la relación principal, se puede violar la integridad referencial, es decir, pueden ocurrir tuplas colgantes. Para excluir la posibilidad de que ocurran al declarar un valor de clave externa, se especifica uno de los siguientes: tres disponible normas manteniendo la integridad referencial, aplicada en consecuencia al actualizar el valor clave en la relación principal (es decir, como mencionamos anteriormente, en actualización) o al eliminar una tupla de la relación padre (al borrar). Cabe señalar que agregar una nueva tupla a la relación principal no puede romper la integridad referencial, por razones obvias. Después de todo, si esta tupla se agregara a la relación base, ¡ningún atributo podría referirse a ella antes debido a su ausencia! Entonces, ¿cuáles son estas tres reglas que se utilizan para mantener la integridad referencial en las bases de datos? Vamos a enumerarlos. 1. RestringirO regla de restricción. Si, al establecer nuestra relación base, al declarar claves foráneas en una restricción de integridad referencial, aplicamos esta regla de mantenerla, entonces no se puede actualizar una clave en la relación principal o eliminar una tupla de la relación principal si esta tupla es referenciado por al menos una tupla de la relación secundaria, es decir, operación Restringir prohibe trilladamente realizar cualquier acción que pueda dar lugar a la aparición de tuplas colgantes. Ilustramos la aplicación de esta regla con el siguiente ejemplo. Se dan dos relaciones: Actitud de los padres
relación infantil
Vemos que las tuplas de relación hija (2,...) y (2,...) se refieren a la tupla de relación padre (..., 2), y la tupla de relación hija (3,...) se refiere a la (..., 3) actitud paterna. La tupla (100,...) de la relación secundaria está pendiente y no es válida. Aquí, solo las tuplas de la relación principal (..., 1) y (..., 4) permiten actualizar los valores clave y eliminar las tuplas porque ninguna de las claves externas de la relación secundaria hace referencia a ellas. Compongamos el operador para crear una relación básica, que incluye la declaración de todas las claves anteriores: Crear una tabla Actitud de los padres Clave primaria Entero no nulo clave principal (Clave primaria) Crear una tabla relación infantil Clave externa Entero Nulo clave extranjera (Clave externa) referencias Relación principal (Primary_key) en actualización Restringir eliminar restringir 2. cascadaO regla de modificación en cascada. Si, al declarar claves foráneas en nuestra relación base, usáramos la regla de mantener la integridad referencial cascada, luego actualizar una clave en la relación principal o eliminar una tupla de la relación principal hace que las claves y tuplas correspondientes de la relación secundaria se actualicen o eliminen automáticamente. Veamos un ejemplo para comprender mejor cómo funciona la regla de modificación en cascada. Dejemos que se den las relaciones básicas que ya nos son familiares del ejemplo anterior: Actitud de los padres
и relación infantil
Supongamos que actualizamos algunas tuplas en la tabla que define la relación “Relación padre”, es decir, reemplazamos la tupla (..., 2) por la tupla (..., 20), es decir, obtenemos una nueva relación: Actitud de los padres
Y al mismo tiempo, en la declaración de creación de nuestra relación base "Relación secundaria" al declarar claves externas, usamos la regla de mantener la integridad referencial cascada, es decir, el operador para crear nuestra relación base se ve así: Crear una tabla Actitud de los padres Clave primaria Entero no nulo clave principal (Clave primaria) Crear una tabla relación infantil Clave externa Entero Nulo clave extranjera (Clave externa) referencias Relación principal (Primary_key) en actualización Cascada al eliminar Cascada Entonces, ¿qué sucede con la relación secundaria cuando la relación principal se actualiza de la manera descrita anteriormente? Tomará la siguiente forma: relación infantil
Así, en efecto, la regla cascada proporciona una actualización en cascada de todas las tuplas de la relación secundaria en respuesta a las actualizaciones de la relación principal. 3. Establecer nuloO regla de asignación nula. Si en la sentencia de creación de nuestra relación base, al declarar claves foráneas, aplicamos la regla de mantener la integridad referencial Establecer nulo, luego actualizar la clave de una relación principal o eliminar una tupla de una relación principal implica asignar automáticamente valores Nulos a aquellos atributos de clave externa de la relación secundaria que permiten valores Nulos. Por lo tanto, la regla es aplicable si tales atributos existen. Veamos un ejemplo que ya hemos usado antes. Supongamos que nos dan dos relaciones básicas: "Paternidad"
relación infantil
Como puede ver, los atributos de relaciones secundarias permiten valores nulos, de ahí la regla Establecer nulo aplicable en este caso particular. Supongamos ahora que la tupla (..., 1) se ha eliminado de la relación principal y la tupla (..., 2) se ha actualizado, como en el ejemplo anterior. Por tanto, la relación padre toma la siguiente forma: Actitud de los padres
Luego, teniendo en cuenta que al declarar las claves foráneas de la relación hijo, aplicamos la regla de mantener la integridad referencial Establecer nulo, la relación secundaria se verá así: relación infantil
La tupla (..., 1) no fue referenciada por ninguna clave de relación secundaria, por lo que eliminarla no tiene consecuencias. El propio operador de creación de relación base usando la regla Establecer nulo al declarar claves foráneas, la relación se ve así: Crear una tabla Actitud de los padres Clave primaria Entero no nulo clave principal (Clave primaria) Crear una tabla relación infantil Clave externa Entero Nulo clave extranjera (Clave externa) referencias Relación principal (Primary_key) en la actualización Establecer nulo al eliminar Establecer nulo Entonces, vemos que la presencia de tres reglas diferentes para mantener la integridad referencial asegura que en frases en actualización и al borrar las funciones pueden variar. Debe recordarse y entenderse que la inserción de tuplas en una relación secundaria o la actualización de los valores clave de las relaciones secundarias no se realizará si esto conduce a una violación de la integridad referencial, es decir, a la aparición de las llamadas tuplas colgantes. La eliminación de tuplas de una relación secundaria bajo ninguna circunstancia puede conducir a una violación de la integridad referencial. Es interesante que una relación hijo pueda actuar simultáneamente como padre con sus propias reglas para mantener la integridad referencial, si las claves foráneas de otras relaciones base se refieren a algunos de sus atributos como claves primarias. Si los programadores quieren asegurarse de que la integridad referencial sea aplicada por algunas reglas distintas a las reglas estándar anteriores, entonces el soporte de procedimiento para tales reglas no estándar para mantener la integridad referencial se proporciona con la ayuda de los llamados disparadores. Desafortunadamente, una consideración detallada de este concepto no desciende en nuestro curso de conferencias. 5. El concepto de índices La creación de claves en las relaciones base se vincula automáticamente a la creación de índices. Definamos la noción de índice. Índice - esta es una estructura de datos del sistema que contiene una lista necesariamente ordenada de valores de una clave con enlaces a aquellas tuplas de la relación en la que ocurren estos valores. Hay dos tipos de índices en los sistemas de gestión de bases de datos: 1) simple. Se toma un índice simple para un subesquema de esquema de la relación base de un solo atributo; 2) compuesto. En consecuencia, un índice compuesto es un índice para un subesquema que consta de varios atributos. Pero, además de dividirse en índices simples y compuestos, en los sistemas de gestión de bases de datos existe una división de índices en únicos y no únicos. Asi que: 1) unico Los índices son índices que se refieren a un atributo como máximo. Los índices únicos generalmente corresponden a la clave principal de la relación; 2) no único Los índices son índices que pueden coincidir con varios atributos al mismo tiempo. Las claves no únicas, a su vez, corresponden con mayor frecuencia a las claves foráneas de la relación. Considere un ejemplo que ilustra la división de índices en únicos y no únicos, es decir, considere las siguientes relaciones definidas por tablas:
Aquí, respectivamente, la clave principal es la clave principal de la relación, la clave externa es la clave externa. Es claro que en estas relaciones, el índice del atributo Clave primaria es único, ya que corresponde a la clave principal, es decir, un atributo, y el índice del atributo Clave externa no es único, ya que corresponde a la clave externa. llaves. Y su valor "20" corresponde tanto a la primera como a la tercera fila de la tabla de relaciones. Pero a veces se pueden crear índices sin tener en cuenta las claves. Esto se hace en los sistemas de gestión de bases de datos para respaldar el rendimiento de las operaciones de clasificación y búsqueda. Por ejemplo, una búsqueda dicotómica de un valor de índice en tuplas se implementará en los sistemas de gestión de bases de datos en veinte iteraciones. ¿De dónde proviene esta información? Se obtuvieron mediante cálculos simples, es decir, de la siguiente manera: 106 = (103)2 = 220; Los índices se crean en los sistemas de administración de bases de datos utilizando la instrucción Create que ya conocemos, pero solo con la adición de la palabra clave index. Tal operador se ve así: Crear índice nombre de índice On nombre de relación base (nombre de atributo, ..); Aquí vemos el familiar símbolo metalingüístico ",.." que denota la posibilidad de repetir un argumento separado por una coma, es decir, se puede crear un índice correspondiente a varios atributos en este operador. Si desea declarar un índice único, agregue la palabra clave única antes de la palabra índice y luego la declaración de creación completa en la relación del índice base se convierte en: Crear índice único nombre de índice On nombre de relación base (nombre de atributo); Entonces, en la forma más general, si recordamos la regla para designar elementos opcionales (el símbolo metalingüístico []), el operador de creación de índice en la relación básica se verá así: Crear índice [único] nombre de índice On nombre de relación base (nombre de atributo, ..); Si desea eliminar un índice ya existente de la relación base, use el operador Drop, también conocido por nosotros: Índice de caída {nombre de relación base. Nombre del índice},.. ; ¿Por qué se usa aquí el nombre de índice calificado "nombre de relación base. Nombre de índice"? Un operador de colocación de índice siempre usa su nombre calificado porque el nombre de índice debe ser único dentro de la misma relación, pero no más. 6. Modificación de las relaciones básicas Para poder trabajar con éxito y de manera productiva con varias relaciones base, muy a menudo los desarrolladores necesitan modificar esta relación base de alguna manera. ¿Cuáles son las principales opciones de modificación necesarias que se encuentran con más frecuencia en la práctica del diseño de bases de datos? Vamos a enumerarlos: 1) inserción de tuplas. Muy a menudo necesita insertar nuevas tuplas en una relación base ya formada; 2) actualizar los valores de los atributos. Y la necesidad de esta modificación en la práctica de la programación es aún más común que la anterior, porque cuando llega nueva información sobre los argumentos de tu base de datos, inevitablemente tendrás que actualizar alguna información antigua; 3) eliminación de tuplas. Y con aproximadamente la misma probabilidad, se hace necesario eliminar de la relación base aquellas tuplas cuya presencia en su base de datos ya no es necesaria debido a la nueva información recibida. Por lo tanto, hemos esbozado los puntos principales de la modificación de las relaciones básicas. ¿Cómo se puede lograr cada uno de estos objetivos? En los sistemas de administración de bases de datos, la mayoría de las veces hay operadores de modificación de relaciones básicos integrados. Vamos a describirlos en una entrada de pseudocódigo: 1) insertar operador en la relación base de las nuevas tuplas. este es el operador recuadro. Se parece a esto: Insertar en nombre de relación base (nombre de atributo, ..) Valores (valor de atributo,..); El símbolo metalingüístico ",.." después del nombre del atributo y el valor del atributo nos dice que este operador permite agregar múltiples atributos a la relación base al mismo tiempo. En este caso, debe enumerar los nombres de los atributos y los valores de los atributos, separados por comas, en un orden coherente. Ключевое слово dentro en combinación con el nombre general del operador recuadro significa "insertar en" e indica en qué relación deben insertarse los atributos entre paréntesis. Ключевое слово Valores en esta declaración, y significa "valores", "valores", que se asignan a estos atributos recién declarados; 2) ahora considere operador de actualización valores de atributo en la relación base. Este operador se llama Actualizar, que se traduce del inglés y significa literalmente "actualizar". Demos la forma general completa de este operador en una notación de pseudocódigo y descifrémoslo: Actualizar nombre de la relación base Set {nombre de atributo - valor de atributo},.. Dónde condición; Entonces, en la primera línea del operador después de la palabra clave Actualizar se escribe el nombre de la relación base en la que se van a realizar las actualizaciones. La palabra clave Set se traduce del inglés como "set", y esta línea de la declaración especifica los nombres de los atributos que se actualizarán y los valores de atributo nuevos correspondientes. Es posible actualizar varios atributos a la vez en una declaración, lo que se deriva del uso del símbolo metalingüístico ",..". En la tercera línea después de la palabra clave Dónde se escribe una condición que muestra exactamente qué atributos de esta relación base deben actualizarse; 3) operador Borrarpermitiendo remover cualquier tupla de la relación base. Escribamos su forma completa en pseudocódigo y expliquemos el significado de todas las unidades sintácticas individuales: Eliminar de nombre de la relación base Dónde condición; Ключевое слово en combinado con el nombre del operador Borrar se traduce como "quitar de". Y después de estas palabras clave en la primera línea del operador, se indica el nombre de la relación base, de la cual se deben eliminar las tuplas. Y en la segunda línea del operador después de la palabra clave Dónde ("donde") indica la condición por la cual se seleccionan las tuplas que ya no son necesarias en nuestra relación base. Conferencia número 9. Dependencias funcionales 1. Restricción de la dependencia funcional La restricción de unicidad impuesta por las declaraciones de clave primaria y candidata de una relación es un caso especial de la restricción asociada con la noción dependencias funcionales. Para explicar el concepto de dependencia funcional, considere el siguiente ejemplo. Tengamos una relación que contenga datos sobre los resultados de una sesión particular. El esquema de esta relación se ve así: Sesión (número de libro de registro, Nombre completo, Asunto, Calificación); Los atributos "Número de libro de calificaciones" y "Asunto" forman una clave primaria compuesta (ya que dos atributos se declaran como una clave) de esta relación. De hecho, estos dos atributos pueden determinar de forma única los valores de todos los demás atributos. Sin embargo, además de la restricción de unicidad asociada a esta clave, la relación debe necesariamente estar sujeta a la condición de que se emita un libro de calificaciones a una persona en particular y, por lo tanto, en este sentido, las tuplas con el mismo número de libro de calificaciones deben contener los mismos valores. de los atributos "Apellido", "Nombre y segundo nombre".
Si tenemos el siguiente fragmento de cierta base de datos de estudiantes de una institución educativa después de cierta sesión, entonces en tuplas con un número de libro de calificaciones de 100, los atributos "Apellido", "Nombre" y "Patronímico" son los mismos, y los atributos "Asunto" y "Evaluación" - no coinciden (lo cual es comprensible, porque están hablando de diferentes temas y desempeño en ellos). Esto significa que los atributos "Apellido", "Nombre" y "Patronímico" funcionalmente dependiente en el atributo "Número de libro de calificaciones", mientras que los atributos "Materia" y "Evaluación" son funcionalmente independientes. Por lo tanto, la dependencia funcional es una dependencia de un solo valor tabulada en los sistemas de administración de bases de datos. Damos ahora una definición rigurosa de dependencia funcional. Definición: sean X, Y subesquemas del esquema de la relación S, definiéndose sobre el esquema S diagrama de dependencia funcional X → Y (léase "X flecha Y"). definamos restricciones de dependencia funcional inv<X → Y> como una afirmación de que, en relación con el esquema S, dos tuplas cualesquiera que coincidan en proyección sobre el subesquema X también deben coincidir en proyección con el subesquema Y. Escribamos la misma definición en forma de fórmula: Facturación<X → Y> r(S) = t1, t2 ∈ r(t1[X] = t2[X] ⇒ t1[Y]=t2 [Y]), X, Y ⊆ S; Curiosamente, esta definición utiliza el concepto de una operación de proyección unaria, que encontramos anteriormente. De hecho, ¿de qué otra manera, si no usa esta operación, mostrar la igualdad de dos columnas de la tabla de relaciones, y no filas, entre sí? Por lo tanto, escribimos en términos de esta operación que la coincidencia de tuplas en la proyección sobre algún atributo o varios atributos (subesquema X) supondrá ciertamente la coincidencia de las mismas columnas-tuplas sobre el subesquema Y en el caso de que Y dependa funcionalmente de X. Es interesante notar que en el caso de una dependencia funcional de Y respecto a X, también se dice que X define funcionalmente Y o que Y funcionalmente dependiente en X. En el esquema de dependencia funcional X → Y, el subcircuito X se denomina lado izquierdo y el subcircuito Y se denomina lado derecho. En la práctica del diseño de bases de datos, el esquema de dependencia funcional se conoce comúnmente como dependencia funcional por brevedad. Fin de la definición. En un caso particular, cuando el lado derecho de la dependencia funcional, es decir, el subesquema Y, coincide con el esquema de relación completo, la restricción de dependencia funcional se convierte en una restricción de unicidad de clave primaria o candidata. En realidad: inversión r(S) = ∀ t1, t2 ∈ r(t1[K] = t2 [K] → t1(S) = t2(S)), K ⊆ S; Es solo que al definir una dependencia funcional, en lugar del subesquema X, debe tomar la designación de la clave K, y en lugar del lado derecho de la dependencia funcional, el subesquema Y, tomar el esquema completo de relaciones S, es decir, de hecho, la restricción sobre la unicidad de las claves de las relaciones es un caso especial de la restricción de la dependencia funcional cuando el lado derecho es igual a los esquemas de dependencia funcional en todo el esquema de relación. Aquí hay ejemplos de la imagen de la dependencia funcional: {Número de libro de cuentas} → {Apellido, Nombre, Patronímico}; {número de libro de calificaciones, materia} → {grado}; 2. Reglas de inferencia de Armstrong Si cualquier relación básica satisface dependencias funcionales definidas por vectores, entonces con la ayuda de varias reglas especiales de inferencia es posible obtener otras dependencias funcionales que esta relación básica ciertamente satisfará. Un buen ejemplo de tales reglas especiales son las reglas de inferencia de Armstrong. Pero antes de proceder al análisis de las propias reglas de inferencia de Armstrong, introduzcamos un nuevo símbolo metalingüístico "├", que se llama símbolo de metaafirmación de derivabilidad. Este símbolo, cuando se formulan reglas, se escribe entre dos expresiones sintácticas e indica que la fórmula a la derecha se deriva de la fórmula a la izquierda. Formulemos ahora las reglas de inferencia de Armstrong en la forma del siguiente teorema. Teorema. Las siguientes reglas son válidas, llamadas reglas de inferencia de Armstrong. Regla de inferencia 1. ├ X → X; Regla de inferencia 2. X → Y├ X ∪ Z → Y; Regla de inferencia 3. X → Y, Y ∪ W → Z ├ X ∪ W → Z; Aquí X, Y, Z, W son subesquemas arbitrarios del esquema de la relación S. El símbolo del metaenunciado de derivabilidad separa listas de premisas y listas de afirmaciones (conclusiones). 1. La primera regla de inferencia se llama "reflexividady dice lo siguiente: "la regla se deduce:" X implica funcionalmente a X "". Esta es la más simple de las reglas de derivación de Armstrong. Se deriva literalmente de la nada. Es interesante notar que una dependencia funcional que tiene partes izquierda y derecha se llama reflexivo. De acuerdo con la regla de reflexividad, la restricción de dependencia reflexiva se realiza automáticamente. 2. La segunda regla de inferencia se llama "reposición" y dice lo siguiente: "si X determina funcionalmente a Y, entonces se deriva la regla: "la unión de los subcircuitos X y Z implica funcionalmente a Y". La regla de finalización le permite expandir el lado izquierdo de la restricción de dependencia funcional. 3. La tercera regla de inferencia se llama "pseudotransitividad" y queda así: "si el subcircuito X implica funcionalmente al subcircuito Y, y la unión de los subcircuitos Y y W implica funcionalmente a Z, entonces se deriva la regla: "la unión de los subcircuitos X y W determina funcionalmente al subcircuito Z"". La regla de la pseudotransitividad generaliza la regla de la transitividad correspondiente al caso especial W: = 0. Damos una notación formal de esta regla: X→Y, Y→Z ├X→Z. Cabe señalar que las premisas y conclusiones dadas anteriormente se presentaron en forma abreviada mediante las designaciones de esquemas de dependencia funcional. En forma extendida, corresponden a las siguientes restricciones de dependencia funcional. Regla de inferencia 1. inv r(S); Regla de inferencia 2. inv r(S) ⇒ inv r(S); Regla de inferencia 3. inv r(S) & inv r(S) ⇒ inv r(S); Dibujar evidencia estas reglas de inferencia. 1. Prueba de la regla reflexividad se sigue directamente de la definición de la restricción de dependencia funcional cuando el subesquema X se reemplaza por el subcircuito Y. De hecho, tome la restricción de dependencia funcional: inversión r(S) y sustituimos X en lugar de Y, obtenemos: inversión r(S), y esta es la regla de reflexividad. Se demuestra la regla de la reflexividad. 2. Prueba de la regla reposición Ilustremos sobre diagramas de dependencia funcional. El primer diagrama es el diagrama del paquete: premisa: X → Y
