|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese|
Notas de clase, hojas de trucos
Informática y tecnologías de la información. Hoja de trucos: brevemente, lo más importante
Directorio / Notas de clase, hojas de trucos tabla de contenidos
1. Informática. Información Representación y tratamiento/información. Sistemas numéricos La informática se dedica a una representación formalizada de objetos y estructuras de sus relaciones en varios campos de la ciencia, la tecnología y la producción. Se utilizan varias herramientas formales para modelar objetos y fenómenos, como fórmulas lógicas, estructuras de datos, lenguajes de programación, etc. En informática, un concepto tan fundamental como el de información tiene varios significados: 1) presentación formal de formas externas de información; 2) significado abstracto de la información, su contenido interno, semántica; 3) relación de la información con el mundo real. Pero, por regla general, la información se entiende como su significado abstracto: la semántica. Si queremos intercambiar información, necesitamos puntos de vista consistentes para que no se viole la corrección de la interpretación. Para ello, la interpretación de la representación de la información se identifica con unas estructuras matemáticas. En este caso, el procesamiento de la información se puede realizar mediante métodos matemáticos rigurosos. Una de las descripciones matemáticas de la información es su representación como una función. y = f(x,t) donde t es el tiempo, x es un punto en algún campo donde se mide el valor de y. Dependiendo de los parámetros de función x y t, la información se puede clasificar. Si los parámetros son cantidades escalares que toman una serie continua de valores, entonces la información así obtenida se denomina continua (o analógica). Si a los parámetros se les da un cierto paso de cambio, entonces la información se llama discreta. La información discreta se considera universal. La información discreta suele identificarse con la información digital, que es un caso especial de información simbólica de representación alfabética. Un alfabeto es un conjunto finito de símbolos de cualquier naturaleza. Muy a menudo en informática surge una situación en la que los caracteres de un alfabeto deben ser representados por los caracteres de otro, es decir, para realizar una operación de codificación. Como ha demostrado la práctica, el alfabeto más simple que le permite codificar otros alfabetos es el binario, que consta de dos caracteres, que generalmente se denotan con 0 y 1. Usando n caracteres del alfabeto binario, puede codificar 2n caracteres, y esto es suficiente para codificar cualquier alfabeto. El valor que puede ser representado por un símbolo del alfabeto binario se denomina unidad mínima de información o bit. Secuencia de 8 bits - bytes. Un alfabeto que contiene 256 secuencias diferentes de 8 bits se denomina alfabeto de bytes. Un sistema numérico es un conjunto de reglas para nombrar y escribir números. Hay sistemas numéricos posicionales y no posicionales. El sistema numérico se llama posicional si el valor del dígito del número depende de la ubicación del dígito en el número. De lo contrario, se llama no posicional. El valor de un número está determinado por la posición de estos dígitos en el número. 2. Representación de números en una computadora. Concepto formalizado de un algoritmo. Los procesadores de 32 bits pueden funcionar con hasta 232-1 RAM y las direcciones se pueden escribir en el rango 00000000 - FFFFFFFF. Sin embargo, en modo real, el procesador funciona con una memoria de hasta 220-1 y las direcciones se encuentran en el rango 00000 - FFFFF. Los bytes de memoria se pueden combinar en campos de longitud fija y variable. Una palabra es un campo de longitud fija que consta de 2 bytes, una palabra doble es un campo de 4 bytes. Las direcciones de campo pueden ser pares o impares, y las direcciones pares realizan operaciones más rápido. Los números de punto fijo se representan en las computadoras como números binarios enteros y su tamaño puede ser de 1, 2 o 4 bytes. Los números binarios enteros se representan en complemento a dos. El código adicional de un número positivo es igual al número mismo, y el código adicional de un número negativo se puede obtener mediante la siguiente fórmula: x = 10n - \x\, donde n es la profundidad de bits del número. En el sistema numérico binario, se obtiene un código adicional invirtiendo bits, es decir, reemplazando unidades con ceros y viceversa, y sumando uno al bit menos significativo. El número de bits de la mantisa determina la precisión de la representación de números, el número de bits de orden de máquina determina el rango de representación de números de punto flotante. Concepto formalizado de un algoritmo. Un algoritmo solo puede existir si, al mismo tiempo, existe algún objeto matemático. El concepto formalizado de un algoritmo está conectado con el concepto de funciones recursivas, algoritmos normales de Markov, máquinas de Turing. En matemáticas, una función se llama de un solo valor si, para cualquier conjunto de argumentos, existe una ley por la cual se determina el valor único de la función. Un algoritmo puede actuar como tal ley; en este caso se dice que la función es computable. Las funciones recursivas son una subclase de funciones computables, y los algoritmos que definen el cálculo se denominan algoritmos de funciones recursivas complementarias. Primero, se fijan las funciones recursivas básicas, para las cuales el algoritmo que las acompaña es trivial, inequívoco; luego se introducen tres reglas: operadores de sustitución, recursión y minimización, con la ayuda de los cuales se obtienen funciones recursivas más complejas sobre la base de funciones básicas. Las funciones básicas y los algoritmos que las acompañan pueden ser: 1) una función de n variables independientes, idénticamente igual a cero. Entonces, si el signo de la función es φn, independientemente del número de argumentos, el valor de la función debe establecerse igual a cero; 2) la función identidad de n variables independientes de la forma Ψ ni. Entonces, si el signo de la función es Ψ ni, entonces el valor de la función debe tomarse como el valor del i-ésimo argumento, contando de izquierda a derecha; 3) función λ de un argumento independiente. Entonces, si el signo de la función es λ, entonces el valor de la función debe tomarse como el valor que sigue al valor del argumento. 