Segundo diagrama: conclusión: X ∪ Z → Y
Sean las tuplas iguales en X ∪ Z. Entonces son iguales en X. Según la premisa, serán iguales en Y también. La regla de reposición está probada. 3. Prueba de la regla pseudo-transitividad también lo ilustraremos en diagramas, que en este caso particular serán tres. El primer diagrama es la primera premisa: premisa 1: X → Y
premisa 2: Y ∪ W → Z
Y finalmente, el tercer diagrama es el diagrama de conclusión: conclusión: X ∪ W → Z
Sean las tuplas iguales en X ∪ W. Entonces son iguales tanto en X como en W. Según la Premisa 1, también serán iguales en Y. Por lo tanto, según la Premisa 2, también serán iguales en Z. Se demuestra la regla de la pseudotransitividad. Todas las reglas están probadas. 3. Reglas de inferencia derivadas Otro ejemplo de reglas por las que uno puede, si es necesario, derivar nuevas reglas de dependencia funcional son las llamadas reglas de inferencia derivadas. ¿Qué son estas reglas, cómo se obtienen? Se sabe que si se deducen otras de algunas reglas ya existentes por métodos lógicos legítimos, entonces estas nuevas reglas, llamadas derivados, se puede utilizar junto con las reglas originales. Cabe señalar especialmente que estas reglas muy arbitrarias son "derivadas" precisamente de las reglas de inferencia de Armstrong que hemos visto anteriormente. Formulemos las reglas derivadas para derivar dependencias funcionales en la forma del siguiente teorema. Teorema Las siguientes reglas se derivan de las reglas de inferencia de Armstrong. Regla de inferencia 1. ├ X ∪ Z → X; Regla de inferencia 2. X → Y, X → Z ├ X ∪ Y → Z; Regla de inferencia 3. X → Y ∪ Z ├ X → Y, X → Z; Aquí X, Y, Z, W, como en el caso anterior, son subesquemas arbitrarios del esquema de la relación S. 1. La primera regla derivada se llama regla de trivialidad y se lee asi: "Se deriva la regla: 'la unión de los subcircuitos X y Z comporta funcionalmente X'". Una dependencia funcional en la que el lado izquierdo es un subconjunto del lado derecho se denomina trivial. De acuerdo con la regla de trivialidad, las restricciones de dependencia triviales se aplican automáticamente. Curiosamente, la regla de trivialidad es una generalización de la regla de reflexividad y, como esta última, podría derivarse directamente de la definición de la restricción de dependencia funcional. El hecho de que se derive esta regla no es accidental y está relacionado con la integridad del sistema de reglas de Armstrong. Hablaremos más sobre la integridad del sistema de reglas de Armstrong un poco más adelante. 2. La segunda regla derivada se llama regla de aditividad y queda como sigue: "Si el subcircuito X determina funcionalmente el subcircuito Y, y X simultáneamente determina funcionalmente Z, entonces se deduce de estas reglas la siguiente regla: "X determina funcionalmente la unión de los subcircuitos Y y Z"". 3. La tercera regla derivada se llama regla de proyectividad o la reglainversión de aditividad". Dice así: "Si el subcircuito X determina funcionalmente la unión de los subcircuitos Y y Z, entonces de esta regla se deduce la siguiente regla: "X determina funcionalmente el subcircuito Y y al mismo tiempo X determina funcionalmente el subcircuito Z" ", es decir, de hecho, esta regla derivada es la regla de aditividad inversa. Es curioso que las reglas de aditividad y proyectividad aplicadas a dependencias funcionales con las mismas partes izquierdas permitan combinar o, por el contrario, dividir las partes derechas de la dependencia. Al construir cadenas de inferencia, luego de formular todas las premisas, se aplica la regla de transitividad para incluir una dependencia funcional con el lado derecho en la conclusión. Dibujar evidencia Listado de reglas de inferencia arbitraria. 1. Prueba de la regla trivialidades. Realicémoslo, como todas las demostraciones posteriores, paso a paso: 1) tenemos: X → X (de la regla de reflexividad de inferencia de Armstrong); 2) además tenemos: X ∪ Z → X (obtenido aplicando primero la regla de finalización de la inferencia de Armstrong, y luego como consecuencia del primer paso de la demostración). La regla de la trivialidad ha sido probada. 2. Realizaremos una demostración paso a paso de la regla aditividad: 1) tenemos: X → Y (esta es la premisa 1); 2) tenemos: X → Z (esta es la premisa 2); 3) tenemos: Y ∪ Z → Y ∪ Z (de la regla de reflexividad de inferencia de Armstrong); 4) tenemos: X ∪ Z → Y ∪ Z (obtenido aplicando la regla de pseudo-transitividad de la inferencia de Armstrong, y luego como consecuencia del primer y tercer paso de la demostración); 5) tenemos: X ∪ X → Y ∪ Z (obtenido aplicando la regla de pseudo-transitividad de inferencia de Armstrong, y luego se sigue del segundo y cuarto paso); 6) tenemos X → Y ∪ Z (sigue del quinto paso). Se demuestra la regla de la aditividad. 3. Y finalmente construiremos una prueba de la regla. proyectividad: 1) tenemos: X → Y ∪ Z, X → Y ∪ Z (esto es una premisa); 2) tenemos: Y → Y, Z → Z (derivado usando la regla de reflexividad de inferencia de Armstrong); 3) tenemos: Y ∪ z → y, Y ∪ z → Z (obtenido de la regla de finalización de inferencia de Armstrong y el corolario del segundo paso de la demostración); 4) tenemos: X → Y, X → Z (obtenidas aplicando la regla de pseudotransitividad de la inferencia de Armstrong, y luego como consecuencia del primer y tercer paso de la demostración). Se demuestra la regla de proyectividad. Se prueban todas las reglas de inferencia derivadas. 4. Completitud del sistema de reglas de Armstrong Sea F(S) un conjunto dado de dependencias funcionales definidas sobre el esquema de relación S. Denotamos por inv la restricción impuesta por este conjunto de dependencias funcionales. Vamos a escribirlo: inversión r(S) = ∀X → Y ∈F(S) [inv r(S)]. Entonces, este conjunto de restricciones impuestas por las dependencias funcionales se descifra de la siguiente manera: para cualquier regla del sistema de dependencias funcionales X → Y perteneciente al conjunto de dependencias funcionales F(S), la restricción de dependencias funcionales inv r(S) definido sobre el conjunto de relaciones r(S). Sea alguna relación r(S) que satisfaga esta restricción. Aplicando las reglas de inferencia de Armstrong a las dependencias funcionales definidas para el conjunto F(S), se pueden obtener nuevas dependencias funcionales, como ya hemos dicho y demostrado anteriormente. Y, lo que es indicativo, la relación F(S) satisfará automáticamente las restricciones de estas dependencias funcionales, como puede verse en la forma extendida de las reglas de inferencia de Armstrong. Recuerde la forma general de estas reglas de inferencia extendidas: Regla de inferencia 1. inv r(S); Regla de inferencia 2. inv r(S) ⇒ inversión<X ∪ Z → Y> r(S); Regla de inferencia 3. inv r(S) & inv ∪ W → Z> r(S) ⇒ inversión<X ∪ W→Z>; Volviendo a nuestro razonamiento, rellenemos el conjunto F(S) con nuevas dependencias derivadas de él utilizando las reglas de Armstrong. Aplicaremos este procedimiento de reabastecimiento hasta que ya no obtengamos nuevas dependencias funcionales. Como resultado de esta construcción, obtendremos un nuevo conjunto de dependencias funcionales, llamado cierre conjunto F(S) y denotado F+(S). De hecho, tal nombre es bastante lógico, porque nosotros personalmente, a través de una larga construcción, "cerramos" el conjunto de dependencias funcionales existentes sobre sí mismo, agregando (de ahí el "+") todas las nuevas dependencias funcionales resultantes de las existentes. Cabe señalar que este proceso de construcción de una clausura es finito, porque el propio esquema de relación, sobre el que se realizan todas estas construcciones, es finito. No hace falta decir que un cierre es un superconjunto del conjunto que se cierra (¡de hecho, es más grande!) y no cambia de ninguna manera cuando se vuelve a cerrar. Si escribimos lo que se acaba de decir en forma de fórmula, obtenemos: F(S)⊆F+(S), [F+(S)]+= F+(S); Además, de la verdad probada (es decir, legalidad, legitimidad) de las reglas de inferencia de Armstrong y la definición de clausura, se deduce que cualquier relación que satisfaga las restricciones de un conjunto dado de dependencias funcionales satisfará la restricción de la dependencia que pertenece a la clausura. . X → Y ∈ F+(S) ⇒ ∀r(S) [inv r(S) ⇒ inversión r(S)]; Entonces, el teorema de completitud de Armstrong para el sistema de reglas de inferencia establece que la implicación externa puede ser reemplazada legítima y justificadamente por equivalencia. (No consideraremos la prueba de este teorema, ya que el proceso de prueba en sí no es tan importante en nuestro curso particular de conferencias). Lección número 10. Formas normales 1. El significado de la normalización del esquema de la base de datos El concepto que consideraremos en esta sección está relacionado con el concepto de dependencias funcionales, es decir, el significado de normalizar esquemas de bases de datos está inextricablemente vinculado con el concepto de restricciones impuestas por un sistema de dependencias funcionales, y en gran medida se deriva de este concepto. El punto de partida de cualquier diseño de base de datos es representar el dominio como una o más relaciones, y en cada paso del diseño se produce un conjunto de esquemas de relación que tiene propiedades "mejoradas". Por lo tanto, el proceso de diseño es un proceso de normalización de patrones de relación, donde cada forma normal sucesiva tiene propiedades que son, en cierto sentido, mejores que la anterior. Cada forma normal tiene un cierto conjunto de restricciones, y una relación está en cierta forma normal si satisface su propio conjunto de restricciones. Un ejemplo es la restricción de la primera forma normal: los valores de todos los atributos de la relación son atómicos. En la teoría de bases de datos relacionales, se suele distinguir la siguiente secuencia de formas normales: 1) primera forma normal (1 NF); 2) segunda forma normal (2 NF); 3) tercera forma normal (3 NF); 4) Forma normal de Boyce-Codd (BCNF); 5) cuarta forma normal (4 NF); 6) quinta forma normal, o forma normal de unión por proyección (5 NF o PJ/NF). (Este curso de conferencias incluye una discusión detallada de las primeras cuatro formas normales de relaciones básicas, por lo que no analizaremos las formas normales cuarta y quinta en detalle). Las principales propiedades de las formas normales son las siguientes: 1) cada forma normal siguiente es, en cierto sentido, mejor que la forma normal anterior; 2) al pasar a la siguiente forma normal, se conservan las propiedades de las formas normales anteriores. El proceso de diseño se basa en el método de normalización, es decir, la descomposición de una relación que está en la forma normal anterior en dos o más relaciones que satisfacen los requisitos de la siguiente forma normal (lo encontraremos cuando nosotros mismos tengamos que normalizar esa a medida que avanzamos en el material) o alguna otra relación básica). Como se mencionó en la sección sobre la creación de relaciones básicas, los conjuntos dados de dependencias funcionales imponen restricciones apropiadas en los esquemas de relaciones básicas. Estas restricciones se implementan generalmente de dos maneras: 1) declarativamente, es decir, declarando varios tipos de claves primarias, candidatas y foráneas en la relación base (este es el método más utilizado); 2) procedimentalmente, es decir, escribiendo código de programa (usando los llamados activadores mencionados anteriormente). Con la ayuda de una lógica simple, puede comprender cuál es el sentido de normalizar los esquemas de la base de datos. Normalizar las bases de datos o llevarlas a una forma normal significa definir dichos esquemas de relaciones básicas para minimizar la necesidad de escribir código de programa, aumentar el rendimiento de la base de datos y facilitar el mantenimiento de la integridad de los datos por estado e integridad referencial. Es decir, hacer que el código y trabajar con él sea lo más simple y conveniente posible para desarrolladores y usuarios. Para demostrar visualmente en comparación el funcionamiento de una base de datos normalizada y no normalizada, considere el siguiente ejemplo. Supongamos que tenemos una relación base que contiene información sobre los resultados de la sesión de examen. Ya hemos considerado una base de datos de este tipo antes. Por lo tanto, opción 1 esquemas de base de datos. Sesión (número de libro de registro, Nombre completo, Asunto, Calificación) En esta relación, como puede ver en la imagen del esquema de la relación base, se define una clave primaria compuesta: Clave principal (número de libro de clase, Materia); También en este sentido, se establece un sistema de dependencias funcionales: {Número de libro de cuentas} → {Apellido, Nombre, Patronímico}; Aquí hay una vista tabular de un pequeño fragmento de una base de datos con este esquema de relación. Ya hemos usado este fragmento al considerar las limitaciones de las dependencias funcionales, por lo que nos será muy fácil entender este tema usando su ejemplo.
Aquí, para mantener la integridad de los datos por estado, es decir, para cumplir con la restricción del sistema de dependencia funcional {número de libro de clase} → {Apellido, Nombre, Patronímico} al cambiar, por ejemplo, el apellido, es necesario revisar todas las tuplas de esta relación básica e ingresar secuencialmente los cambios necesarios. Sin embargo, dado que este es un proceso bastante engorroso y lento (especialmente si se trata de una base de datos de una gran institución educativa), los desarrolladores de sistemas de administración de bases de datos han llegado a la conclusión de que este proceso debe automatizarse, es decir , hecho automático. Ahora bien, el control sobre el cumplimiento de esta (y cualquier otra) dependencia funcional puede organizarse automáticamente mediante la declaración correcta de varias claves en la relación base y la llamada descomposición (es decir, romper algo en varias partes independientes) de esta relación. Entonces, dividamos nuestro esquema de relación "Sesión" existente en dos esquemas: el esquema "Estudiantes", que contiene solo información sobre los estudiantes de una institución educativa determinada, y el esquema "Sesión", que contiene información sobre la última sesión pasada. Y luego declararemos las claves de tal manera que podamos obtener fácilmente cualquier información necesaria. Mostremos cómo serán estos nuevos esquemas de relación con sus claves. 2 opción esquemas de base de datos. Estudiantes (número de libro de registro, Nombre completo), Clave primaria (número de libro de notas). Sesión (Número de libro de registro, Asunto, Calificación), Clave principal (número de libro de calificaciones, Materia), Referencias de clave externa (número de libro de calificaciones) Estudiantes (número de libro de calificaciones). ¿Qué tenemos ahora? En relación con los "Estudiantes", la clave principal "Número de libro de calificaciones" determina funcionalmente los otros tres atributos: "Apellido", "Nombre" y "Patronímico". Y en relación con "Sesión", la clave principal compuesta "Número de libro de calificaciones, Materia" también define de manera inequívoca, es decir, literalmente, funcionalmente, el último atributo de este esquema de relación: "Puntuación". Y se ha establecido la conexión entre estas dos relaciones: se realiza a través de la clave externa de la relación "Sesión" "Núm. del Libro de Calificaciones", que hace referencia al atributo del mismo nombre en la relación "Estudiantes" y, cuando se solicita, proporciona toda la información necesaria. Veamos ahora cómo se verán las relaciones representadas por las tablas correspondientes a la segunda opción de especificar los esquemas de base de datos correspondientes.
Así, vemos que el objetivo de la normalización en términos de las restricciones impuestas por las dependencias funcionales es la necesidad de imponer las dependencias funcionales requeridas en cualquier base de datos usando declaraciones de varios tipos de claves primarias, candidatas y foráneas de las relaciones base. 2. Primera Forma Normal (1FN) En las primeras etapas del diseño de bases de datos y el desarrollo de esquemas de gestión de bases de datos, se utilizaron atributos simples e inequívocos como las unidades de código más productivas y racionales. Luego usaron junto con atributos simples y compuestos, así como junto con atributos de un solo valor y de varios valores. Expliquemos el significado de cada uno de estos conceptos. Atributos compuestos, a diferencia de los simples, son atributos compuestos de varios atributos simples. Atributos multivalor, a diferencia de los de un solo valor, son atributos que representan múltiples valores. Estos son ejemplos de atributos simples, compuestos, de un solo valor y de varios valores. Considere la siguiente tabla que representa la relación:
Aquí, el atributo "Teléfono" es simple, inequívoco, y el atributo "Dirección" es simple, pero tiene múltiples valores. Ahora considere otra tabla, con diferentes atributos:
En esta relación, representada por la tabla, el atributo "Teléfonos" es simple pero de múltiples valores, y el atributo "Direcciones" es compuesto y de múltiples valores. En general, son posibles varias combinaciones de atributos simples o compuestos. En diferentes casos, las tablas que representan relaciones pueden verse así en general:
Al normalizar esquemas de relaciones básicas, los programadores pueden usar uno de los cuatro tipos más comunes de formas normales: primera forma normal (1NF), segunda forma normal (2NF), tercera forma normal (3NF) o forma normal de Boyce-Codd (NFBC) . Para aclarar: la abreviatura NF es una abreviatura de la frase en inglés Normal Form. Formalmente, además de las anteriores, existen otros tipos de formas normales, pero las anteriores son unas de las más populares. Actualmente, los desarrolladores de bases de datos intentan evitar los atributos compuestos y de valores múltiples para no complicar la escritura del código, no sobrecargar su estructura y no confundir a los usuarios. De estas consideraciones, la definición de la primera forma normal sigue lógicamente. Definición. Cualquier relación base está en primera forma normal si y solo si el esquema de esta relación contiene solo atributos simples y de un solo valor, y necesariamente con la misma semántica. Para explicar visualmente las diferencias entre relaciones normalizadas y no normalizadas, considere un ejemplo. Sea, existe una relación no normalizada, con el siguiente esquema. Por lo tanto, opción 1 esquemas de relación con una clave primaria simple definida en él: Empleados (número personal, Apellidos, Nombre, Patronímico, Código de Cargo, Teléfonos, Fecha de ingreso o egreso); Clave principal (número de personal); Hagamos una lista de los errores que hay en este esquema de relaciones, es decir, nombraremos aquellos signos que hacen que este esquema sea propiamente no normalizado: 1) el atributo "Apellido Nombre Patronímico" es compuesto, es decir, compuesto de elementos heterogéneos; 2) el atributo "Teléfonos" tiene varios valores, es decir, su valor es un conjunto de valores; 3) el atributo "Fecha de aceptación o despido" no tiene una semántica inequívoca, es decir, en el último caso no está claro qué fecha se ingresa. Si, por ejemplo, se introduce un atributo adicional para definir con mayor precisión el significado de una fecha, el valor de este atributo será semánticamente claro, pero aún así es posible almacenar solo una de las fechas especificadas para cada empleado. ¿Qué hay que hacer para llevar esta relación a la forma normal? Primero, es necesario dividir los atributos compuestos en simples para excluir estos atributos muy compuestos, así como los atributos con semántica compuesta. Y en segundo lugar, es necesario descomponer esta relación, es decir, es necesario dividirla en varias relaciones independientes nuevas para excluir los atributos multivaluados. Así, teniendo en cuenta todo lo anterior, tras reducir la relación "Empleados" a la primera forma normal o 1NF mediante su descomposición, obtendremos un sistema de las siguientes relaciones con claves primarias y foráneas puestas en ellas. Por lo tanto, opción 2 relaciones: Empleados (número personal, Apellido, Nombre, Patronímico, Código de cargo, Fecha de ingreso, Fecha de baja); Clave principal (número de personal); Los telefonos (Número de personal, Teléfono); Clave principal (número de personal, Teléfono); Referencias de clave externa (número de personal) Empleados (número de personal); Entonces ¿Qué vemos? El atributo compuesto "Apellido Nombre Patronímico" ya no está en nuestra relación, en su lugar hay tres atributos simples "Apellido", "Nombre" y "Patronímico", por lo que se excluyó este motivo de la "anormalidad" de la relación. . Además, en lugar del atributo con semántica poco clara "Fecha de contratación o despido", ahora tenemos dos atributos "Fecha de admisión" y "Fecha de despido", cada uno de los cuales tiene una semántica inequívoca. Por lo tanto, la segunda razón por la que nuestra relación "Empleados" no está en forma normal también se elimina con seguridad. Y, finalmente, la última razón por la que la relación "Empleados" no se normalizó es la presencia del atributo multivaluado "Teléfonos". Para deshacerse de este atributo, fue necesario descomponer toda la relación. Como resultado de esta descomposición, el atributo "Teléfonos" se excluyó de la relación original "Empleados" en general, pero se formó una segunda relación - "Teléfonos", en la que hay dos atributos: "número de personal del empleado" y "Teléfono". ", es decir, todos los atributos - de nuevo simple, se cumple la condición de pertenecer a la primera forma normal. Estos atributos "Número de empleado" y "Teléfono" forman una clave primaria compuesta de la relación "Teléfonos", y el atributo "Número de empleado", a su vez, es una clave externa que hace referencia al atributo del mismo nombre en la relación "Empleados". La relación ", es decir, en la relación el atributo "Teléfonos" de la clave principal "número de personal" también es una clave externa que hace referencia a la clave principal de la relación "Empleados". Por lo tanto, se proporciona un vínculo entre las dos relaciones. Usando este enlace, puede mostrar la lista completa de sus teléfonos por el número de personal de cualquier empleado sin mucho esfuerzo y tiempo sin recurrir al uso de atributos compuestos. Tenga en cuenta que si hubiera dependencias funcionales en relación con el sistema, después de todas las transformaciones anteriores, la normalización no se completaría. Sin embargo, en este ejemplo particular, no hay restricciones de dependencia funcional, por lo que no se requiere una mayor normalización de esta relación. 3. Segunda Forma Normal (2NF) La segunda forma normal, o 2NF, impone requisitos más estrictos a las relaciones. Esto se debe a que la definición de la segunda forma normal de relaciones implica, a diferencia de la primera forma normal, la presencia de un sistema de restricciones a las dependencias funcionales. Definición. La relación base está en segunda forma normal en relación con un conjunto dado de dependencias funcionales si y solo si está en la primera forma normal y, además, cada atributo no clave depende completamente funcionalmente de cada clave. En esta definición atributo no clave es cualquier atributo de relación que no está contenido en ninguna clave primaria o candidata de la relación. La dependencia funcional completa de una clave no implica ninguna dependencia funcional de ninguna parte de esa clave. Así, ahora, al normalizar una relación, también debemos vigilar el cumplimiento de las condiciones para que la relación esté en la primera forma normal, es decir, que sus atributos sean simples e inequívocos, así como el cumplimiento de la segunda condición relativa a las restricciones de las dependencias funcionales. Está claro que las relaciones con claves simples (primarias y candidatas) están ciertamente en segunda forma normal. De hecho, en este caso, la dependencia de una parte de la llave simplemente no parece posible, porque la llave simplemente no tiene partes separadas. Ahora, como en el pasaje del tema anterior, considere un ejemplo de un esquema de relación no normalizado y el proceso de normalización en sí. Por lo tanto, opción 1 esquemas de relación: Audiencias (Edificio No., Auditorio No., Área mXNUMX m, No. comandante de servicio del cuerpo); Clave principal (número de corpus, número de audiencia); Además, se define el siguiente sistema de dependencia funcional: {Nº del cuerpo} → {Nº del comandante de servicio del cuerpo}; ¿Qué vemos? Se cumplen todas las condiciones para que esta relación "Audiencia" permanezca en la primera forma normal, porque cada uno de los atributos de esta relación es inequívoco y simple. Pero la condición de que cada elemento no clave debe depender funcionalmente por completo de la clave no se cumple. ¿Por qué? Sí, porque el atributo "Nº del comandante del estado mayor del cuerpo" no depende funcionalmente de la clave compuesta "Nº del cuerpo, N° de la audiencia", sino de una parte de esta clave, es decir, del atributo "No. del cuerpo". De hecho, después de todo, es el número de cuerpo el que determina completamente qué comandante en particular se le asigna y, a su vez, el número de personal del comandante de cuerpo no puede depender de ningún número de auditorio. Por lo tanto, la tarea principal de nuestra normalización se convierte en la tarea de garantizar que las claves se distribuyan de tal manera que, en particular, el atributo "No. Para conseguirlo tendremos que volver a aplicar, como en el párrafo anterior, la descomposición de la relación. Entonces, el siguiente sistema de relaciones, que es opción 2 La relación "Audiencia" se obtuvo de la relación original al descomponerla en varias relaciones independientes nuevas: cuerpo (Nro. de casco, número del comandante de personal del cuerpo); Clave principal (número de caso); Audiencias (Edificio No., Auditorio No., Área mXNUMX metro); Clave principal (número de corpus, número de audiencia); Referencias de clave externa (número de caso) Casos (número de caso); ¿Qué vemos ahora? Con respecto al atributo no clave "Cuerpo", el "Número de personal del comandante del cuerpo" depende completamente funcionalmente de la clave principal "Número de cuerpo". Aquí se cumple plenamente la condición para encontrar la relación en la segunda forma normal. Ahora pasemos a la consideración de la segunda relación: "Audiencia". Con respecto a "Audiencia", el atributo de clave principal "Caso #" también es una clave externa que hace referencia a la clave principal de la relación "Caso". En este sentido, el atributo no clave "Área en metros cuadrados" depende completamente de la clave primaria compuesta completa "Edificio #, Auditorio #" y no depende, ni siquiera puede, de ninguna de sus partes. Por tanto, al descomponer la relación original, hemos llegado a la conclusión de que todas las condiciones de la definición de la segunda forma normal se cumplen por completo. En este ejemplo, todos los requisitos de dependencia funcional se imponen mediante la declaración de claves primarias (aquí no hay claves candidatas) y claves externas. Por lo tanto, no se requiere más normalización. 4. Tercera Forma Normal (3NF) La siguiente forma normal que veremos es la tercera forma normal (o 3FN). A diferencia de la primera forma normal, así como de la segunda forma normal, la tercera implica la asignación de un sistema de dependencias funcionales junto con la relación. Formulemos qué propiedades debe tener una relación para que se reduzca a la tercera forma normal. Definición. La relación base está en tercera forma normal con respecto a un conjunto dado de dependencias funcionales si y solo si está en la segunda forma normal y cada atributo que no es clave depende completamente funcionalmente solo de las claves. Por lo tanto, los requisitos de la tercera forma normal son más estrictos que los requisitos de la primera y segunda formas normales, incluso combinadas. De hecho, en la tercera forma normal, todo atributo no clave depende de la clave, y de toda la clave, y de nada más que la clave. Ilustremos el proceso de llevar una relación no normalizada a la tercera forma normal. Para hacer esto, considere un ejemplo: una relación que no está en tercera forma normal. Por lo tanto, opción 1 esquemas de la relación "Empleados": Empleados (número personal, Apellido, Nombre, Patronímico, Código de Cargo, Salario); Clave principal (número de personal); Además, por encima de esta relación "Empleados" se establece el siguiente sistema de dependencias funcionales: {Código de puesto} → {Salario}; De hecho, por regla general, el monto del salario, es decir, el monto de los salarios, depende directamente del puesto y, por lo tanto, de su código en la base de datos correspondiente. Es por eso que esta relación "Empleados" no está en tercera forma normal, porque resulta que el atributo no clave "Salario" depende completamente funcionalmente del atributo "Código de puesto", aunque este atributo no es clave. Curiosamente, cualquier relación se reduce a la tercera forma normal exactamente del mismo modo que a las dos formas anteriores a ésta, a saber, por descomposición. Habiendo descompuesto la relación "Empleados", obtenemos el siguiente sistema de nuevas relaciones independientes: Por lo tanto, opción 2 esquemas de la relación "Empleados": Posiciones (Código de posición, Salario); Clave principal (código de posición); Empleados (número personal, Apellido, Nombre, Patronímico, Código de cargo); Clave principal (código de posición); Referencias de clave externa (Código de posición) Posiciones (Código de posición); Ahora, como podemos ver, en relación con "Puesto", el atributo no clave "Salario" depende completamente funcionalmente de la clave primaria simple "Código de puesto" y solo de esta clave. Tenga en cuenta que, en relación con los "Empleados", los cuatro atributos no clave "Apellido", "Nombre", "Patronímico" y "Código de puesto" dependen funcionalmente de la clave principal simple "Número de empleo". En este sentido, el atributo "Position ID" es una clave foránea que hace referencia a la clave primaria de la relación "Positions". En este ejemplo, todos los requisitos se imponen al declarar claves primarias y externas simples, por lo que no se requiere más normalización. Es interesante y útil saber que en la práctica uno suele limitarse a llevar las bases de datos a la tercera forma normal. Al mismo tiempo, no se pueden imponer algunas dependencias funcionales de atributos clave sobre otros atributos de la misma relación. El soporte para dichas dependencias funcionales no estándar se implementa utilizando los disparadores mencionados anteriormente (es decir, de manera procesal, escribiendo el código de programa apropiado). Además, los disparadores deben operar con tuplas de esta relación. 5. Forma normal de Boyce-Codd (NFBC) La forma normal de Boyce-Codd sigue en "complejidad" justo después de la tercera forma normal. Por lo tanto, la forma normal de Boyce-Codd a veces también se llama simplemente tercera forma normal fuerte (o reforzado 3 NF). ¿Por qué está reforzada? Formulamos la definición de la forma normal de Boyce-Codd: Definición. La relación base está en Boyce forma normal - Kodd si y solo si está en la tercera forma normal, y no solo cualquier atributo que no sea clave depende completamente funcionalmente de cualquier clave, sino que cualquier atributo clave debe depender completamente funcionalmente de cualquier clave. Por lo tanto, el requisito de que los atributos que no son clave realmente dependan de la clave completa y de nada más que la clave se aplica también a los atributos clave. En una relación que está en la forma normal de Boyce-Codd, todas las dependencias funcionales dentro de la relación son impuestas por la declaración de claves. Sin embargo, al reducir las relaciones de la base de datos a la forma de Boyce-Codd, son posibles situaciones en las que las dependencias entre los atributos de varias relaciones resultan ser dependencias funcionales no impuestas. Apoyar tales dependencias funcionales con disparadores que operan en tuplas de diferentes relaciones es más difícil que en el caso de la tercera forma normal, cuando los disparadores operan en tuplas de una sola relación. Entre otras cosas, la práctica de diseñar sistemas de gestión de bases de datos ha demostrado que no siempre es posible llevar la relación básica a la forma normal de Boyce-Codd. La razón de las anomalías señaladas es que los requisitos de la segunda forma normal y la tercera forma normal no requerían una dependencia funcional mínima de la clave primaria de atributos que son componentes de otras claves posibles. Este problema se resuelve mediante la forma normal, que históricamente se denomina forma normal de Boyce-Codd y que es un refinamiento de la tercera forma normal en el caso de la presencia de varias claves posibles superpuestas. En general, la normalización del esquema de la base de datos hace que las actualizaciones de la base de datos sean más eficientes para que las realice el sistema de administración de la base de datos porque reduce la cantidad de comprobaciones y copias de seguridad que mantienen la integridad de la base de datos. Al diseñar una base de datos relacional, casi siempre logra la segunda forma normal de todas las relaciones en la base de datos. En las bases de datos que se actualizan con frecuencia, suelen intentar proporcionar la tercera forma normal de la relación. La forma normal de Boyce-Codd recibe mucha menos atención porque, en la práctica, las situaciones en las que una relación tiene varias claves candidatas superpuestas compuestas son raras. Todo lo anterior hace que la forma normal de Boyce-Codd no sea muy conveniente de usar al desarrollar el código del programa, por lo que, como se mencionó anteriormente, en la práctica, los desarrolladores suelen limitarse a llevar sus bases de datos a la tercera forma normal. Sin embargo, también tiene su propia característica bastante curiosa. El punto es que las situaciones en las que una relación está en tercera forma normal pero no en la forma normal de Boyce-Codd son extremadamente raras en la práctica, es decir, después de la reducción a la tercera forma normal, por lo general todas las dependencias funcionales se imponen mediante declaraciones de primaria, candidata y claves foráneas, por lo que no hay necesidad de activadores para admitir dependencias funcionales. Sin embargo, sigue existiendo la necesidad de disparadores para soportar las restricciones de integridad que no están vinculadas por dependencias funcionales. 6. Anidamiento de formas normales ¿Qué significa el anidamiento de formas normales? Anidamiento de formas normales - esta es la relación de los conceptos de formas debilitadas y fortalecidas entre sí. El anidamiento de formas normales se sigue completamente de sus respectivas definiciones. Imaginemos un diagrama que ilustre la relación de anidamiento de las formas normales que conocemos:
Expliquemos los conceptos de formas normales debilitadas y fortalecidas entre sí usando ejemplos específicos. La primera forma normal se debilita en relación con la segunda forma normal (y también en relación con todas las demás formas normales). De hecho, recordando las definiciones de todas las formas normales por las que hemos pasado, podemos ver que los requisitos de cada forma normal incluían el requisito de pertenecer a la primera forma normal (después de todo, se incluyó en cada definición posterior). La segunda forma normal es más fuerte que la primera forma normal, pero más débil que la tercera forma normal y la forma normal de Boyce-Codd. De hecho, la pertenencia a la segunda forma normal está incluida en la definición de la tercera, y la propia segunda forma, a su vez, incluye a la primera forma normal. La forma normal de Boyce-Codd no solo se fortalece con respecto a la tercera forma normal, sino también con respecto a todas las demás que la preceden. Y la tercera forma normal, a su vez, se debilita solo con respecto a la forma normal de Boyce-Codd. Clase n.° 11. Diseño de esquemas de bases de datos El medio más común para abstraer esquemas de bases de datos cuando se diseña a nivel lógico es el llamado modelo entidad-relación. A veces también se le llama modelo de emergencia, donde ER es una abreviatura de la frase en inglés Entidad - Relación, que literalmente se traduce como "entidad - relación". Los elementos de tales modelos son clases de entidad, sus atributos y relaciones. Daremos explicaciones y definiciones de cada uno de estos elementos. clase de entidad es como una clase de objetos sin método en el sentido de la programación orientada a objetos. Al pasar a la capa física, las clases de entidad se convierten en relaciones básicas de bases de datos relacionales para sistemas de gestión de bases de datos específicos. Ellos, como las mismas relaciones básicas, tienen sus propios atributos. Demos una definición más precisa y rigurosa de los objetos que acabamos de dar. clase Se denomina descripción nombrada de una colección de objetos con atributos, operaciones, relaciones y semántica comunes. Gráficamente, una clase generalmente se representa como un rectángulo. Cada clase debe tener un nombre (una cadena de texto) que la distinga de forma única de todas las demás clases. atributo de clase es una propiedad con nombre de una clase que describe el conjunto de valores que pueden tomar las instancias de esta propiedad. Una clase puede tener cualquier número de atributos (en particular, no puede tener atributos). Una propiedad expresada por un atributo es una propiedad de la entidad modelada que es común a todos los objetos de la clase dada. Entonces, un atributo es una abstracción del estado de un objeto. Cualquier atributo de cualquier objeto de clase debe tener algún valor. Las llamadas relaciones se implementan mediante la declaración de claves foráneas (ya hemos conocido antes fenómenos similares), es decir, en relación se declaran claves foráneas que remiten a las claves primarias o candidatas de alguna otra relación. Y a través de esto, varias relaciones básicas independientes diferentes se "vinculan" en un solo sistema llamado base de datos. Además, el diagrama que forma la base gráfica del modelo entidad-relación se representa utilizando el lenguaje de modelado unificado UML. Muchos libros están dedicados al lenguaje de modelado orientado a objetos UML (o Lenguaje de modelado unificado), muchos de los cuales han sido traducidos al ruso (y algunos escritos por autores rusos). En general, UML permite modelar diferentes tipos de sistemas: puramente software, puramente hardware, software-hardware, mixto, incluyendo explícitamente actividades humanas, etc. Pero, entre otras cosas, como ya hemos mencionado, el lenguaje UML se usa activamente para diseñar bases de datos relacionales. Para ello se utiliza una pequeña parte del lenguaje (diagramas de clases), y aun así no en su totalidad. Desde la perspectiva del diseño de bases de datos relacionales, las capacidades de modelado no son muy diferentes de las de los diagramas ER. También queríamos mostrar que, en el contexto del diseño de bases de datos relacionales, los métodos de diseño estructural basados en el uso de diagramas ER y los métodos orientados a objetos basados en el uso del lenguaje UML difieren principalmente solo en la terminología. El modelo ER es conceptualmente más simple que UML, tiene menos conceptos, términos y opciones de aplicación. Y esto es comprensible, ya que se desarrollaron diferentes versiones de modelos ER específicamente para admitir el diseño de bases de datos relacionales, y los modelos ER casi no contienen características que vayan más allá de las necesidades reales de un diseñador de bases de datos relacionales. El UML pertenece al mundo de los objetos. Este mundo es mucho más complicado (si se quiere, más incomprensible, más confuso) que el mundo relacional. Debido a que UML se puede usar para el modelado unificado orientado a objetos de cualquier cosa, el lenguaje contiene una gran cantidad de conceptos, términos y casos de uso que son redundantes desde la perspectiva del diseño de una base de datos relacional. Si extraemos del mecanismo general de los diagramas de clases lo que realmente se requiere para el diseño de bases de datos relacionales, obtendremos exactamente diagramas ER con una notación y terminología diferentes. Es curioso que al formar nombres de clase en UML se permita una combinación arbitraria de letras, números e incluso signos de puntuación. Sin embargo, en la práctica, se recomienda utilizar adjetivos y sustantivos cortos y significativos como nombres de clase, cada uno de los cuales comienza con una letra mayúscula. (Consideraremos el concepto de un diagrama con más detalle en el siguiente párrafo de nuestra lección). 