3. Introducción al lenguaje Pascal Los símbolos básicos del idioma (letras, números y caracteres especiales) forman su alfabeto. El lenguaje Pascal incluye el siguiente conjunto de símbolos básicos: 1) 26 minúsculas latinas y 26 mayúsculas latinas: 2) _ (guion bajo); 3) 10 dígitos: 0 1 2 3 4 5 6 7 8 9; 4) signos de operaciones: + - O / = <> < > <= >= := @; 5) delimitadores:., ( ) [ ] (..) { } (* *).. : ; 6) especificadores: ^ # $; 7) palabras de servicio (reservadas): ABSOLUTE, ASSEMBLER, AND, ARRAY, ASM, BEGIN, CASE, CONST, CONSTRUCTOR, DESTRUCTOR, DIV, DO, DOWNTO, ELSE, END, EXPORT, EXTERNAL, FAR, FILE, FOR, FORWARD, FUNCIÓN, IR A, SI, IMPLEMENTACIÓN, EN, ÍNDICE, HEREDADO, EN LÍNEA, INTERFAZ, INTERRUPCIÓN, ETIQUETA, BIBLIOTECA, MOD, NOMBRE, NIL, CERCA DE, NO, OBJETO, DE O, EMBALADO, PRIVADO, PROCEDIMIENTO, PROGRAMA, PÚBLICO, REGISTRO, REPETIR, RESIDENTE, SET, SHL, SHR, CADENA, ENTONCES, HASTA, TIPO, UNIDAD, HASTA, USOS, VAR, VIRTUAL, MIENTRAS, CON, XOR. Además de los enumerados, el conjunto de caracteres básicos incluye un espacio. Hay una regla en Pascal: el tipo se especifica explícitamente en la declaración de una variable o función que precede a su uso. El concepto de tipo Pascal tiene las siguientes propiedades principales: 1) cualquier tipo de dato define un conjunto de valores al que pertenece una constante, que puede tomar una variable o expresión, o puede producir una operación o función; 2) el tipo de valor dado por una constante, variable o expresión puede ser determinado por su forma o descripción; 3) cada operación o función requiere argumentos de tipo fijo y produce un resultado de tipo fijo. Hay tipos de datos escalares y estructurados en Pascal. Los tipos escalares incluyen tipos estándar y tipos definidos por el usuario. Los tipos estándar incluyen tipos enteros, reales, de caracteres, booleanos y de direcciones. Los tipos enteros definen constantes, variables y funciones cuyos valores son realizados por el conjunto de enteros permitidos en una computadora dada. Pascal tiene la siguiente precedencia de operadores:
1) cálculos entre paréntesis; 2) cálculo de valores de función; 3) operaciones unarias; 4) operaciones */div mod y; 5) operaciones + - o xor; 6) operaciones de relación = <> < > <= >=. 4. Procedimientos y funciones estándar Funciones aritméticas 1.Función Abs(X); devuelve el valor absoluto del parámetro. 2. Función ArcTan(X: Extendido): Extendido; devuelve el arco tangente del argumento. 3. Función Exp(X: Real): Real; devuelve el exponente. 4.Frac(X: Real): Real; devuelve la parte fraccionaria del argumento. 5. Función Int(X: Real): Real; devuelve la parte entera del argumento. 6. Función Ln(X: Real): Real; devuelve el logaritmo natural (Ln e = 1) de una expresión de tipo real x. 7. Función Pi: extendida; devuelve el valor Pi, que se define como 3.1415926535. 8. Función Sin (X: Extendido): Extendido; devuelve el seno del argumento. 9.Función Sqr(X: Extendido): Extendido; devuelve el cuadrado del argumento. 10.Función Sqrt(X: Extendido): Extendido; devuelve la raíz cuadrada del argumento. Procedimientos y funciones de conversión de valores 1. Procedimiento Str(X [: Ancho [: Decimales]]; var S); convierte el número X en una representación de cadena. 2. Función Chr(X: Byte): Char; devuelve el carácter con número de índice x en la tabla ASCII. 3. Función alta (X); devuelve el valor más grande en el rango del parámetro. 4. Función Baja (X); devuelve el valor más pequeño en el rango del parámetro. 5. Función Ord(X): LongInt; devuelve el valor ordinal de una expresión de tipo enumerada. 6. Función Ronda (X: Extendido): LongInt; redondea un valor real a un número entero. 7. Función Trunc (X: Extendido): LongInt; trunca un valor de tipo real a un entero. 8. Procedimiento Val(S; var V; var Código: Entero); convierte un número de un valor de cadena S a una representación numérica V. Procedimientos y funciones de valor ordinal 1. Procedimiento Dec(var X [; N: LongInt]); resta uno o N de la variable X. 2. Procedimiento Inc(var X [; N: LongInt]); suma uno o N a la variable X. 3. Función Odd(X: LongInt): Boolean; devuelve True si X es un número impar, False en caso contrario. 4.FunciónPred(X); devuelve el valor anterior del parámetro. 5 Función Succ(X); devuelve el siguiente valor del parámetro. 5. Operadores del lenguaje Pascal Operador condicional El formato de la declaración condicional completa se define de la siguiente manera: Si B entonces S1 sino S2 donde B es una condición de ramificación (toma de decisiones), una expresión lógica o una relación; S1, S2: una declaración ejecutable, simple o compuesta. Al ejecutar una declaración condicional, primero se evalúa la expresión B, luego se analiza su resultado: si B es verdadera, entonces se ejecuta la declaración S1, la rama de entonces, y se omite la declaración S2; si B es falso, entonces se ejecuta la instrucción S2: se ejecuta la rama else y se omite la instrucción S1. Operador de selección La estructura del operador es la siguiente: los casos de c1: instrucción1; c2: instrucción2; ... cn: instrucciónN; otra instrucción fin; donde S es una expresión de tipo ordinal cuyo valor se está calculando; c1, c2,..., on - constantes de tipo ordinal con las que se comparan las expresiones S; instrucciónl,..., instrucciónN - operadores de los cuales se ejecuta aquel cuya constante coincide con el valor de la expresión S; instrucción: un operador que se ejecuta si el valor de la expresión S no coincide con ninguna de las constantes c1, o2, on. Instrucción de bucle con parámetro Cuando la instrucción for comienza a ejecutarse, los valores inicial y final se determinan una vez, y estos valores se conservan durante la ejecución de la instrucción for. La instrucción contenida en el cuerpo de la instrucción for se ejecuta una vez para cada valor en el rango entre los valores inicial y final. El contador de bucle siempre se inicializa a un valor inicial. Declaración de bucle con condición previa Mientras que B hace S; donde B es una condición lógica, cuya verdad se verifica (es una condición para terminar el ciclo)$; S - cuerpo de bucle - una declaración. La expresión que controla la repetición de una instrucción debe ser de tipo booleano. Se evalúa antes de que se ejecute la instrucción interna. La declaración interna se ejecuta repetidamente siempre que la expresión se evalúe como Trie. Si la expresión se evalúa como Falsa desde el principio, entonces la declaración contenida dentro de la declaración del bucle de condición previa no se ejecuta. Instrucción de bucle con condición posterior repetir S hasta B; donde B es una condición lógica, cuya verdad se verifica (es una condición para terminar el bucle); S: una o más declaraciones de cuerpo de ciclo. El resultado de la expresión debe ser de tipo booleano. Las declaraciones encerradas entre las palabras clave repetir y hasta se ejecutan secuencialmente hasta que el resultado de la expresión se evalúe como Verdadero. La secuencia de instrucciones se ejecutará al menos una vez porque la expresión se evalúa después de cada ejecución de la secuencia de instrucciones. 6. El concepto de un algoritmo auxiliar Un algoritmo para resolver un problema se diseña descomponiendo el problema completo en subtareas separadas. Normalmente, las subtareas se implementan como subrutinas. Una subrutina es un algoritmo auxiliar que se usa repetidamente en el algoritmo principal con diferentes valores de algunas cantidades entrantes, llamadas parámetros. Una subrutina en lenguajes de programación es una secuencia de instrucciones que se definen y escriben en un solo lugar del programa, pero que pueden llamarse para su ejecución desde uno o más puntos del programa. Cada subrutina se identifica con un nombre único. Hay dos tipos de subrutinas en Pascal, procedimientos y funciones. Un procedimiento y una función son una secuencia con nombre de declaraciones y sentencias. Cuando se utilizan procedimientos o funciones, el programa debe contener el texto del procedimiento o función y una llamada al procedimiento o función. Los parámetros especificados en la descripción se denominan formales, los especificados en la llamada a la subrutina se denominan reales. Todos los parámetros formales se pueden dividir en las siguientes categorías: 1) parámetros-variables; 2) parámetros constantes; 3) valores de parámetros; 4) parámetros de procedimiento y parámetros de función, es decir, parámetros de tipo procedimental; 5) parámetros variables sin tipo. Los textos de procedimientos y funciones se colocan en las descripciones de procedimientos y funciones. Pasar nombres de procedimientos y funciones como parámetros En muchos problemas, especialmente en matemáticas computacionales, es necesario pasar los nombres de procedimientos y funciones como parámetros. Para hacer esto, TURBO PASCAL introdujo un nuevo tipo de datos: procedimental o funcional, según lo que se describa. (Los tipos de funciones y procedimientos se describen en la sección de declaración de tipos). Una función y tipo de procedimiento se define como el encabezado de un procedimiento y una función con una lista de parámetros formales pero sin nombre. Es posible definir una función o tipo de procedimiento sin parámetros, por ejemplo: tipo Proc = procedimiento; Después de declarar un tipo procedimental o funcional, se puede usar para describir parámetros formales: los nombres de procedimientos y funciones. Además, es necesario escribir aquellos procedimientos o funciones reales cuyos nombres se pasarán como parámetros reales. 7. Procedimientos y funciones en Pascal Procedimientos en Pascal La descripción del procedimiento consta de una cabecera y un bloque, que, salvo el apartado de conexión del módulo, no difieren del bloque del programa. El encabezado consta de la palabra clave Procedimiento, el nombre del procedimiento y una lista opcional de parámetros formales entre paréntesis: Procedimiento <nombre> [(<lista de parámetros formales>)]; Para cada parámetro formal, se debe definir su tipo. Los grupos de parámetros en una descripción de procedimiento están separados por punto y coma. La estructura del procedimiento es casi completamente similar al programa. Sin embargo, no hay una sección de conexión de módulo en el bloque de procedimiento. El bloque consta de dos partes: descriptiva y ejecutiva. La parte descriptiva contiene una descripción de los elementos del procedimiento. Y en la parte ejecutiva se indican acciones con los elementos de programa de que dispone el procedimiento (por ejemplo, variables globales y constantes), que permiten obtener el resultado requerido. La sección de instrucciones de un procedimiento difiere de la sección de instrucciones de un programa solo en que la palabra clave End que termina la sección va seguida de un punto y coma en lugar de un punto. Una instrucción de llamada a procedimiento se utiliza para llamar a un procedimiento. Consiste en el nombre del procedimiento y una lista de argumentos entre paréntesis. Las sentencias que se ejecutarán cuando se ejecute el procedimiento están contenidas en la parte de sentencia del módulo de procedimiento. A veces desea que un procedimiento se llame a sí mismo. Esta forma de llamar se llama recursividad. La recursividad es útil en los casos en que la tarea principal se puede dividir en subtareas, cada una de las cuales se implementa de acuerdo con un algoritmo que coincide con el principal. Funciones en Pascal Una declaración de función define la parte del programa en la que se calcula y devuelve el valor. Una descripción de función consta de un encabezado y un bloque. El encabezado contiene la palabra clave Function, el nombre de la función, una lista opcional de parámetros formales encerrados entre paréntesis y el tipo de retorno de la función. La forma general del encabezado de la función es la siguiente: Función <nombre> [(<lista de parámetros formales>)]: <tipo de retorno>; En la implementación de Borland de Turbo Pascal 7.0, el valor de retorno de una función no puede ser de tipo compuesto. Y el lenguaje Object Pascal utilizado en los entornos de desarrollo integrados de Borland Delphi permite cualquier tipo de resultado de retorno, excepto el tipo de archivo. Un bloque de función es un bloque local, similar en estructura a un bloque de procedimiento. El cuerpo de una función debe contener al menos una instrucción de asignación, en el lado izquierdo de la cual está el nombre de la función. Es ella quien determina el valor devuelto por la función. Si hay varias instrucciones de este tipo, el resultado de la función será el valor de la última instrucción de asignación ejecutada. La función se activa cuando se llama a la función. Cuando se llama a una función, se especifica el identificador de función y los parámetros necesarios para evaluar la función. Una llamada de función se puede incluir en expresiones como un operando. Cuando se evalúa la expresión, se ejecuta la función y el valor del operando se convierte en el valor devuelto por la función. La parte del operador del bloque de funciones especifica las declaraciones que deben ejecutarse cuando se activa la función. Un módulo debe contener al menos una instrucción de asignación que asigne un valor a un identificador de función. El resultado de la función es el último valor asignado. Si no existe tal declaración de asignación, o si no se ha ejecutado, entonces el valor de retorno de la función no está definido. Si se utiliza un identificador de función al llamar a una función dentro de un módulo, una función, entonces la función se ejecuta de forma recursiva. 8. Reenviar descripciones y conexión de subrutinas. Directiva Un programa puede contener varias subrutinas, es decir, la estructura del programa puede ser complicada. Sin embargo, estas subrutinas pueden estar en el mismo nivel de anidamiento, por lo que la declaración de la subrutina debe aparecer primero y luego la llamada, a menos que se use una declaración de avance especial. Una declaración de procedimiento que contiene una directiva de reenvío en lugar de un bloque de instrucciones se denomina declaración de reenvío. En algún momento después de esta declaración, se debe definir un procedimiento por medio de una declaración de definición. Una declaración definitoria es aquella que usa el mismo identificador de procedimiento pero omite la lista de parámetros formales e incluye un bloque de declaración. La declaración directa y la declaración de definición deben aparecer en la misma parte de las declaraciones de procedimiento y función. Entre ellos, se pueden declarar otros procedimientos y funciones que pueden hacer referencia al procedimiento de declaración directa. Por lo tanto, la recursividad mutua es posible. La