1. Diversos tipos y multiplicidades de enlaces La relación entre relaciones en el diseño de esquemas de bases de datos se representa como líneas que conectan clases de entidad. Además, cada uno de los extremos de la conexión puede (y generalmente debe) caracterizarse por el nombre (es decir, el tipo de conexión) y la multiplicidad del papel de la clase en la conexión. Consideremos con más detalle los conceptos de multiplicidad y tipos de conexiones. multiplicidad (multiplicidad) es una característica que indica cuántos atributos de una clase de entidad con un rol dado pueden o deben participar en cada instancia de una relación de algún tipo. La forma más común de establecer la cardinalidad de un rol de relación es especificar directamente un número o rango específico. Por ejemplo, especificar "1" significa que cada clase con un rol determinado debe participar en alguna instancia de esta conexión, y exactamente un objeto de la clase con este rol puede participar en cada instancia de la conexión. Especificar el rango "0..1" indica que no se requiere que todos los objetos de la clase con un rol dado participen en cualquier instancia de esta relación, pero solo un objeto puede participar en cada instancia de la relación. Hablemos de la multiplicidad con más detalle. Las cardinalidades típicas y más comunes en los sistemas de diseño de bases de datos son las siguientes cardinalidades: 1) 1 - la multiplicidad de la conexión en su extremo correspondiente es igual a uno; 2) 0... 1: esta forma de notación significa que la multiplicidad de una conexión dada en su extremo correspondiente no puede exceder uno; 3) 0... ∞ - esta multiplicidad se descifra simplemente como "muchos". Es curioso que, por regla general, “mucho” signifique “nada”; 4) 1... ∞ - esta designación se le dio a la multiplicidad “uno o más”. Pongamos un ejemplo de un diagrama simple para ilustrar el trabajo con diferentes multiplicidades de enlaces.
De acuerdo con este diagrama, se puede comprender fácilmente que cada boletería tiene muchos boletos y, a su vez, cada boleto está ubicado en una (y no más que esa) boletería. Ahora considere los tipos o nombres de enlaces más comunes. Vamos a enumerarlos: 1) 1: 1 - esta designación se le dio a la conexión "uno a uno", es decir, es, por así decirlo, una correspondencia uno a uno de dos conjuntos; 2) 1 : 0... ∞ - esta es una designación para una conexión como "uno a muchos". Para abreviar, tal relación se llama "1: M". En el diagrama considerado anteriormente, como puede ver, hay una relación con ese nombre; 3) 0... ∞ : 1 - esta es una inversión de la conexión anterior o una conexión del tipo "muchos a uno"; 4) 0... ∞ : 0... ∞ es una designación para una conexión como "muchos a muchos", es decir, hay muchos atributos en cada extremo del enlace; 5) 0... 1 : 0... 1: esta es una conexión similar a la conexión de tipo "uno a uno" introducida anteriormente; a su vez, se llama "no más de uno a no más de uno"; 6) 0... 1 : 0... ∞ - esta es una conexión similar a una conexión de uno a muchos, se llama "no más de uno a muchos"; 7) 0... ∞ : 0... 1 - esta es una conexión, a su vez, similar a una conexión de tipo muchos a uno, se llama "muchos a no más de uno". Como puede ver, las últimas tres conexiones se obtuvieron de las conexiones que se enumeran en nuestra lección bajo los números uno, dos y tres reemplazando la multiplicidad de "uno" con la multiplicidad de "no más de uno". 2. Diagramas. Tipos de gráficos Y ahora, finalmente, pasemos directamente a la consideración de los diagramas y sus tipos. En general, hay tres niveles del modelo lógico. Estos niveles difieren en la profundidad de representación de la información sobre la estructura de datos. Estos niveles corresponden a los siguientes diagramas: 1) diagrama de presentación; 2) diagrama clave; 3) diagrama de atributos completo. Analicemos cada uno de estos tipos de diagramas y expliquemos en detalle el significado de sus diferencias en la profundidad de presentación de la información sobre la estructura de datos. 1. Diagrama de presentación. Dichos diagramas describen solo las clases más básicas de entidades y sus relaciones. Las claves en dichos diagramas pueden no estar descritas en absoluto y, en consecuencia, las conexiones no pueden individualizarse de ninguna manera. Por lo tanto, las relaciones de muchos a muchos son aceptables, aunque generalmente se evitan o, si existen, se ajustan. Los atributos compuestos y de valores múltiples también son perfectamente válidos, aunque escribimos anteriormente que las relaciones de base con tales atributos no se reducen a ninguna forma normal. Curiosamente, de los tres tipos de diagramas que hemos considerado, solo el último tipo (el diagrama de atributos completo) asume que los datos presentados con él están en alguna forma normal. Mientras que el diagrama de presentación ya considerado y el siguiente diagrama clave no implican nada por el estilo. Dichos diagramas generalmente se usan para presentaciones (de ahí su nombre: de presentación, es decir, se usan para presentaciones, demostraciones, donde no se necesitan detalles excesivos). A veces, al diseñar bases de datos, es necesario consultar con expertos en el área temática que trata la información de esta base de datos en particular. Luego también se utilizan diagramas de presentación, porque para obtener la información necesaria de especialistas en una profesión ajena a la programación, no se requiere en absoluto una aclaración excesiva de detalles específicos. 2. diagrama clave. A diferencia de los diagramas de presentación, los diagramas clave necesariamente describen todas las clases de entidades y sus relaciones, sin embargo, en términos de claves primarias solamente. Aquí, las relaciones de muchos a muchos ya están necesariamente detalladas (es decir, las relaciones de este tipo en su forma pura simplemente no se pueden especificar aquí). Los atributos de valores múltiples todavía se permiten de la misma manera que en un diagrama de presentación, pero si están presentes en un diagrama clave, generalmente se convierten en clases de entidad independientes. Pero, curiosamente, los atributos inequívocos aún pueden representarse de manera incompleta o describirse como compuestos. Estas "libertades", que siguen siendo válidas en diagramas como los de presentación y clave, no se permiten en el siguiente tipo de diagrama, porque determinan que la relación base no se normaliza. Por lo tanto, podemos concluir que los diagramas clave en el futuro asumen solo atributos "colgantes" en las clases de entidad ya descritas, es decir, usando un diagrama de presentación, es suficiente describir las clases de entidad más necesarias y luego, usando un diagrama clave, agregue todo. a él atributos necesarios y especificar todos los enlaces más importantes. 3. Diagrama de atributos completo. Los diagramas de atributos completos describen con más detalle todo lo anterior, todas las clases de entidades, sus atributos y las relaciones entre estas clases de entidades. Como regla general, tales gráficos representan datos que están en la tercera forma normal, por lo que es natural que en las relaciones básicas descritas por dichos gráficos, los atributos compuestos o multivaluados no estén permitidos, al igual que no hay muchos a muchos no granulares. muchas relaciones Sin embargo, los gráficos de atributos completos todavía tienen un inconveniente, es decir, no pueden llamarse completamente los gráficos más completos en términos de presentación de datos. Por ejemplo, todavía no se tiene en cuenta la peculiaridad de los sistemas de gestión de bases de datos específicos cuando se utilizan diagramas de atributos completos y, en particular, el tipo de datos se especifica solo en la medida necesaria para el nivel lógico requerido de modelado. 3. Asociaciones y migración de claves Un poco antes, ya hablamos sobre qué son las relaciones en las bases de datos. En particular, la relación se estableció al declarar las claves foráneas de la relación. Pero en esta sección de nuestro curso, ya no estamos hablando de relaciones básicas, sino de cajas registradoras de entidades. En este sentido, el proceso de establecimiento de relaciones todavía está asociado con las declaraciones de varias claves, pero ahora estamos hablando de las claves de las clases de entidad. Es decir, el proceso de establecimiento de relaciones está asociado con la transferencia de una clave primaria simple o compuesta de una clase de entidad a otra clase. El proceso de tal transferencia también se llama migración clave. En este caso, la clase de entidad cuyas claves primarias se transfieren se llama clase padre, y la clase de entidades a las que se migran las claves foráneas se llama clase infantil entidades. En una clase de entidad secundaria, los atributos clave reciben el estado de atributos de clave externa y pueden o no participar en la formación de su propia clave primaria. Por lo tanto, cuando se migra una clave principal de una clase de entidad principal a una secundaria, aparece una clave externa en la clase secundaria que hace referencia a la clave principal de la clase principal. Para la conveniencia de la representación formulaica de la migración clave, presentamos los siguientes marcadores clave: 1) PK: así denotaremos cualquier atributo de la clave principal (clave principal); 2) FK: con este marcador denotaremos los atributos de una clave externa (clave externa); 3) PFK - con dicho marcador denotaremos un atributo de la clave principal/foránea, es decir, cualquier atributo que sea parte de la única clave principal de alguna clase de entidad y al mismo tiempo sea parte de alguna clave externa de la misma clase de entidad . Por lo tanto, los atributos de una clase de entidad con marcadores PK y FK forman la clave principal de esta clase. Y atributos con marcadores FK y PFK son parte de algunas claves foráneas de esta clase de entidad. En general, las claves pueden migrar de diferentes maneras y, en cada caso diferente, surge algún tipo de conexión. Entonces, consideremos qué tipos de enlaces hay según el esquema de migración clave. En total, hay dos esquemas de migración clave. 1. Esquema de migración ∀PK (PK |→PFK); En esta entrada, el símbolo "|→" significa el concepto de "migra", es decir, la fórmula anterior se leerá de la siguiente manera: cualquier (cada) atributo de la clave principal PK de la clase de entidad principal se transfiere (migra) a la Clave primaria PFClase de entidad secundaria K, que, por supuesto, también es una clave externa para esta clase. En este caso, estamos hablando del hecho de que, sin excepción, todos los atributos clave de la clase de entidad principal deben migrarse a la clase de entidad secundaria. Este tipo de conexión se llama identificando, ya que la clave de la clase de entidad principal está completamente involucrada en la identificación de las entidades secundarias. Entre los enlaces de tipo identificativo, a su vez, existen dos tipos de enlaces independientes más posibles. Así pues, existen dos tipos de vínculos identificativos: 1) identificando completamente. Se dice que una relación de identificación se identifica completamente si y solo si los atributos de la clave principal que migra de la clase de entidad principal forman completamente la clave principal (y externa) de la clase de entidad secundaria. Una relación de plena identificación también se denomina a veces categórico, porque una relación de identificación completa identifica entidades secundarias en todas las categorías; 2) no identificarse completamente. Una relación de identificación se denomina identificación incompleta si y solo si los atributos de la clave principal que migra de la clase de entidad principal solo forman parcialmente la clave principal (y al mismo tiempo externa) de la clase de entidad secundaria. Así, además de la llave con el marcador PFK también tendrá una clave marcada como PK. En este caso, la PFK de clave externa de la clase de entidad secundaria estará completamente determinada por la PK de clave principal de la clase de entidad principal, pero simplemente la PK de clave principal de esta relación secundaria no estará determinada por la PK de clave principal de la entidad principal. clase de entidad, será independiente. 2. Esquema de migración ∃PK (PK |→ FK); Dicho esquema de migración debe leerse de la siguiente manera: existen atributos de clave principal de la clase de entidad principal que, durante la migración, se transfieren a los atributos no clave obligatorios de la clase de entidad secundaria. Por lo tanto, en este caso, estamos hablando del hecho de que algunos, y no todos, como en el caso anterior, los atributos de clave principal de la clase de entidad principal se transfieren a la clase de entidad secundaria. Además, si el esquema de migración anterior definía la migración a la clave principal de la relación secundaria, que al mismo tiempo también se convertía en una clave externa, entonces el último tipo de migración determina que los atributos de la clave principal de la clase de entidad principal migren a la clave ordinaria. , inicialmente atributos no clave, que luego adquieren el estado de clave externa. Este tipo de conexión se llama no identificado, porque, de hecho, la clave principal no está completamente involucrada en la formación de entidades secundarias, simplemente no las identifica. Entre las relaciones no identificatorias, también se distinguen dos posibles tipos de relaciones. Así, las relaciones no identificatorias son de los dos tipos siguientes: 1) necesariamente no identificable. Se dice que las relaciones no identificatorias son necesariamente no identificatorias si y solo si se prohíben los valores nulos para todos los atributos clave de migración de una clase de entidad secundaria; 2) opcionalmente no identificable. Se dice que las relaciones no identificables no son necesariamente no identificables si y solo si se permiten valores nulos para algunos atributos clave de migración de la clase de entidad secundaria. Resumimos todo lo anterior en forma de la siguiente tabla con el fin de facilitar la tarea de sistematizar y comprender el material presentado. También en esta tabla incluiremos información sobre qué tipos de relaciones ("no más de uno a uno", "muchos a uno", "muchos a no más de uno") corresponden a qué tipos de relaciones (de identificación plena, no identificándose, necesariamente no identificándose, no necesariamente no identificándose). Entonces, entre las clases de entidad padre e hijo, se establece el siguiente tipo de relación, dependiendo del tipo de relación.
Entonces, vemos que en todos los casos excepto en el último, la referencia no está vacía (no es nula) → 1. Tenga en cuenta la tendencia de que en el extremo principal de la conexión en todos los casos, excepto en el último, la multiplicidad se establece en "uno". Esto se debe a que el valor de la clave foránea en los casos de estas relaciones (es decir, tipos de relaciones plenamente identificadores, no plenamente identificadores y necesariamente no identificadores) debe corresponder necesariamente (y, además, el único) valor de la clave primaria de la clase de entidad padre. Y en el último caso, debido al hecho de que el valor de la clave foránea puede ser igual al valor Nulo (el FK: indicador de validez nula), la multiplicidad se establece en "no más de uno" en el extremo principal de la relación. Continuamos con nuestro análisis. En el extremo secundario de la conexión, en todos los casos, excepto en el primero, la multiplicidad se establece en "varios". Esto se debe a que, debido a una identificación incompleta, como en el segundo caso (o ninguna identificación, en el segundo y tercer caso), el valor de la clave principal de la clase de entidad principal puede aparecer repetidamente entre los valores. de la clave foránea de la clase secundaria. Y en el primer caso, la relación es de identificación total, por lo que los atributos de la clave principal de la clase de entidad principal solo pueden aparecer una vez entre los atributos de las claves de la clase de entidad secundaria. Lección No. 12. Relaciones de clases de entidades Entonces, todos los conceptos por los que hemos pasado, a saber, diagramas y sus tipos, multiplicidades y tipos de relaciones, así como tipos de migración clave, ahora nos ayudarán a revisar el material sobre las mismas relaciones, pero ya entre clases específicas de entidades. Entre ellos, como veremos, también hay conexiones de diversa índole. 1. Relación recursiva jerárquica El primer tipo de relación entre clases de entidad, que consideraremos, es el llamado relación recursiva jerárquica. En general recursividad (o enlace recursivo) es la relación de una clase de entidad consigo misma. A veces, por analogía con las situaciones de la vida, esta conexión también se denomina "anzuelo". Relación recursiva jerárquica (o simplemente recursión jerárquica) es cualquier relación recursiva del tipo "a lo sumo uno a muchos". La recursión jerárquica se usa más comúnmente para almacenar datos en una estructura de árbol. Al especificar una relación recursiva jerárquica, la clave principal de la clase de entidad principal (que en este caso particular también actúa como una clase de entidad secundaria) debe migrarse como una clave externa a los atributos no clave obligatorios de la misma clase de entidad. Todo esto es necesario para mantener la integridad lógica del concepto mismo de "recursión jerárquica". Así, teniendo en cuenta todo lo anterior, podemos concluir que una relación recursiva jerárquica sólo puede ser no necesariamente no identificable y ninguna otra, porque si se usara cualquier otro tipo de relación, los valores Null para la clave foránea no serían válidos y la recursividad sería infinita. También es importante recordar que los atributos no pueden aparecer dos veces en la misma clase de entidad con el mismo nombre. Por lo tanto, los atributos de la clave migrada deben recibir el llamado nombre de rol. Así, en una relación recursiva jerárquica, los atributos de un nodo se amplían con una clave externa que es una referencia opcional a la clave principal del nodo que es su antecesor inmediato. Construyamos una presentación y diagramas clave que implementen la recursividad jerárquica en un modelo de datos relacional, y demos un ejemplo de una forma tabular. Primero creemos un diagrama de presentación:
Ahora construyamos un diagrama clave más detallado:
Considere un ejemplo que ilustra claramente un tipo de relación como una relación recursiva jerárquica. Tengamos la siguiente clase de entidad que, al igual que el ejemplo anterior, consta de los atributos "Código de antepasado" y "Código de nodo". Primero, mostremos una representación tabular de esta clase de entidad:
Ahora construyamos un diagrama que represente esta clase de entidades. Para ello, seleccionamos de la tabla toda la información necesaria para ello: el antepasado del nodo con el código "uno" no existe o no está definido, de esto concluimos que el nodo "uno" es un vértice. El mismo nodo "uno" es el antepasado de los nodos con el código "dos" y "tres". A su vez, el nodo de código "dos" tiene dos hijos: el nodo de código "cuatro" y el nodo de código "cinco". Y el nodo con el código "tres" tiene solo un hijo: el nodo con el código "seis". Entonces, teniendo en cuenta todo lo anterior, construyamos una estructura de árbol que refleje la información sobre los datos contenidos en la tabla anterior:
Entonces, hemos visto que es muy conveniente representar estructuras de árbol usando una relación recursiva jerárquica. 2. Red de comunicación recursiva La conexión recursiva de red de clases de entidades entre sí es, por así decirlo, un análogo multidimensional de la conexión recursiva jerárquica que ya hemos visto. Solo si la recursividad jerárquica se definiera como una relación recursiva de "como máximo uno a muchos", entonces recursión de red representa la misma relación recursiva, solo que del tipo "muchos a muchos". Debido al hecho de que muchas clases de entidades participan en esta conexión en cada lado, se denomina conexión de red. Como ya puedes adivinar por analogía con la recursividad jerárquica, los enlaces del tipo de recursión de red están diseñados para representar estructuras de datos gráficas (mientras que los enlaces jerárquicos se usan, como recordamos, exclusivamente para la implementación de estructuras de árbol). Pero, dado que en la conexión del tipo de red recursiva se especifican las conexiones del tipo "muchos a muchos", es imposible prescindir de sus detalles adicionales. Por lo tanto, para refinar todas las relaciones de muchos a muchos en el esquema, se vuelve necesario crear una nueva clase de entidad independiente que contenga todas las referencias al padre o descendiente de la relación Ascendente-Descendente. Tal clase generalmente se llama clase de entidad asociativa. En nuestro caso particular (en las bases de datos a considerar en nuestro curso), la entidad asociativa no tiene atributos adicionales propios y se denomina vocación, porque nombra las relaciones Ascendente-Descendiente al hacer referencia a ellas. Por lo tanto, la clave principal de la clase de entidad que representa a los hosts debe migrarse dos veces a las clases de entidad asociativas. En esta clase, las claves migradas juntas deben formar una clave principal compuesta. De lo anterior, podemos concluir que establecer enlaces cuando se utiliza la recursividad de la red no debe ser completamente identificativo y nada más. Al igual que cuando se usa una relación recursiva jerárquica, cuando se usa la recursión de red como una relación, ningún atributo puede aparecer dos veces en la misma clase de entidad con el mismo nombre. Por lo tanto, como la última vez, se estipula específicamente que todos los atributos de la clave de migración deben recibir el nombre del rol. Para ilustrar el funcionamiento de la comunicación recursiva de red, construyamos una presentación y diagramas clave que implementen la recursividad de red en un modelo de datos relacional. Comencemos con un diagrama de presentación:
Ahora construyamos un diagrama clave más detallado:
¿Qué vemos aquí? Y vemos que ambas conexiones en este diagrama clave son conexiones de “muchos a uno”. Además, la multiplicidad “0... ∞” o la multiplicidad “muchos” se encuentra al final de la conexión frente a la clase de denominación de entidades. De hecho, hay muchos enlaces, pero todos se refieren a un código de nodo, que es la clave principal de la clase de entidad "Nodos". Y, finalmente, consideremos un ejemplo que ilustra la operación de tal tipo de conexión por una clase de entidad como red recursiva. Tengamos una representación tabular de alguna clase de entidad, así como una clase de entidad de nombres que contenga información sobre enlaces. Echemos un vistazo a estas tablas. Nodos:
Enlaces:
De hecho, la representación anterior es exhaustiva: brinda toda la información necesaria para reproducir fácilmente la estructura gráfica codificada aquí. Por ejemplo, podemos ver sin obstáculos que el nodo con el código "uno" tiene tres hijos, respectivamente, con los códigos "dos", "tres" y "cuatro". También vemos que los nodos con los códigos "dos" y "tres" no tienen ningún descendiente, y un nodo con el código "cuatro" tiene (al igual que el nodo "uno") tres descendientes con los códigos "uno", "dos" y Tres". Dibujemos un gráfico dado por las clases de entidad dadas anteriormente:
Entonces, el gráfico que acabamos de construir son los datos para los cuales las clases de entidad se vincularon mediante una conexión de tipo de recursión de red. 3. Asociación De todos los tipos de conexiones incluidas en la consideración de nuestro curso particular de conferencias, solo dos son conexiones recursivas. Ya hemos logrado considerarlos, estos son enlaces recursivos jerárquicos y de red, respectivamente. Todos los demás tipos de relaciones que tenemos que considerar no son recursivas, pero, como regla, representan una relación de varias clases de entidades principales y varias secundarias. Además, como puede suponer, las clases de entidad padre e hijo ahora nunca coincidirán (de hecho, ya no estamos hablando de recursividad). La conexión, que se discutirá en esta sección de la lección, se llama asociación y se refiere precisamente al tipo de conexiones no recursivas. Así que la conexión llamó asociación, se implementa como una relación entre varias clases de entidad principal y una clase de entidad secundaria. Y al mismo tiempo, lo que es curioso, esta relación se describe por relaciones de varios tipos. También vale la pena señalar que solo puede haber una clase de entidad principal durante la asociación, como en la recursividad de la red, pero incluso en tal situación, el número de relaciones provenientes de la clase de entidad secundaria debe ser al menos dos. Curiosamente, tanto en la asociación como en la recursividad de la red, existen tipos especiales de clases de entidades. Un ejemplo de una clase de este tipo es una clase de entidad secundaria. De hecho, en el caso general, en una asociación, una clase de entidad secundaria se denomina clase de entidad asociativa. En el caso especial en que una clase de entidad asociativa no tiene sus propios atributos adicionales y contiene solo atributos que migran junto con las claves principales de las clases de entidad principal, dicha clase se llama clase de entidades de nombres. Como puede ver, existe una analogía casi absoluta con el concepto de entidades asociativas y nombradas en una conexión recursiva de red. La mayoría de las veces, una asociación se usa para refinar (resolver) relaciones de muchos a muchos. Ilustremos esta afirmación. Dejemos, por ejemplo, que se nos proporcione el siguiente diagrama de presentación, que describe el esquema de recepción de un determinado médico en un determinado hospital:
Este diagrama significa literalmente que hay muchos médicos y muchos pacientes en el hospital, y no existe otra relación ni correspondencia entre médicos y pacientes. Por lo tanto, por supuesto, con una base de datos de este tipo, nunca estaría claro para la administración del hospital cómo programar citas con diferentes médicos para diferentes pacientes. Es claro que las relaciones de muchos a muchos utilizadas aquí simplemente necesitan ser detalladas para concretar la relación entre los distintos médicos y pacientes, en otras palabras, para organizar racionalmente el horario de citas de todos los médicos y sus pacientes en el hospital. Y ahora construyamos un diagrama clave más detallado, en el que ya detallamos todas las relaciones de muchos a muchos existentes. Para hacer esto, introduciremos una nueva clase de entidad en consecuencia, la llamaremos "Recibir", que actuará como una clase de entidad asociativa (más adelante veremos por qué será una clase de entidad asociativa, y no solo una clase de nomenclatura). entidades, de las que hablamos antes). Así que nuestro diagrama clave se verá así:
Entonces, ahora puede ver claramente por qué la nueva clase "Recibir" no es una clase de entidades de nombres. Después de todo, esta clase tiene su propio atributo adicional "Fecha - Hora", por lo tanto, según la definición, la clase "Recepción" recién introducida es una clase de entidades asociativas. Esta clase "asocia" entre sí las clases de entidad "Médicos" y "Pacientes" por medio de la hora en que se realiza tal o cual cita, lo que hace mucho más conveniente trabajar con dicha base de datos. Por lo tanto, al introducir el atributo "Fecha - Hora", organizamos literalmente el horario de trabajo tan necesario para varios médicos. También vemos que la clave principal externa "Código del médico" de la clase de entidad "Recepción" se refiere a la clave principal del mismo nombre de la clase de entidad "Médicos". Y de manera similar, la clave principal externa "Código de paciente" de la clase de entidad "Recepción" se refiere a la clave principal del mismo nombre en la clase de entidad "Paciente". En este caso, por supuesto, las clases de entidad "Médicos" y "Paciente" son el padre, y la clase de entidad asociativa "Recepción", a su vez, es el único hijo. Podemos ver que la relación de muchos a muchos en el diagrama de presentación anterior ahora está completamente detallada. En lugar de la relación de muchos a muchos que vemos en el diagrama de presentación anterior, tenemos dos relaciones de muchos a uno. El extremo secundario de la primera relación tiene la multiplicidad "muchos", lo que literalmente significa que la clase de entidad "Recepción" tiene muchos médicos (todos ellos en el hospital). Y en el extremo padre de esta relación está la multiplicidad de "uno", ¿qué significa esto? Esto significa que en la clase de entidad "Recepción", cada uno de los códigos disponibles de cada médico en particular puede ocurrir indefinidamente muchas veces. De hecho, en el horario del hospital, el código del mismo médico aparece muchas veces, en diferentes días y horas. Y aquí está el mismo código, pero ya en la clase de entidad "Doctores", puede ocurrir una vez y solo una vez. De hecho, en la lista de todos los médicos del hospital (y la clase de entidad "Médicos" no es más que una lista de este tipo), el código de cada médico en particular puede estar presente solo una vez. Algo similar sucede con la relación entre la clase principal "Paciente" y la clase secundaria "Paciente". En la lista de todos los pacientes del hospital (en la clase de entidad "Pacientes"), el código de cada paciente específico solo puede aparecer una vez. Pero por otro lado, en el horario de citas (en la clase de entidad "Recepción"), cada código de un paciente en particular puede ocurrir arbitrariamente muchas veces. Por eso las multiplicidades en los extremos del enlace están dispuestas de esta manera. Como ejemplo de implementación de una asociación en un modelo de datos relacionales, construyamos un modelo que describa el cronograma de reuniones entre el cliente y el contratista con la participación opcional de consultores. No nos detendremos en el diagrama de presentación, porque debemos considerar la construcción de diagramas en todos los detalles, y el diagrama de presentación no puede brindar esa oportunidad. Entonces, construyamos un diagrama clave que refleje la esencia de la relación entre el cliente, el contratista y el consultor.
Entonces, comencemos un análisis detallado del diagrama clave anterior. En primer lugar, la clase "Graph" es una clase de entidades asociativas, pero, como en el ejemplo anterior, no es una clase de entidades con nombre, porque tiene un atributo que no migra a ella junto con las claves, sino que es su atributo propio. Este es el atributo "Fecha - Hora". En segundo lugar, vemos que los atributos de la clase de entidad secundaria "Gráfico", "Código de cliente", "Código de ejecutor" y "Fecha - Hora" forman una clave primaria compuesta de esta clase de entidad. El atributo "Código de asesor" es simplemente una clave externa de la clase de entidad "Gráfico". Tenga en cuenta que este atributo permite valores Null entre sus valores, porque según la condición, no es necesaria la presencia de un consultor en la reunión. Además, en tercer lugar, observamos que los dos primeros enlaces (de los tres enlaces disponibles) no son completamente identificativos. Es decir, no identificar completamente, porque la clave de migración en ambos casos (claves primarias "Código de cliente" y "Código de ejecutor") no forma completamente la clave primaria de la clase de entidad "Gráfico". De hecho, permanece el atributo "Fecha - Hora", que también forma parte de la clave primaria compuesta. En los extremos de estos dos enlaces de identificación incompleta, están marcadas las multiplicidades "uno" y "muchos". Esto se hace para mostrar (como en el ejemplo de médicos y pacientes) la diferencia entre mencionar el código del cliente o el del ejecutante en diferentes clases de entidades. De hecho, en la clase de entidad "Gráfico", cualquier código de cliente o contratista puede aparecer tantas veces como se desee. Por lo tanto, en este, hijo, final de la conexión hay una multiplicidad de "muchos". Y en la clase de entidad "Clientes" o "Contratistas", cada uno de los códigos del cliente o contratista, respectivamente, puede aparecer una y solo una vez, porque estas clases de entidad no son más que una lista completa de todos los clientes y ejecutantes. Por lo tanto, en este extremo principal de la conexión, hay una multiplicidad de "uno". Y, por último, tenga en cuenta que la tercera relación, es decir, la relación de la clase de entidad "Gráfico" con la clase de entidad "Consultores", no es necesariamente no identificable. De hecho, en este caso, estamos hablando de la transferencia del atributo clave "Código de consultor" de la clase de entidad "Consultores" al atributo no clave de la clase de entidad "Gráfico" del mismo nombre, es decir, la clave principal de la clase de entidad "Consultores" en la clase de entidad "Gráfico" ya no identifica la clave principal de esta clase. Y además, como se mencionó anteriormente, el atributo "Advisor Code" permite valores Null, por lo que aquí es precisamente la relación de no identificación la que se utiliza. Por lo tanto, el atributo "Código de asesor" adquiere el estado de una clave externa y nada más. Prestemos también atención a las multiplicidades de enlaces colocados en los extremos padre e hijo de este enlace no identificable por completo. Su extremo padre tiene una multiplicidad de "no más de uno". De hecho, si recordamos la definición de una relación que no es completamente no identificable, entenderemos que el atributo "Código de consultor" de la clase de entidad "Gráfico" no puede corresponder a más de un código de consultor de la lista de todos los consultores. (que es la clase de entidad "Consultores"). Y, en general, puede resultar que no corresponda a ningún código de consultor (recuerde la casilla de verificación de la admisibilidad de valores Nulos Código de consultor: Nulo), porque según la condición, la presencia de un consultor en un la reunión entre el cliente y el contratista, por lo general, no es necesaria. 4. Generalizaciones Otro tipo de relación entre clases de entidad, que consideraremos, es una relación de la forma generalización. También es un tipo de relación no recursiva. Entonces, una relación como generalización se implementa como una relación de una clase de entidad principal con varias clases de entidad secundaria (en contraste con la relación de Asociación anterior, que trataba con varias clases de entidad principal y una clase de entidad secundaria). Al formular reglas de representación de datos utilizando la relación de Generalización, se debe decir de inmediato que esta relación de una clase de entidad principal y varias clases de entidad secundaria se describe mediante relaciones de identificación completa, es decir, relaciones categóricas. Recordando la definición de relaciones de identificación completa, concluimos que cuando se usa la Generalización, cada atributo de la clave principal de la clase de entidad principal se transfiere a la clave principal de las clases de entidad secundaria, es decir, los atributos de la clave migratoria principal de la clase de entidad principal. La clase de entidad forma completamente las claves primarias de todas las clases de entidades secundarias, las identifican. Es curioso notar que la Generalización implementa el llamado jerarquía de categorías o jerarquía de herencia. En este caso, la clase de entidad padre define clase de entidad genérica, caracterizado por atributos comunes a las entidades de todas las clases secundarias o los llamados entidades categóricas es decir, una clase de entidad principal es una generalización literal de todas sus clases de entidad secundaria. Como ejemplo de la implementación de la generalización en un modelo de datos relacionales, construiremos el siguiente modelo. Este modelo se basará en el concepto generalizado de "Estudiantes" y describirá los siguientes conceptos categóricos (es decir, generalizará las siguientes clases de entidades secundarias): "Escuela", "Estudiantes" y "Estudiantes de posgrado". Entonces, construyamos un diagrama clave que refleje la esencia de la relación entre la clase de entidad principal y las clases de entidad secundaria, descrita por una conexión del tipo Generalización.
Entonces ¿Qué vemos? En primer lugar, cada una de las relaciones básicas (o de clases de entidades, que es lo mismo) "Colegiales", "Estudiantes" y "Estudiantes de posgrado" corresponde a sus propios atributos, tales como "Clase", "Curso" y "Año de estudio". " . Cada uno de estos atributos caracteriza a los miembros de su propia clase de entidad. También vemos que la clave principal de la clase de entidad principal "Estudiantes" migra a cada clase de entidad secundaria y forma allí la clave externa principal. Con la ayuda de estas conexiones, podemos determinar por el código de cualquier estudiante su nombre, apellido y patronímico, información sobre la cual no encontraremos en las clases de entidades secundarias correspondientes. En segundo lugar, dado que estamos hablando de una relación de identificación total (o categórica) de clases de entidad, prestaremos atención a la multiplicidad de relaciones entre la clase de entidad principal y sus clases secundarias. El extremo principal de cada uno de estos enlaces tiene una multiplicidad de "uno", y cada extremo secundario de los enlaces tiene una multiplicidad de "como máximo uno". Si recordamos la definición de una relación de identificación completa de clases de entidad, queda claro que el código de estudiante realmente único, que es la clave principal de la clase de entidad "Estudiantes", especifica como máximo un atributo con dicho código en cada entidad secundaria. clase "Estudiante", "Estudiantes" y Postgrados. Por lo tanto, todos los enlaces tienen tales multiplicidades. Escribamos un fragmento de los operadores para crear las relaciones básicas "Colegiales" y "Estudiantes" con la definición de reglas para mantener la integridad referencial del tipo cascada. Entonces tenemos: Crear mesa Alumnos ... clave principal (código de estudiante) referencias de clave externa (ID de estudiante) Estudiantes (ID de estudiante) en cascada de actualización en borrar cascada Crear tabla Estudiantes ... clave principal (código de estudiante) referencias de clave externa (ID de estudiante) Estudiantes (ID de estudiante) en cascada de actualización en eliminar cascada; Por lo tanto, vemos que en la clase de entidad secundaria (o relación) "Estudiante" se especifica una clave externa primaria que se refiere a la clase de entidad principal (o relación) "Estudiantes". La regla en cascada para mantener la integridad referencial determina que cuando los atributos de la clase de entidad principal "Estudiantes" se eliminan o actualizan, los atributos correspondientes de la relación secundaria "Estudiante" se actualizarán o eliminarán automáticamente (en cascada). De manera similar, cuando los atributos de la clase de entidad principal "Estudiantes" se eliminan o actualizan, los atributos correspondientes de la relación secundaria "Estudiantes" también se actualizarán o eliminarán automáticamente. Cabe señalar que es esta regla de integridad referencial la que se utiliza aquí, porque en este contexto (la lista de estudiantes) no es racional prohibir la eliminación y actualización de información, y también asignar un valor indefinido en lugar de información real . Ahora vamos a dar un ejemplo de las clases de entidades descritas en el diagrama anterior, solo presentadas en forma tabular. Entonces, tenemos las siguientes tablas de relaciones: Alumnos - relación principal que combina información sobre los atributos de todas las demás relaciones:
Los escolares - relación hijo:
Estudiantes - relación con el segundo hijo:
estudiantes de doctorado - relación con el tercer hijo:
Entonces, de hecho, vemos que las clases secundarias de entidades no contienen información sobre el apellido, el nombre y el patronímico de los estudiantes, es decir, escolares, estudiantes y estudiantes graduados. Esta información solo se puede obtener a través de referencias a la clase de entidad principal. También vemos que diferentes códigos de estudiante en la clase de entidad "Estudiantes" pueden corresponder a diferentes clases de entidad secundaria. Entonces, sobre el estudiante con el código "1" Nikolai Zabotin, no se sabe nada en la relación de los padres, excepto su nombre, y toda la demás información (quién es, un escolar, estudiante o estudiante graduado) solo se puede encontrar refiriéndose a la clase de entidad secundaria correspondiente (determinada por el código). Del mismo modo, debe trabajar con el resto de los estudiantes, cuyos códigos se especifican en la clase de entidad principal "Estudiantes". 5. Composición La relación de clases de entidad del tipo composición, al igual que las dos anteriores, no pertenece al tipo de relación recursiva. Composición (o, como a veces se le llama, agregación compuesta) es una relación de una sola clase de entidad principal con varias clases de entidad secundaria, al igual que la relación que discutimos anteriormente. Generalización. Pero si la generalización se definió como una relación de clases de entidades descritas mediante relaciones de identificación completa, entonces la composición, a su vez, se describe mediante relaciones de identificación incompletas, es decir, durante la composición, cada atributo de la clave principal de la clase de entidad principal migra al atributo clave. de la clase de entidad secundaria. Y al mismo tiempo, los atributos de la clave de migración solo forman parcialmente la clave principal de la clase de entidad secundaria. Entonces, con la agregación compuesta (con composición), la clase de entidad matriz (o unidad) está asociado con varias clases de entidades secundarias (o componentes). En este caso, los componentes del agregado (es decir, los componentes de la clase de entidad principal) se refieren al agregado a través de una clave externa que forma parte de la clave principal y, por lo tanto, no puede existir fuera del agregado. En general, la agregación compuesta es una forma mejorada de agregación simple (de la que hablaremos un poco más adelante). Una composición (o agregación compuesta) se caracteriza por el hecho de que: 1) la referencia al conjunto está involucrada en la identificación de los componentes; 2) estos componentes no pueden existir fuera del agregado. Una agregación (una relación que consideraremos más adelante) con relaciones necesariamente no identificables tampoco permite que existan componentes fuera del agregado y, por lo tanto, tiene un significado cercano a la implementación de la agregación compuesta descrita anteriormente. Construyamos un diagrama clave que describa la relación entre una clase de entidad principal y varias clases de entidad secundaria, es decir, que describa la relación de las clases de entidad del tipo de agregación compuesta. Sea este un diagrama clave que represente la composición de los edificios de un determinado campus, incluidos los edificios, sus aulas y ascensores. Así que este diagrama se verá así:
Así que echemos un vistazo al diagrama que acabamos de crear. ¿Qué vemos en él? En primer lugar, vemos que la relación utilizada en esta agregación compuesta es, de hecho, identificadora y no completamente identificable. Después de todo, la clave principal de la clase de entidad principal "Edificios" está involucrada en la formación de la clave principal de las clases de entidad secundaria "Público" y "Ascensores", pero no la define por completo. La clave principal "N.º de caso" de la clase de entidad principal migra a las claves principales externas "N.º de caso" de ambas clases secundarias, pero, además de esta clave migrada, ambas clases de entidad secundaria también tienen su propia clave principal, respectivamente "Audiencia". No" y "Número de ascensor", es decir, las claves primarias compuestas de las clases de entidades secundarias son solo atributos formados parcialmente de la clave principal de la clase de entidad principal. Ahora veamos las multiplicidades de enlaces que conectan las clases principal y secundaria. Dado que se trata de vínculos de identificación incompleta, las multiplicidades están presentes: "uno" y "muchos". La multiplicidad "uno" está presente en el extremo padre de ambas relaciones y simboliza que en la lista de todos los corpus disponibles (y la clase de entidad "Corpus" es una lista de este tipo), cada número puede aparecer solo una vez (y no más). que eso) veces. Y, a su vez, entre los atributos de las clases "Audiencia" y "Ascensores", cada número de edificio puede aparecer muchas veces, ya que hay más audiencias (o ascensores) que edificios, y en cada edificio hay varios auditorios y ascensores. Por lo tanto, al enumerar todas las aulas y ascensores, inevitablemente repetiremos los números de los edificios. Y, finalmente, como en el caso del tipo de conexión anterior, anotemos los fragmentos de los operadores para crear relaciones básicas (o, lo que es lo mismo, clases de entidad) "Audiencias" y "Ascensores", y haga esto con la definición de reglas para mantener la integridad referencial del tipo cascada. Así que esta declaración se vería así: Crear tabla Audiencias ... clave principal (número de corpus, número de audiencia) Referencias de clave foránea (número de caso) Patrones (número de caso) en cascada de actualización en borrar cascada Crear elevadores de mesa ... clave principal (número de caso, número de ascensor) Referencias de clave foránea (número de caso) Patrones (número de caso) en cascada de actualización en eliminar cascada; Por lo tanto, hemos establecido todas las claves primarias y externas necesarias de las clases de entidades secundarias. De nuevo tomamos como cascada la regla de mantener la integridad referencial, ya que la hemos descrito como la más racional. Ahora daremos un ejemplo en forma tabular de todas las clases de entidades que acabamos de considerar. Describamos esas relaciones básicas que hemos reflejado con la ayuda de un diagrama en forma de tablas, y para mayor claridad, introduciremos allí una cierta cantidad de datos indicativos. Conchas La relación de los padres se ve así:
Audiencia - clase de entidad secundaria:
Ascensores - la segunda clase de entidad secundaria de la clase principal "Enclosures":
Entonces, podemos ver cómo se organiza la información de todos los edificios, sus aulas y ascensores en esta base de datos, que puede ser utilizada por cualquier institución educativa de la vida real. 6. Agregación La agregación es el último tipo de relación entre clases de entidades que se considerará como parte de nuestro curso. Tampoco es recursivo, y uno de sus dos tipos tiene un significado bastante cercano a la agregación compuesta considerada anteriormente. Por lo tanto, agregación es la relación de una clase de entidad principal con varias clases de entidad secundaria. En este caso, la relación se puede describir mediante dos tipos de relaciones: 1) enlaces necesariamente no identificativos; 2) enlaces no identificativos opcionales. Recuerde que con relaciones necesariamente no identificables, algunos atributos de la clave principal de la clase de entidad principal se transfieren a un atributo que no es clave de la clase secundaria, y se prohíben los valores nulos para todos los atributos de la clave de migración. Y con relaciones no necesariamente no identificables, la migración de claves primarias ocurre exactamente de acuerdo con el mismo principio, pero se permiten valores nulos para algunos atributos de la clave de migración. Al agregar, la clase de entidad matriz (o unidad) está asociado con varias clases de entidades secundarias (o componentes). Los componentes del agregado (es decir, la clase de entidad matriz) se refieren al agregado a través de una clave externa que no forma parte de la clave principal y, por lo tanto, en el caso no necesariamente relaciones no identificables, los componentes agregados pueden existir fuera del agregado. En el caso de agregación con relaciones necesariamente no identificables, no se permite que los componentes del agregado existan fuera del agregado y, en este sentido, la agregación con relaciones necesariamente no identificables está cerca de la agregación compuesta. Ahora que ha quedado claro qué es una relación de tipo de agregación, construyamos un diagrama clave que describa el funcionamiento de esta relación. Deje que nuestro diagrama futuro describa los componentes marcados de los automóviles (a saber, el motor y el chasis). Al mismo tiempo, supondremos que el desmantelamiento del automóvil implica el desmantelamiento del chasis junto con él, pero no implica el desmantelamiento simultáneo del motor. Así que nuestro diagrama clave se ve así:
Entonces, ¿qué vemos en este diagrama clave? En primer lugar, la relación de la clase de entidad principal "Cars" con la clase de entidad secundaria "Motores" no es necesariamente no identificable, porque el atributo "car #" permite valores nulos entre sus valores. A su vez, este atributo permite Null-values por el hecho de que el desmantelamiento del motor, por condición, no depende del desmantelamiento de todo el vehículo y, por lo tanto, no necesariamente ocurre al desmantelamiento de un automóvil. También vemos que la clave principal "Motor #" de la clase de entidad "Autos" migra al atributo no clave "Motor #" de la clase de entidad "Motores". Y al mismo tiempo, este atributo adquiere el estatus de clave foránea. Y la clave principal en esta clase de entidad Engines es el atributo Engine Marker, que no hace referencia a ningún atributo de la relación principal. En segundo lugar, la relación entre la clase de entidad principal "Motores" y la clase de entidad secundaria "Chasis" es necesariamente una relación no identificable, porque el atributo de clave externa "Coche #" no permite valores nulos entre sus valores. Esto, a su vez, ocurre porque se conoce por la condición de que el desmantelamiento del automóvil implica el desmantelamiento simultáneo obligatorio del chasis. Aquí, al igual que en el caso de la relación anterior, la clave principal de la clase de entidad principal "Motores" se migra al atributo no clave "Número de automóvil" de la clase de entidad secundaria "Chasis". Al mismo tiempo, la clave principal de esta clase de entidad es el atributo "Chassis Marker", que no hace referencia a ningún atributo de la relación principal "Motors". Siga adelante. Para la mejor asimilación del tema, escribamos nuevamente los fragmentos de los operadores para crear las relaciones básicas "Motores" y "Chasis" con la definición de reglas para mantener la integridad referencial. Crear motores de tabla ... clave principal (marcador de motor) referencias de clave foránea (número de vehículo) Coches (número de vehículo) en cascada de actualización en eliminar establecer Nulo Crear mesa Chasis ... clave principal (marcador de chasis) referencias de clave foránea (número de vehículo) Coches (número de vehículo) en cascada de actualización en eliminar cascada; Vemos que usamos la misma regla para mantener la integridad referencial en todas partes: cascada, ya que incluso antes la reconocimos como la más racional de todas. Sin embargo, esta vez usamos (además de la regla en cascada) la regla de integridad referencial establecida en Nulo. Además, lo usamos bajo la siguiente condición: si se elimina algún valor de la clave principal "Número de automóvil" de la clase de entidad principal "Automóviles", entonces el valor de la clave externa "Número de automóvil" de la relación secundaria "Motores" refiriéndose a él se le asignará un valor nulo. 7. Unificación de atributos Si, durante la migración de claves primarias de una determinada clase de entidad principal, los atributos de diferentes clases principales que coinciden en significado entran en la misma clase secundaria, entonces estos atributos deben "fusionarse", es decir, es necesario llevar a cabo el proceso. -llamado unificación de atributos. Por ejemplo, en el caso de que un empleado pueda trabajar en una organización, estando listado en no más de un departamento, después de unificar el atributo "Código de la organización", obtenemos el siguiente diagrama clave:
Al migrar la clave principal de las clases de entidad principal "Organización" y "Departamentos" a la clase secundaria "Empleados", el atributo "ID de la organización" ingresa a la clase de entidad "Empleados". Y dos veces: 1) primera vez con marcador PFK de la clase de entidad "Organización" al establecer una relación de identificación incompleta; 2) y la segunda vez, con el marcador FK con la condición de aceptar valores Null de la clase de entidad "Departamentos" al establecer una relación no necesariamente no identificatoria. Cuando se unifica, el atributo "ID de la organización" adquiere el estado de un atributo de clave principal/foránea, absorbiendo el estado del atributo de clave externa. Construyamos un nuevo diagrama clave que demuestre el proceso de unificación en sí:
Así, se produjo la unificación de atributos. Conferencia N° 13. Sistemas expertos y modelo de producción de conocimiento 1. Designación de sistemas expertos Para familiarizarse con un concepto tan nuevo para nosotros como sistemas expertos nosotros, para empezar, repasaremos la historia de la creación y el desarrollo de la dirección de "sistemas expertos", y luego definiremos el concepto mismo de sistemas expertos. A principios de los 80. siglo XNUMX en la investigación sobre la creación de inteligencia artificial, se ha formado una nueva dirección independiente, llamada sistemas expertos. El propósito de esta nueva investigación sobre sistemas expertos es desarrollar programas especiales diseñados para resolver tipos específicos de problemas. ¿Cuál es este tipo especial de problema que requirió la creación de una ingeniería del conocimiento completamente nueva? Este tipo especial de tareas puede incluir tareas de absolutamente cualquier área temática. Lo principal que los distingue de los problemas ordinarios es que parece ser una tarea muy difícil para un experto humano resolverlos. Entonces el primero de los llamados Experto en Sistemas (donde el papel de un experto ya no era una persona, sino una máquina), y el sistema experto recibe resultados que no son inferiores en calidad y eficiencia a las soluciones obtenidas por una persona común: un experto. Los resultados del trabajo de los sistemas expertos se pueden explicar al usuario a un nivel muy alto. Esta cualidad de los sistemas expertos está asegurada por su capacidad de razonar sobre su propio conocimiento y conclusiones. Los sistemas expertos bien pueden reponer su propio conocimiento en el proceso de interacción con un experto. Por lo tanto, se pueden poner con total confianza a la par de una inteligencia artificial completamente formada. Los investigadores en el campo de los sistemas expertos para el nombre de su disciplina a menudo también usan el término mencionado anteriormente "ingeniería del conocimiento", introducido por el científico alemán E. Feigenbaum como "traer los principios y herramientas de investigación del campo de la inteligencia artificial para resolver problemas aplicados difíciles que requieren conocimiento experto". Sin embargo, el éxito comercial de las empresas de desarrollo no llegó de inmediato. Durante un cuarto de siglo desde 1960 hasta 1985. Los éxitos de la inteligencia artificial han estado relacionados principalmente con desarrollos de investigación. Sin embargo, a partir de alrededor de 1985, y de forma masiva desde 1987 hasta 1990. Los sistemas expertos se han utilizado activamente en aplicaciones comerciales. Los méritos de los sistemas expertos son bastante grandes y son los siguientes: 1) la tecnología de sistemas expertos amplía significativamente la gama de tareas prácticamente significativas resueltas en computadoras personales, cuya solución brinda importantes beneficios económicos y simplifica enormemente todos los procesos relacionados; 2) la tecnología de sistemas expertos es una de las herramientas más importantes para resolver los problemas globales de la programación tradicional, como la duración, la calidad y, en consecuencia, el alto costo de desarrollar aplicaciones complejas, por lo que el efecto económico se redujo significativamente ; 3) existe un alto costo de operación y mantenimiento de sistemas complejos, que a menudo supera en varias veces el costo del desarrollo en sí mismo, así como un bajo nivel de reutilización de programas, etc.; 4) la combinación de la tecnología de sistemas expertos con la tecnología de programación tradicional agrega nuevas cualidades a los productos de software, en primer lugar, al permitir la modificación dinámica de las aplicaciones por parte de un usuario común y no de un programador; en segundo lugar, mayor “transparencia” de la aplicación, mejores gráficos, interfaz e interacción de sistemas expertos. Según los usuarios comunes y los principales expertos, en un futuro próximo, los sistemas expertos encontrarán las siguientes aplicaciones: 1) los sistemas expertos desempeñarán un papel de liderazgo en todas las etapas de diseño, desarrollo, producción, distribución, depuración, control y prestación de servicios; 2) la tecnología de sistemas expertos, que ha recibido una amplia distribución comercial, proporcionará un avance revolucionario en la integración de aplicaciones a partir de módulos interactivos inteligentes listos para usar. En general, los sistemas expertos están diseñados para los llamados tareas informales, es decir, los sistemas expertos no rechazan ni reemplazan el enfoque tradicional de desarrollo de programas centrado en la solución de problemas formalizados, sino que los complementan, ampliando significativamente las posibilidades. Esto es exactamente lo que un mero experto humano no puede hacer. Tales tareas complejas no formalizadas se caracterizan por: 1) falacia, inexactitud, ambigüedad, así como incompletitud e inconsistencia de los datos de origen; 2) falacia, ambigüedad, inexactitud, incompletitud e inconsistencia del conocimiento sobre el área del problema y el problema que se está resolviendo; 3) gran dimensión del espacio de soluciones de un problema específico; 4) la variabilidad dinámica de los datos y el conocimiento directamente en el proceso de resolución de un problema tan informal. Los sistemas expertos se basan principalmente en la búsqueda heurística de una solución, y no en la ejecución de un algoritmo conocido. Esta es una de las principales ventajas de la tecnología de sistemas expertos sobre el enfoque tradicional del desarrollo de software. Esto es lo que les permite hacer frente tan bien a las tareas que se les asignan. La tecnología de sistemas expertos se utiliza para resolver una variedad de problemas. Enumeramos las principales de estas tareas. 1. Interpretación. Los sistemas expertos que realizan la interpretación suelen utilizar las lecturas de varios instrumentos para describir el estado de cosas. Los sistemas expertos interpretativos son capaces de procesar una variedad de tipos de información. Un ejemplo es el uso de datos de análisis espectral y cambios en las características de las sustancias para determinar su composición y propiedades. También un ejemplo es la interpretación de las lecturas de los instrumentos de medición en la sala de calderas para describir el estado de las calderas y el agua en ellas. Los sistemas interpretativos suelen tratar directamente con indicaciones. En este sentido, surgen dificultades que otro tipo de sistemas no tienen. ¿Cuáles son estas dificultades? Estas dificultades surgen debido a que los sistemas expertos deben interpretar información superflua, incompleta, poco fiable o incorrecta. Por lo tanto, los errores o un aumento significativo en el procesamiento de datos son inevitables. 2. Predicción. Los sistemas expertos que realizan un pronóstico de algo determinan las condiciones probabilísticas de situaciones dadas. Ejemplos son el pronóstico de daños causados a la cosecha de granos por condiciones climáticas adversas, la evaluación de la demanda de gas en el mercado mundial, el pronóstico del tiempo según estaciones meteorológicas. Los sistemas de pronóstico a veces usan modelado, es decir, programas que muestran algunas relaciones en el mundo real para recrearlas en un entorno de programación y luego diseñar situaciones que pueden surgir con ciertos datos iniciales. 