descripción directa y la descripción definitoria son la descripción completa del procedimiento. Se considera que el procedimiento se describe utilizando la descripción directa. Si el programa contiene muchas subrutinas, el programa dejará de ser visual, será difícil navegar en él. Para evitar esto, algunas rutinas se almacenan como archivos fuente en el disco y, si es necesario, se conectan al programa principal en la etapa de compilación mediante una directiva de compilación. Una directiva es un comentario especial que se puede colocar en cualquier parte de un programa, donde puede estar un comentario normal. Sin embargo, difieren en que la directiva tiene una notación especial: inmediatamente después del paréntesis de cierre, sin espacio, se escribe el signo $, y luego, nuevamente sin espacio, se indica la directiva. Ejemplo: 1) {$E+} - emular coprocesador matemático; 2) {$F+} - forma el tipo lejano de procedimientos y funciones de llamada; 3) {$N+} - usar coprocesador matemático; 4) {$R+}: compruebe si los rangos están fuera de los límites. Algunos conmutadores de compilación pueden contener un parámetro, por ejemplo: {$I nombre de archivo}: incluye el archivo nombrado en el texto del programa compilado 9. Parámetros del subprograma La descripción de un procedimiento o función especifica una lista de parámetros formales. Cada parámetro declarado en una lista de parámetros formales es local al procedimiento o función que se describe, y se puede hacer referencia a él en el módulo asociado con ese procedimiento o función por su identificador. Hay tres tipos de parámetros: valor, variable y variable sin tipo. Se caracterizan de la siguiente manera: 1. Un grupo de parámetros sin una palabra clave anterior es una lista de parámetros de valor. 2. Un grupo de parámetros precedido por la palabra clave const y seguido por un tipo es una lista de parámetros constantes. 3. Un grupo de parámetros precedidos por la palabra clave var y seguidos por un tipo es una lista de parámetros variables. Parámetros de valor Un parámetro de valor formal se trata como una variable local del procedimiento o la función, excepto que obtiene su valor inicial del parámetro real correspondiente cuando se invoca el procedimiento o la función. Los cambios que sufre un parámetro de valor formal no afectan el valor del parámetro real. El valor real correspondiente del parámetro de valor debe ser una expresión y su valor no debe ser un tipo de archivo ni ningún tipo de estructura que contenga un tipo de archivo. El parámetro real debe ser de un tipo cuya asignación sea compatible con el tipo del parámetro de valor formal. Si el parámetro es de tipo cadena, el parámetro formal tendrá un atributo de tamaño de 255. Parámetros constantes En el cuerpo de una subrutina, el valor de un parámetro constante no se puede cambiar. Los parámetros-constantes se pueden utilizar para organizar aquellos parámetros cuyos cambios en la subrutina no son deseables y deben prohibirse. Parámetros variables Se utiliza un parámetro variable cuando se debe pasar un valor de una subrutina a un bloque de llamada. En este caso, cuando se llama a la subrutina, el parámetro formal se reemplaza por el argumento variable y cualquier cambio en el parámetro formal se refleja en el argumento. variables de procedimiento Después de definir un tipo de procedimiento, es posible describir variables de este tipo. Estas variables se denominan variables de procedimiento. Al igual que una variable entera a la que se le puede asignar un valor de un tipo entero, a una variable de procedimiento se le puede asignar un valor de un tipo de procedimiento. Por supuesto, dicho valor podría ser otra variable de procedimiento, pero también podría ser un identificador de procedimiento o función. En este contexto, la declaración de un procedimiento o función puede verse como una descripción de un tipo especial de constante cuyo valor es el procedimiento o la función. Como con cualquier otra asignación, los valores de la variable del lado izquierdo y del lado derecho deben ser compatibles con la asignación. Los tipos procedimentales, para que sean compatibles con la asignación, deben tener el mismo número de parámetros, y los parámetros en las posiciones correspondientes deben ser del mismo tipo. Los nombres de parámetros en una declaración de tipo procedimental no tienen efecto. Además, para garantizar la compatibilidad de la asignación, un procedimiento o función, si se va a asignar a una variable de procedimiento, no debe ser estándar ni anidado. 10. Tipos de parámetros de subrutina Parámetros de valor Un parámetro de valor formal se trata como una variable local; obtiene su valor inicial del parámetro real correspondiente cuando se invoca el procedimiento o la función. Los cambios que sufre un parámetro de valor formal no afectan el valor del parámetro real. El valor real correspondiente del parámetro de valor debe ser una expresión y su valor no debe ser de un tipo de archivo. Parámetros constantes Los parámetros constantes formales obtienen su valor cuando se invoca un procedimiento o función. No se permiten asignaciones a un parámetro constante formal. Un parámetro constante formal no se puede pasar como un parámetro real a otro procedimiento o función. Parámetros variables Un parámetro de variable se utiliza cuando se debe pasar un valor de un procedimiento o función al programa de llamada. Cuando está activado, la variable de parámetro formal se reemplaza por la variable real, los cambios en la variable de parámetro formal se reflejan en el parámetro real. Parámetros sin tipo Cuando el parámetro formal es un parámetro variable sin tipo, el parámetro real correspondiente puede ser una referencia variable o constante. Un parámetro sin tipo declarado con la palabra clave var se puede modificar, mientras que un parámetro sin tipo declarado con la palabra clave const es de solo lectura. variables de procedimiento Después de definir un tipo de procedimiento, es posible describir variables de este tipo. Estas variables se denominan variables de procedimiento. A una variable de procedimiento se le puede asignar un valor de un tipo de procedimiento. El procedimiento o función encomendada debe ser: 1) no estándar; 2) no anidado; 3) no es un procedimiento de tipo en línea; 4) no por el procedimiento de interrupción. Parámetros de tipo de procedimiento Dado que los tipos procedimentales se pueden usar en cualquier contexto, es posible describir procedimientos o funciones que toman procedimientos y funciones como parámetros. Los parámetros de tipo de procedimiento son especialmente útiles cuando necesita realizar alguna acción común en varios procedimientos o funciones. Si se va a pasar un procedimiento o una función como parámetro, debe seguir las mismas reglas de compatibilidad de tipos que la asignación. Es decir, dichos procedimientos o funciones deben compilarse con la directiva far, no pueden ser funciones integradas, no pueden anidarse y no pueden describirse con los atributos en línea o de interrupción. 11. Tipo de cadena en Pascal. Procedimientos y funciones para variables de tipo cadena Una secuencia de caracteres de cierta longitud se denomina cadena. Las variables de tipo cadena se definen especificando el nombre de la variable, la palabra reservada cadena y, opcionalmente, pero no necesariamente, especificando el tamaño máximo, es decir, la longitud de la cadena, entre corchetes. Si no establece el tamaño máximo de cadena, de forma predeterminada será 255, es decir, la cadena constará de 255 caracteres. Se puede hacer referencia a cada elemento de una cadena por su número. Sin embargo, la entrada y salida de cadenas se realiza como un todo, y no elemento por elemento, como es el caso de las matrices. El número de caracteres ingresados no debe exceder el especificado en el tamaño máximo de la cadena, por lo que si ocurre tal exceso, los caracteres "extra" serán ignorados. Procedimientos y funciones para variables de tipo cadena 1. Función Copiar (S: Cadena; Índice, Recuento: Entero): Cadena; Devuelve una subcadena de una cadena. S es una expresión de tipo String. Index y Count son expresiones de tipo entero. La función devuelve una cadena que contiene caracteres de recuento que comienzan en la posición de índice. Si Index es mayor que la longitud de S, la función devuelve una cadena vacía. 2. Eliminar procedimiento (var S: cadena; índice, recuento: entero); Elimina una subcadena de caracteres de longitud Count de la cadena S, comenzando en la posición Index. S es una variable de tipo String. Index y Count son expresiones de tipo entero. Si el índice es mayor que la longitud de S, no se elimina ningún carácter. 3. Insertar procedimiento (Fuente: Cadena; var S: Cadena; Índice: Entero); Concatena una subcadena en una cadena, comenzando en una posición especificada. Source es una expresión de tipo String. S es una variable de tipo String de cualquier longitud. El índice es una expresión de tipo entero. Insertar inserta Source en S, comenzando en la posición S. 4. Longitud de la función (S: Cadena): Entero; Devuelve el número de caracteres realmente utilizados en la cadena S. Tenga en cuenta que cuando se utilizan cadenas terminadas en cero, el número de caracteres no es necesariamente igual al número de bytes. 5. Función Pos(Substr: Cadena; S: Cadena): Entero; Busca una subcadena en una cadena. Pos busca Substr dentro de S y devuelve un valor entero que es el índice del primer carácter de Substr dentro de S. Si no se encuentra Substr, Pos devuelve cero. 12. Grabaciones Un registro es una colección de un número limitado de componentes lógicamente relacionados que pertenecen a diferentes tipos. Los componentes de un registro se denominan campos, cada uno de los cuales se identifica con un nombre. Un campo de registro contiene el nombre del campo, seguido de dos puntos para indicar el tipo de campo. Los campos de registro pueden ser de cualquier tipo permitido en Pascal, con la excepción del tipo de archivo. La descripción de un registro en lenguaje Pascal se realiza mediante la palabra de servicio RECORD, seguida de la descripción de los componentes del registro. La descripción de la entrada termina con la palabra de servicio FIN. Por ejemplo, una libreta contiene apellidos, iniciales y números de teléfono, por lo que es conveniente representar una línea separada en una libreta como la siguiente entrada: tipo Fila = Registro FIO: Cadena[20]; TEL: Cadena[7]; fin; var str: Fila; Las descripciones de registros también son posibles sin usar el nombre del tipo, por ejemplo: var cadena: Registro FIO: Cadena[20]; TEL: Cadena[7]; fin; Solo se permite hacer referencia a un registro como un todo en declaraciones de asignación donde se usan nombres de registro del mismo tipo a la izquierda y a la derecha del signo de asignación. En todos los demás casos, se operan campos separados de registros. Para hacer referencia a un componente de registro individual, debe especificar el nombre del registro y, a través de un punto, especificar el nombre del campo deseado. Tal nombre se llama nombre compuesto. Un componente de registro también puede ser un registro, en cuyo caso el nombre distinguido contendrá no dos, sino más nombres. La referencia a los componentes del registro se puede simplificar utilizando el operador with append. Le permite reemplazar los nombres compuestos que caracterizan cada campo con solo nombres de campo y definir el nombre del registro en la declaración de combinación. A veces, el contenido de un registro individual depende del valor de uno de sus campos. En el lenguaje Pascal, se permite una descripción de registro, que consta de partes comunes y variantes. La parte variante se especifica utilizando el caso P de constructo, donde P es el nombre del campo de la parte común del registro. Los posibles valores aceptados por este campo se enumeran de la misma manera que en la declaración de variante. Sin embargo, en lugar de especificar la acción a realizar, como se hace en una declaración de variante, los campos de variante se especifican entre paréntesis. La descripción de la parte variante termina con la palabra de servicio fin. El tipo de campo P se puede especificar en el encabezado de la parte variante. Los registros se inicializan usando constantes escritas. 13. Conjuntos El concepto de conjunto en el lenguaje Pascal se basa en el concepto matemático de conjunto: es una colección limitada de diferentes elementos. Un tipo de datos enumerado o de intervalo se utiliza para construir un tipo de conjunto concreto. El tipo de elementos que componen un conjunto se denomina tipo base. Un tipo múltiple se describe utilizando el Conjunto de palabras de función, por ejemplo: tipo M = Conjunto de B; donde M es el tipo plural, B es el tipo base. La pertenencia de las variables a un tipo plural se puede determinar directamente en la sección de declaración de variables. Las constantes de tipo conjunto se escriben como una secuencia entre paréntesis de elementos o intervalos de tipo base, separados por comas. Las operaciones de asignación (:=), unión (+), intersección (*) y resta (-) son aplicables a variables y constantes de tipo conjunto. El resultado de estas operaciones es un valor del tipo plural: 1) ['A','B'] + ['A','D'] dará ['A','B','D']; 2) ['A'] * ['A','B','C'] dará ['A']; 3) ['A','B','C'] - ['A','B'] dará ['C'] Las siguientes operaciones son aplicables a múltiples valores: identidad (=), no identidad (<>), contenida en (<=), contiene (>=). El resultado de estas operaciones tiene un tipo booleano: 1) ['A','B'] = ['A','C'] dará FALSO; 2) ['A','B'] <> ['A','C'] dará VERDADERO; 3) ['B'] <= ['B','C'] dará VERDADERO; 4) ['C','D'] >= ['A'] dará FALSO. Además de estas operaciones, para trabajar con valores de tipo set, se utiliza la operación in, que comprueba si el elemento del tipo base a la izquierda del signo de operación pertenece al conjunto a la derecha del signo de operación . El resultado de esta operación es un booleano. Los valores de un tipo múltiple no pueden ser elementos de una lista de E/S. En cada implementación concreta del compilador del lenguaje Pascal, se limita el número de elementos del tipo base sobre los que se construye el conjunto. 