3. Diagnóstico de varios dispositivos.. Los sistemas expertos realizan tales diagnósticos utilizando descripciones de cualquier situación, comportamiento o datos sobre la estructura de varios componentes para determinar las posibles causas de un mal funcionamiento del sistema diagnosticable. Son ejemplos el establecimiento de las circunstancias de la enfermedad por los síntomas que se observan en los pacientes (en medicina); identificación de fallas en circuitos electrónicos e identificación de componentes defectuosos en los mecanismos de varios dispositivos. Los sistemas de diagnóstico suelen ser asistentes que no solo realizan un diagnóstico, sino que también ayudan a solucionar problemas. En tales casos, estos sistemas bien pueden interactuar con el usuario para ayudar en la solución de problemas y luego proporcionar una lista de acciones necesarias para resolverlos. Actualmente, muchos sistemas de diagnóstico se están desarrollando como aplicaciones a la ingeniería y los sistemas informáticos. 4. Planificación de varios eventos.. Sistemas expertos diseñados para la planificación del diseño de diversas operaciones. Los sistemas predeterminan una secuencia casi completa de acciones antes de que comience su implementación. Ejemplos de tal planificación de eventos son la creación de planes para operaciones militares, tanto defensivas como ofensivas, predeterminadas por un período determinado para obtener una ventaja sobre las fuerzas enemigas. 5. diseño. Los sistemas expertos que realizan el diseño desarrollan diversas formas de objetos, teniendo en cuenta las circunstancias predominantes y todos los factores relacionados. Un ejemplo es la ingeniería genética. 6. Controle. Los sistemas expertos que ejercen el control comparan el comportamiento actual del sistema con su comportamiento esperado. Los sistemas expertos de observación detectan un comportamiento controlado que confirma sus expectativas frente al comportamiento normal o su suposición de posibles desviaciones. Los sistemas expertos de control, por su propia naturaleza, deben trabajar en tiempo real e implementar una interpretación dependiente del tiempo y del contexto del comportamiento del objeto controlado. Los ejemplos incluyen monitorear las lecturas de instrumentos de medición en reactores nucleares para detectar emergencias o evaluar datos de diagnóstico de pacientes en la unidad de cuidados intensivos. 7. Управление. Después de todo, es ampliamente conocido que los sistemas expertos que ejercen control manejan de manera muy efectiva el comportamiento del sistema como un todo. Un ejemplo es la gestión de diversas industrias, así como la distribución de sistemas informáticos. Los sistemas expertos de control deben incluir componentes de observación para controlar el comportamiento de un objeto durante un largo período de tiempo, pero también pueden necesitar otros componentes del tipo de tareas ya analizadas. Los sistemas expertos se utilizan en varios campos: transacciones financieras, industria del petróleo y el gas. La tecnología de sistemas expertos también se puede aplicar en energía, transporte, industria farmacéutica, desarrollo espacial, industrias metalúrgica y minera, química y muchas otras áreas. 2. Estructura de los sistemas expertos El desarrollo de sistemas expertos tiene una serie de diferencias significativas con el desarrollo de un producto de software convencional. La experiencia de creación de sistemas expertos ha demostrado que el uso de la metodología adoptada en la programación tradicional en su desarrollo, o bien aumenta mucho el tiempo dedicado a la creación de sistemas expertos, o incluso conduce a un resultado negativo. Los sistemas expertos generalmente se dividen en estática и dinámico. Primero, considere un sistema experto estático. estándar sistema experto estático consta de los siguientes componentes principales: 1) memoria de trabajo, también llamada base de datos; 2) bases de conocimiento; 3) un solucionador, también llamado intérprete; 4) componentes de adquisición de conocimiento; 5) componente explicativo; 6) componente de diálogo. Consideremos ahora cada componente con más detalle. memoria de trabajo (por analogía absoluta con el trabajo, es decir, la memoria RAM de la computadora) está diseñado para recibir y almacenar los datos iniciales e intermedios de la tarea que se está resolviendo en el momento actual. Base de Conocimiento está diseñado para almacenar datos a largo plazo que describen un área temática específica y reglas que describen la transformación racional de los datos en esta área del problema que se está resolviendo. Solucionadortambién llamado Interprete, funciona de la siguiente manera: utilizando los datos iniciales de la memoria de trabajo y los datos a largo plazo de la base de conocimientos, forma las reglas, cuya aplicación a los datos iniciales conduce a la solución del problema. En una palabra, realmente "resuelve" el problema que se le presenta; Componente de Adquisición de Conocimiento automatiza el proceso de llenar el sistema experto con conocimiento experto, es decir, es este componente el que proporciona a la base de conocimiento toda la información necesaria de esta área temática en particular. Explicar componente explica cómo el sistema obtuvo una solución a este problema, o por qué no recibió esta solución, y qué conocimiento utilizó para hacerlo. En otras palabras, el componente de explicación genera un informe de progreso. Este componente es muy importante en todo el sistema experto, ya que facilita enormemente la prueba del sistema por parte de un experto, y además aumenta la confianza del usuario en el resultado obtenido y, por tanto, agiliza el proceso de desarrollo. Componente de diálogo sirve para proporcionar una interfaz de usuario amigable tanto en el curso de la resolución de un problema como en el proceso de adquisición de conocimientos y declaración de los resultados del trabajo. Ahora que sabemos en qué componentes consiste generalmente un sistema experto estadístico, construyamos un diagrama que refleje la estructura de dicho sistema experto. Se parece a esto:
Los sistemas expertos estáticos se utilizan con mayor frecuencia en aplicaciones técnicas en las que es posible no tener en cuenta los cambios en el entorno que se producen durante la solución de un problema. Es curioso saber que los primeros sistemas expertos que recibieron aplicación práctica fueron precisamente estáticos. Entonces, con esto terminaremos la consideración del sistema experto estadístico por ahora, pasemos al análisis del sistema experto dinámico. Desafortunadamente, el programa de nuestro curso no incluye una consideración detallada de este sistema experto, por lo que nos limitaremos a analizar solo las diferencias más básicas entre un sistema experto dinámico y uno estático. A diferencia de un sistema experto estático, la estructura sistema experto dinámico Además, se introducen los siguientes dos componentes: 1) un subsistema para modelar el mundo exterior; 2) un subsistema de relaciones con el medio externo. Subsistema de relaciones con el medio exterior Simplemente hace conexiones con el mundo exterior. Ella hace esto a través de un sistema de sensores y controladores especiales. Además, algunos componentes tradicionales de un sistema experto estático sufren cambios significativos para reflejar la lógica temporal de los eventos que ocurren actualmente en el entorno. Esta es la principal diferencia entre los sistemas expertos estáticos y dinámicos. Un ejemplo de un sistema experto dinámico es la gestión de la producción de varios medicamentos en la industria farmacéutica. 3. Participantes en el desarrollo de sistemas expertos Representantes de varias especialidades están involucrados en el desarrollo de sistemas expertos. La mayoría de las veces, un sistema experto específico es desarrollado por tres especialistas. Esto suele ser: 1) experto; 2) ingeniero del conocimiento; 3) un programador para el desarrollo de herramientas. Expliquemos las responsabilidades de cada uno de los especialistas enumerados aquí. Experto es un especialista en el área temática, cuyas tareas se resolverán con la ayuda de este sistema experto en particular que se está desarrollando. Ingeniero del conocimiento es especialista en el desarrollo de un sistema experto de forma directa. Las tecnologías y métodos utilizados por él se denominan tecnologías y métodos de ingeniería del conocimiento. Un ingeniero de conocimiento ayuda a un experto a identificar de toda la información en el área temática la información que es necesaria para trabajar con un sistema experto en particular que se está desarrollando y luego estructurarlo. Es curioso que la ausencia de ingenieros del conocimiento entre los participantes en el desarrollo, es decir, su reemplazo por programadores, lleve al fracaso de todo el proyecto de creación de un sistema experto específico, o aumente significativamente el tiempo para su desarrollo. Y, finalmente, programador desarrolla herramientas (si las herramientas son nuevas) diseñadas para acelerar el desarrollo de sistemas expertos. Estas herramientas contienen, en el límite, todos los componentes principales de un sistema experto; el programador también interconecta sus herramientas con el entorno en el que se utilizará. 4. Modos de funcionamiento de los sistemas expertos El sistema experto opera en dos modos principales: 1) en el modo de adquirir conocimiento; 2) en el modo de resolución del problema (también llamado modo de consultas, o modo de uso del sistema experto). Esto es lógico y comprensible, porque primero es necesario, por así decirlo, cargar el sistema experto con información del área temática en la que tiene que trabajar, este es el modo de "entrenamiento" del sistema experto, el modo cuando recibe conocimiento. Y después de cargar toda la información necesaria para el trabajo, sigue el trabajo en sí. El sistema experto queda listo para funcionar y ahora se puede utilizar para consultas o para resolver cualquier problema. Consideremos con más detalle modo de adquisición de conocimiento. En la modalidad de adquisición de conocimiento, el trabajo con el sistema experto lo realiza un experto a través de un ingeniero del conocimiento. En este modo, el experto, utilizando el componente de adquisición de conocimiento, llena el sistema con conocimiento (datos), lo que, a su vez, permite que el sistema resuelva problemas de esta materia en el modo de solución sin la participación de un experto. Cabe señalar que el modo de adquisición de conocimiento en el enfoque tradicional de desarrollo de programas corresponde a las etapas de algoritmización, programación y depuración realizadas directamente por el programador. De ello se deduce que, a diferencia del enfoque tradicional, en el caso de los sistemas expertos, el desarrollo de programas no lo lleva a cabo un programador, sino un experto, por supuesto, con la ayuda de sistemas expertos, es decir, en general. , una persona que no sabe programar. Y ahora consideremos el segundo modo de funcionamiento del sistema experto, es decir. modo de resolución de problemas. En el modo de resolución de problemas (o el llamado modo de consulta), la comunicación con los sistemas expertos la realiza directamente el usuario final, que se interesa por el resultado final del trabajo y, en ocasiones, por la forma de obtenerlo. Cabe señalar que, dependiendo del propósito del sistema experto, el usuario no tiene que ser un experto en esta área problemática. En este caso recurre a los sistemas expertos para el resultado, al no tener los conocimientos suficientes para obtener resultados. O bien, el usuario aún puede tener un nivel de conocimiento suficiente para lograr el resultado deseado por su cuenta. En este caso, el usuario puede obtener el resultado por sí mismo, pero recurre a los sistemas expertos para acelerar el proceso de obtención del resultado o para asignar un trabajo monótono a los sistemas expertos. En el modo de consulta, los datos sobre la tarea del usuario, luego de ser procesados por el componente de diálogo, ingresan a la memoria de trabajo. El solucionador, basado en datos de entrada de la memoria de trabajo, datos generales sobre el área del problema y reglas de la base de datos, genera una solución al problema. Al resolver un problema, los sistemas expertos no solo ejecutan la secuencia prescrita de una operación específica, sino que también la forman preliminarmente. Esto se hace en el caso de que la reacción del sistema no sea del todo clara para el usuario. En esta situación, el usuario puede requerir una explicación de por qué este sistema experto hace una pregunta en particular o por qué este sistema experto no puede realizar esta operación, cómo se obtiene este o aquel resultado proporcionado por este sistema experto. 5. Modelo de producción de conocimiento En su esencia, modelos de producción de conocimiento cerca de modelos lógicos, lo que le permite organizar procedimientos muy efectivos para la inferencia de datos lógicos. Esto es por un lado. Sin embargo, por otro lado, si consideramos los modelos de producción de conocimiento en comparación con los modelos lógicos, entonces los primeros muestran más claramente el conocimiento, lo que es una ventaja indiscutible. Por tanto, sin duda, el modelo de producción de conocimiento es uno de los principales medios de representación del conocimiento en los sistemas de inteligencia artificial. Entonces, comencemos una consideración detallada del concepto de un modelo de producción de conocimiento. El modelo tradicional de producción de conocimiento incluye los siguientes componentes básicos: 1) un conjunto de reglas (o producciones) que representan la base de conocimiento del sistema de producción; 2) memoria de trabajo, que almacena los hechos originales, así como los hechos derivados de los hechos originales utilizando el mecanismo de inferencia; 3) el propio mecanismo de inferencia lógica, que permite, a partir de los hechos disponibles, según las reglas de inferencia existentes, derivar nuevos hechos. Y, curiosamente, el número de tales operaciones puede ser infinito. Cada regla que representa la base de conocimientos del sistema de producción contiene una parte condicional y otra final. La parte condicional de la regla contiene un solo hecho o varios hechos conectados por una conjunción. La parte final de la regla contiene hechos que deben reponerse con la memoria de trabajo si la parte condicional de la regla es verdadera. Si tratamos de representar esquemáticamente el modelo de producción de conocimiento, entonces la producción se entiende como una expresión de la siguiente forma: (i) Q; PAG; A→B; NORTE; Aquí i es el nombre del modelo de producción de conocimiento o su número de serie, con la ayuda de la cual esta producción se distingue de todo el conjunto de modelos de producción, recibiendo algún tipo de identificación. Alguna unidad léxica que refleje la esencia de este producto puede actuar como nombre. De hecho, nombramos productos para una mejor percepción por parte de la conciencia, para simplificar la búsqueda del producto deseado de la lista. Pongamos un ejemplo sencillo: comprar una libreta" o "un juego de lápices de colores". Obviamente, cada producto se suele denominar con palabras adecuadas para el momento. En otras palabras, llama a las cosas por su nombre. Siga adelante. El elemento Q caracteriza el alcance de este modelo particular de producción de conocimiento. Tales esferas se distinguen fácilmente en la mente humana, por lo tanto, como regla, no hay dificultades con la definición de este elemento. Tomemos un ejemplo. Consideremos la siguiente situación: digamos que en un área de nuestra conciencia se almacena el conocimiento de cómo cocinar los alimentos, en otra, cómo llegar al trabajo, en la tercera, cómo operar correctamente la lavadora. Una división similar también está presente en la memoria del modelo de producción de conocimiento. Esta división del conocimiento en áreas separadas puede ahorrar significativamente el tiempo dedicado a buscar algunos modelos específicos de producción de conocimiento que se necesitan en este momento y, por lo tanto, simplifica enormemente el proceso de trabajar con ellos. Por supuesto, el elemento principal de la producción es su llamado núcleo, que en nuestra fórmula anterior se denota como A → B. Esta fórmula puede interpretarse como "si se cumple la condición A, entonces se debe realizar la acción B". Si estamos tratando con construcciones de kernel más complejas, entonces se permite la siguiente opción alternativa en el lado derecho: "si se cumple la condición A, entonces se debe realizar la acción B".1, de lo contrario, debe realizar la acción B2". Sin embargo, la interpretación del núcleo del modelo de producción de conocimiento puede ser diferente y depender de lo que estará a la izquierda ya la derecha del signo secuencial "→". Con una de las interpretaciones del núcleo del modelo de producción de conocimiento, el consecuente puede interpretarse en el sentido lógico habitual, es decir, como un signo de la consecuencia lógica de la acción B de la condición verdadera A. Sin embargo, también son posibles otras interpretaciones del núcleo del modelo de producción de conocimiento. Así, por ejemplo, A puede describir alguna condición, cuyo cumplimiento es necesario para que se realice alguna acción B. A continuación, consideramos un elemento del modelo de producción de conocimiento R. Elemento Р se define como una condición para la aplicabilidad del núcleo del producto. Si la condición P es verdadera, entonces se activa el núcleo de producción. De lo contrario, si la condición P no se cumple, es decir, es falsa, el núcleo no se puede activar. Como ejemplo ilustrativo, considere el siguiente modelo de producción de conocimiento: "Disponibilidad de dinero"; "Si desea comprar la cosa A, debe pagar su costo al cajero y presentar el cheque al vendedor". Miramos, si la condición P es verdadera, es decir, se paga la compra y se presenta el cheque, entonces se activa el núcleo. Compra completada. Si en este modelo de producción de conocimiento la condición de aplicabilidad del núcleo es falsa, es decir, si no hay dinero, entonces es imposible aplicar el núcleo del modelo de producción de conocimiento, y no se activa. Y finalmente ir al elemento. N. El elemento N se denomina condición posterior del modelo de datos de producción. La postcondición define las acciones y procedimientos que se deben realizar después de la implementación del núcleo de producción. Para una mejor percepción, pongamos un ejemplo sencillo: después de comprar una cosa en una tienda, es necesario reducir en uno el número de cosas de este tipo en el inventario de mercancías de esta tienda, es decir, si se realiza la compra (por lo tanto , se vende el núcleo), entonces la tienda tiene una unidad menos de este producto en particular. De ahí la condición posterior "Tachar la unidad del artículo comprado". Resumiendo, podemos decir que la representación del conocimiento como un conjunto de reglas, es decir, mediante el uso de un modelo de producción de conocimiento, tiene las siguientes ventajas: 1) es la facilidad de crear y comprender reglas individuales; 2) es la simplicidad del mecanismo de elección lógica. Sin embargo, en la representación del conocimiento en forma de conjunto de reglas, también existen desventajas que aún limitan el alcance y la frecuencia de aplicación de los modelos de producción de conocimiento. La principal desventaja de este tipo es la ambigüedad de las relaciones mutuas entre las reglas que componen un modelo específico de producción de conocimiento, así como las reglas de elección lógica. Notas 1. La fuente subrayada en la edición impresa del libro corresponde a negrita cursiva en esta versión (electrónica) del libro. (Aprox. e. ed.)
▪ Terapia hospitalaria. Notas de lectura
Máquina para aclarar flores en jardines.
02.05.2024 Microscopio infrarrojo avanzado
02.05.2024 Trampa de aire para insectos.
01.05.2024
▪ El cambio climático podría causar alergias permanentes ▪ Centro multimedia Jaguar InControl ▪ Discos duros de helio HGST Ultrastar He de 6 TB ▪ Conmutadores de antena en miniatura para teléfonos móviles
▪ sección del sitio Casa, parcelas familiares, pasatiempos. Selección de artículos ▪ artículo Rumbo preciso con cualquier viento. Consejos para un modelador ▪ artículo ¿Dónde comenzó la extracción de oro? Respuesta detallada ▪ artículo Carpintero. Instrucción estándar sobre protección laboral
Hogar | Biblioteca | Artículos | Mapa del sitio | Revisiones del sitio
www.diagrama.com.ua |