14. Archivos. Operaciones de archivo El tipo de datos de archivo define una colección ordenada de componentes del mismo tipo. Cuando se trabaja con archivos, se realizan operaciones de E/S. Una operación de entrada es una transferencia de datos desde un dispositivo externo a la memoria, una operación de salida es una transferencia de datos desde la memoria a un dispositivo externo. Archivos de texto Para describir tales archivos, hay un tipo de texto: var TF1, TF2: Texto; Archivos de componentes Un componente o archivo tipado es un archivo con el tipo declarado de sus componentes. tipo M = Archivo De T; donde M es el nombre del tipo de archivo; T - tipo de componente. Las operaciones se realizan mediante procedimientos. Escribir(f, X1,X2,...XK) Archivos sin tipo Los archivos sin tipo le permiten escribir secciones arbitrarias de la memoria de la computadora en el disco y leerlas. varf: Archivo; 1. Asignación de procedimiento (var F; FileName: String); Asigna un nombre de archivo a una variable. 2. Procedimiento Cerrar (varF); Rompe el vínculo entre la variable de archivo y el archivo del disco externo y cierra el archivo. 3.Función Eof(var F): Booleano; {Archivos con o sin tipo} Función Eof[(var F: Texto)]: Booleano; {archivos de texto} Comprueba el final de un archivo. 4. Procedimiento de borrado (var F); Elimina el archivo externo asociado con F. 5. Función FileSize(var F): Integer; Devuelve el tamaño en bytes del archivo F. 6.Función FilePos(varF): LongInt; Devuelve la posición actual dentro de un archivo. 7. Restablecimiento del procedimiento (var F [: Archivo; RecSize: Word]); Abre un archivo existente. 8. Reescritura del procedimiento (var F: Archivo [; Recsize: Word]); Crea y abre un nuevo archivo. 9. Búsqueda de procedimiento (var F; N: LongInt); Mueve la posición del archivo actual al componente especificado. 10. Procedimiento Agregar (var F: Texto); Suma. 11.Función Eoln[(var F: Texto)]: Booleano; Comprueba el final de una cadena. 12. Procedimiento Lectura(F, V1 [, V2..., Vn]); {Archivos escritos y sin escribir} Procedimiento Leer([var F: Texto;] V1 [, V2..., Vn]); {archivos de texto} Lee un componente de archivo en una variable. 13. Procedimiento Readln([var F: Texto;] V1 [, V2..., Vn]); Lee una línea de caracteres en el archivo, incluido el marcador de final de línea, y se desplaza al principio de la siguiente. 14. Función SeekEof[(var F: Texto)]: Booleano; Devuelve el signo de fin de archivo. Se usa solo para archivos de texto abiertos. 15. Procedimiento Writeln([var F: Texto;] [P1, P2..., Pn]); {archivos de texto} Realiza una operación de escritura y luego coloca un marcador de fin de línea en el archivo. 15. Módulos. Tipos de módulos Una unidad (UNIT) en Pascal es una biblioteca de subrutinas especialmente diseñada. Un módulo, a diferencia de un programa, no puede ejecutarse por sí solo, solo puede participar en la construcción de programas y otros módulos. Un módulo en Pascal es una unidad de programa compilada de forma independiente y almacenada por separado. Todos los elementos del programa del módulo se pueden dividir en dos partes: 1) elementos de programa destinados a ser utilizados por otros programas o módulos, dichos elementos se denominan visibles fuera del módulo; 2) elementos de software que son necesarios solo para el funcionamiento del módulo en sí, se denominan invisibles (u ocultos). unidad <nombre del módulo>; {Título de módulo} interfaz. {descripción de los elementos de programa visibles del módulo} implementación {descripción de los elementos de programación ocultos del módulo} comenzar {declaraciones de inicialización del elemento del módulo} fin. Para hacer referencia a una variable declarada en un módulo, debe utilizar un nombre compuesto formado por el nombre del módulo y el nombre de la variable, separados por un punto. El uso recursivo de módulos está prohibido. Hagamos una lista de los tipos de módulos. 1. Módulo SISTEMA. El módulo SYSTEM implementa rutinas de soporte de nivel inferior para todas las funciones integradas, como E/S, manipulación de cadenas, operaciones de coma flotante y asignación de memoria dinámica. 2. Módulo DOS. El módulo DOS implementa numerosas rutinas y funciones de Pascal que son equivalentes a las llamadas de DOS más utilizadas, como GetTime, SetTime, DiskSize, etc. 3. Módulo CRT. El módulo CRT implementa una serie de potentes programas que brindan control total sobre las características de la PC, como el control del modo de pantalla, códigos de teclado extendidos, colores, ventanas y sonidos. 4. Módulo GRÁFICO. Usando los procedimientos y funciones incluidos en este módulo, puede crear varios gráficos en la pantalla. 5. Módulo SUPERPOSICIÓN. El módulo OVERLAY le permite reducir los requisitos de memoria de un programa DOS en modo real. 16. Tipo de datos de referencia. memoria dinámica. variables dinámicas. Trabajando con memoria dinámica Una variable estática (asignada estáticamente) es una variable declarada explícitamente en el programa, se la denomina por su nombre. El lugar en la memoria para colocar variables estáticas se determina cuando se compila el programa. A diferencia de tales variables estáticas, los programas de Pascal pueden crear variables dinámicas. La propiedad principal de las variables dinámicas es que se crean y se les asigna memoria durante la ejecución del programa. Las variables dinámicas se colocan en un área de memoria dinámica (área de montón). Una variable dinámica no se especifica explícitamente en las declaraciones de variables y no se puede hacer referencia a ella por su nombre. Se accede a dichas variables mediante punteros y referencias. Un tipo de referencia (puntero) define un conjunto de valores que apuntan a variables dinámicas de un determinado tipo, denominado tipo base. Una variable de tipo de referencia contiene la dirección de una variable dinámica en la memoria. Si el tipo base es un identificador no declarado, debe declararse en la misma parte de la declaración de tipo que el tipo de puntero. La palabra reservada nil denota una constante con un valor de puntero que no apunta a nada. Pongamos un ejemplo de la descripción de variables dinámicas. var p1, p2: ^real; p3, p4: ^entero; ... Procedimientos y funciones de la memoria dinámica 1. Procedimiento Nuevo{var p: Puntero). Asigna espacio en el área de memoria dinámica para acomodar la variable dinámica p", y asigna su dirección al puntero p. 2. Procedimiento Dispose(var p: Pointer). Libera la memoria asignada para la asignación de variables dinámicas por el procedimiento Nuevo y el valor del puntero p se vuelve indefinido. 3. Procedimiento GetMem(var p: Puntero; tamaño: Palabra). Asigna una sección de memoria en el área de montón, asigna la dirección de su comienzo al puntero p, el tamaño de la sección en bytes se especifica mediante el parámetro de tamaño. 