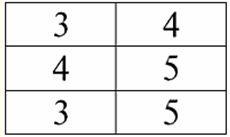

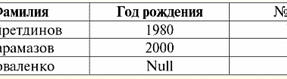

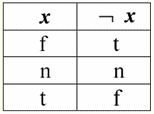

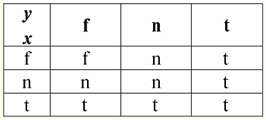
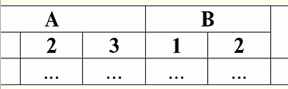


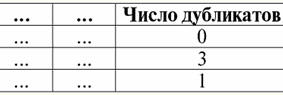
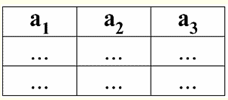






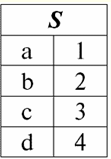
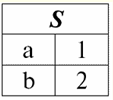

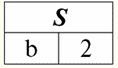
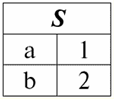

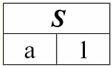
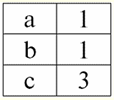

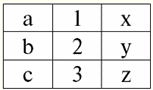









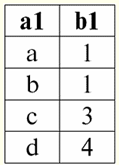






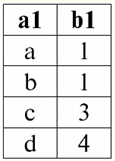



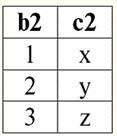

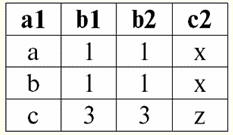




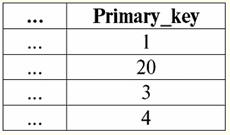

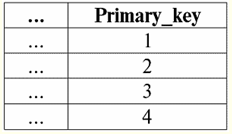

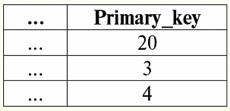
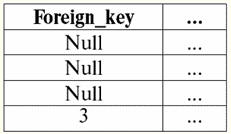

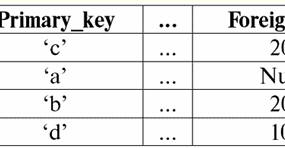












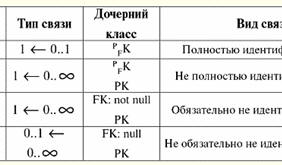









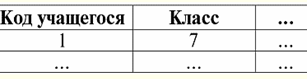
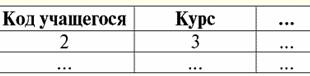





 Ver otros artículos sección
Ver otros artículos sección 