4. Procedimiento FreeMem(varp: Pointer; tamaño: Word). Libera el área de memoria, cuya dirección inicial se especifica mediante el puntero p, y el tamaño se especifica mediante el parámetro de tamaño. El valor del puntero p se vuelve indefinido. 5. El procedimiento Mark{var p: Pointer) escribe en el puntero p la dirección de inicio de la sección de memoria dinámica libre en el momento de su llamada. 6. El procedimiento Release(var p: Pointer) libera una sección de memoria dinámica, a partir de la dirección escrita en el puntero p por el procedimiento Mark, es decir, borra la memoria dinámica que estaba ocupada después de la llamada al procedimiento Mark. 7. Función MaxAvail: Longint devuelve la longitud en bytes de la sección libre más larga de la memoria dinámica. 8. Función MemAvail: Longint devuelve la cantidad total de memoria dinámica libre en bytes. 9. La función auxiliar SizeOf(X):Word devuelve el tamaño, en bytes, ocupado por X, donde X puede ser un nombre de variable de cualquier tipo o un nombre de tipo. 17. Estructuras de datos abstractas Los tipos de datos estructurados, como matrices, conjuntos y registros, son estructuras estáticas porque sus tamaños no cambian durante toda la ejecución del programa. A menudo se requiere que las estructuras de datos cambien de tamaño en el transcurso de la resolución de un problema. Estas estructuras de datos se denominan dinámicas. Estos incluyen pilas, colas, listas, árboles, etc. La descripción de estructuras dinámicas usando arreglos, registros y archivos conduce a un desperdicio de la memoria de la computadora y aumenta el tiempo para resolver problemas. Cada componente de cualquier estructura dinámica es un registro que contiene al menos dos campos: un campo de tipo "puntero" y el segundo, para la ubicación de datos. En general, un registro puede contener no uno, sino varios punteros y varios campos de datos. Un campo de datos puede ser una variable, una matriz, un conjunto o un registro. Si la parte que apunta contiene la dirección de un elemento de la lista, entonces la lista se llama unidireccional (o enlazada individualmente). Si contiene dos componentes, entonces está doblemente conectado. Puede realizar varias operaciones en las listas, por ejemplo: 1) agregar un elemento a la lista; 2) eliminar un elemento de la lista con una clave determinada; 3) buscar un elemento con un valor dado del campo clave; 4) ordenar los elementos de la lista; 5) división de la lista en dos o más listas; 6) combinar dos o más listas en una sola; 7) otras operaciones. Sin embargo, como regla general, no surge la necesidad de todas las operaciones para resolver varios problemas. Por lo tanto, dependiendo de las operaciones básicas que se deban aplicar, existen diferentes tipos de listas. Los más populares de estos son la pila y la cola. 18. Pilas Una pila es una estructura de datos dinámica, la adición de un componente al cual y la eliminación de un componente del cual se hacen desde un extremo, llamado la parte superior de la pila. La pila funciona según el principio LIFO (último en entrar, primero en salir) - "Último en entrar, primero en salir". Por lo general, se realizan tres operaciones en las pilas: 1) formación inicial de la pila (registro del primer componente); 2) agregar un componente a la pila; 3) selección del componente (supresión). Para formar una pila y trabajar con ella, debe tener dos variables del tipo "puntero", la primera de las cuales determina la parte superior de la pila y la segunda es auxiliar. Ejemplo. Escriba un programa que forme una pila, le agregue un número arbitrario de componentes y luego lea todos los componentes. PILA de programas; utiliza Crt; tipo Alfa = Cadena[10]; PComp = ^Comp; Comp = registro SD: Alfa; pSiguiente: PComp fin; var pSuperior: PComp; SC: Alfa; Crear pila de procedimientos (var pTop: PComp; var sC: Alfa); comenzar Nuevo(pArriba); pArriba^.pSiguiente:= NIL; pSuperior^.sD:= sC; fin; Agregar ProcedimientoComp(var pTop: PComp; var sC: Alfa); var pAux: PComp; comenzar NUEVO(pAux); pAux^.pSiguiente:= pArriba; pSuperior:=pAux; pSuperior^.sD:= sC; fin; Procedimiento DelComp(var pTop: PComp; var sC: ALFA); comenzar sC:= pSuperior^.sD; pSuperior:= pSuperior^.pSiguiente; fin; comenzar Clrscr; writeln(ENTRAR CADENA); leer(sC); CreateStack(pArriba, sc); repetir writeln(ENTRAR CADENA); leer(sC); AddComp(pArriba, sc); hasta sC = 'FIN'; 19. Colas Una cola es una estructura de datos dinámica donde se agrega un componente en un extremo y se recupera en el otro extremo. La cola funciona según el principio FIFO (First-In, First-Out) - "Primero en entrar, primero en ser atendido". Ejemplo. Escriba un programa que forme una cola, le agregue un número arbitrario de componentes y luego lea todos los componentes. ProgramaQUEUE; utiliza Crt; tipo Alfa = Cadena[10]; PComp = ^Comp; Comp = registro SD: Alfa; pSiguiente: PComp; fin; var pInicio, pFin: PComp; SC: Alfa; Crear Cola de procedimiento(var pBegin,pEnd: PComp; var sc: Alfa); comenzar Nuevo(pInicio); pInicio^.pSiguiente:= NIL; pComienzo^.sD:= sC; pFin:=pComienzo; fin; Procedimiento AddQueue(var pEnd: PComp; var sC: alfa); var pAux: PComp; comenzar Nuevo(pAux); pAux^.pSiguiente:= NIL; pFin^.pSiguiente:= pAux; pFin:= pAux; pFin^.sD:= sC; fin; Procedimiento DelQueue(var pBegin: PComp; var sC: alfa); comenzar sC:=pInicio^.sD; pInicio:= pInicio^.pSiguiente; fin; comenzar Clrscr; writeln(ENTRAR CADENA); leer(sC); CreateQueue(pBegin, pEnd, sc); repetir writeln(ENTRAR CADENA); leer(sC); AddQueue(pEnd, sc); hasta sC = 'FIN'; 20. Estructuras de datos de árbol Una estructura de datos en forma de árbol es un conjunto finito de elementos, nodos entre los que existen relaciones, la conexión entre la fuente y lo generado. Si usamos la definición recursiva propuesta por N. Wirth, entonces una estructura de datos de árbol con base tipo t es una estructura vacía o un nodo de tipo t, con lo cual se forma un conjunto finito de estructuras de árbol con base tipo t, llamados subárboles. asociado. A continuación, damos las definiciones utilizadas cuando se opera con estructuras de árbol. Si el nodo y está ubicado directamente debajo del nodo x, entonces el nodo y se llama descendiente inmediato del nodo x, y x es el ancestro inmediato del nodo y, es decir, si el nodo x está en el nivel i-ésimo, entonces el nodo y está en consecuencia ubicado en (i + 1 ) - º nivel. El nivel máximo de un nodo de árbol se denomina altura o profundidad del árbol. Un antepasado no tiene solo un nodo del árbol: su raíz. Los nodos de árbol que no tienen hijos se denominan nodos hoja (u hojas del árbol). Todos los demás nodos se denominan nodos internos. El número de hijos inmediatos de un nodo determina el grado de ese nodo, y el grado máximo posible de un nodo en un árbol determinado determina el grado del árbol. Los ascendientes y los descendientes no pueden intercambiarse, es decir, la conexión entre el original y el generado actúa solo en una dirección. Si va desde la raíz del árbol hasta algún nodo en particular, entonces el número de ramas del árbol que se atravesarán en este caso se denomina longitud del camino para este nodo. Si todas las ramas (nodos) de un árbol están ordenadas, se dice que el árbol está ordenado. Los árboles binarios son un caso especial de estructuras de árbol. Estos son árboles en los que cada hijo tiene como máximo dos hijos, llamados subárboles izquierdo y derecho. Así, un árbol binario es una estructura de árbol cuyo grado es dos. El orden de un árbol binario está determinado por la siguiente regla: cada nodo tiene su propio campo clave, y para cada nodo el valor clave es mayor que todas las claves en su subárbol izquierdo y menor que todas las claves en su subárbol derecho. Un árbol cuyo grado es mayor que dos se llama fuertemente ramificado. 21. Operaciones en árboles Además, consideraremos todas las operaciones en relación con los árboles binarios. I. Construyendo un árbol. Presentamos un algoritmo para construir un árbol ordenado. 1. Si el árbol está vacío, los datos se transfieren a la raíz del árbol. Si el árbol no está vacío, entonces una de sus ramas desciende de tal manera que no se viola el orden del árbol. Como resultado, el nuevo nodo se convierte en la siguiente hoja del árbol. 2. Para agregar un nodo a un árbol ya existente, puede usar el algoritmo anterior. 3. Al eliminar un nodo del árbol, debe tener cuidado. Si el nodo a eliminar es una hoja o tiene un solo hijo, entonces la operación es simple. Si el nodo a eliminar tiene dos descendientes, será necesario encontrar un nodo entre sus descendientes que se pueda colocar en su lugar. Esto es necesario debido al requisito de que el árbol esté ordenado. Puede hacer esto: intercambiar el nodo que se eliminará con el nodo con el valor de clave más grande en el subárbol izquierdo, o con el nodo con el valor de clave más pequeño en el subárbol derecho, y luego elimine el nodo deseado como una hoja. II. Busque un nodo con un valor de campo clave determinado. Al realizar esta operación, es necesario atravesar el árbol. Es necesario tener en cuenta diferentes formas de notación de árbol: prefijo, infijo y posfijo. Surge la pregunta: ¿cómo representar los nodos del árbol para que sea más conveniente trabajar con ellos? Es posible representar un árbol usando un arreglo, donde cada nodo es descrito por un valor de tipo combinado, el cual tiene un campo de información de tipo carácter y dos campos de tipo referencia. Pero esto no es muy conveniente, ya que los árboles tienen una gran cantidad de nodos que no están predeterminados. Por lo tanto, es mejor usar variables dinámicas al describir un árbol. Entonces cada nodo está representado por un valor del mismo tipo, que contiene una descripción de un número dado de campos de información, y el número de campos correspondientes debe ser igual al grado del árbol. Es lógico definir la ausencia de descendencia por la referencia nula. Entonces, en Pascal, la descripción de un árbol binario podría verse así: TIPO TreeLink = ^Árbol; árbol = registro; Inf: <tipo de dato>; Izquierda, Derecha: TreeLink; Fin. 22. Ejemplos de implementación de operaciones 1. Construya un árbol de XNUMX nodos de altura mínima, o un árbol perfectamente equilibrado (el número de nodos de los subárboles izquierdo y derecho de dicho árbol no debe diferir en más de uno). Algoritmo de construcción recursivo: 1) el primer nodo se toma como raíz del árbol; 2) el subárbol izquierdo de nl nodos se construye de la misma manera; 3) el subárbol derecho de nr nodos se construye de la misma manera; nr = n - nl - 1 Como campo de información tomaremos los números de nodo ingresados desde el teclado. La función recursiva que implementa esta construcción se verá así: Árbol de funciones (n: Byte): TreeLink; Varta: TreeLink; nl,nr,x: byte; Comenzar Si n = 0 entonces Árbol:= nil otro Comenzar nl:= n div 2; nr = n - nl - 1; writeln('Ingrese el número de vértice); lectura(x); tritón); t^.inf:= x; t^.izquierda:= Árbol(nl); t^.derecha:= Árbol(nr); Árbol:=t; End; {Árbol} Fin. 2. En el árbol ordenado binario, encuentre el nodo con el valor dado del campo clave. Si no existe tal elemento en el árbol, agréguelo al árbol. Procedimiento de búsqueda (x: Byte; var t: TreeLink); Comenzar Si t = cero entonces Comenzar Tritón); t^inf:= x; t^.izquierda:= nil; t^.derecha:= nil; Fin De lo contrario, si x < t^.inf entonces Buscar(x, t^.izquierda) De lo contrario, si x > t^.inf entonces Buscar(x, t^.derecha) otro Comenzar {proceso elemento encontrado} ... End; Fin. 23. El concepto de grafo. Maneras de representar un gráfico Un grafo es un par G = (V,E), donde V es un conjunto de objetos de naturaleza arbitraria, llamados vértices, y E es una familia de pares ei = (vil, vi2), vijOV, llamados aristas. En el caso general, el conjunto V y (o) la familia E pueden contener un número infinito de elementos, pero consideraremos solo gráficos finitos, es decir, gráficos para los que tanto V como E son finitos. Si el orden de los elementos incluidos en ei importa, entonces el gráfico se llama dirigido, abreviado como dígrafo, de lo contrario se llama no dirigido. Los bordes de un dígrafo se llaman arcos. Si e = , entonces los vértices v y u se llaman extremos de la arista. En este caso, se dice que la arista e es adyacente (incidente) a cada uno de los vértices v y u. Los vértices vy y también se denominan adyacentes (incidentes). En el caso general, las aristas de la forma e = ; tales bordes se llaman bucles. El grado de un vértice de un gráfico es el número de aristas incidentes en el vértice dado, con bucles contados dos veces. El peso de un nodo es un número (real, entero o racional) asignado a un nodo dado (interpretado como costo, rendimiento, etc.). Un camino en un gráfico (o una ruta en un dígrafo) es una secuencia alterna de vértices y aristas (o arcos en un dígrafo) de la forma v0, (v0,v1), v1,..., (vn -1, vn), vn. El número n se llama longitud del camino. Un camino sin aristas repetidas se llama cadena; un camino sin vértices repetidos se llama cadena simple. Un camino cerrado sin aristas repetidas se llama ciclo (o contorno en un dígrafo); sin repetir vértices (excepto el primero y el último) - un ciclo simple. Un grafo se dice conexo si hay un camino entre dos de sus vértices y desconectado en caso contrario. Hay varias formas de representar gráficos. 1. Matriz de incidencia. Esta es una matriz rectangular de n x m, donde n es el número de vértices y m es el número de aristas. 2. Matriz de adyacencia. Esta es una matriz cuadrada de dimensiones n × n, donde n es el número de vértices. 3. Relación de adyacencias (incidencias). Representa una estructura de datos que para cada vértice del gráfico almacena una lista de vértices adyacentes. La lista es una matriz de punteros, cuyo i-ésimo elemento contiene un puntero a la lista de vértices adyacentes al i-ésimo vértice. 4. Lista de listas. Es una estructura de datos similar a un árbol en la que una rama contiene listas de vértices adyacentes a cada una. 24. Varias representaciones gráficas Para implementar un gráfico como una lista de incidencias, puede utilizar el siguiente tipo: ListaTipos = ^S; S=registro; información: byte; siguiente: Lista; fin; Entonces el gráfico se define de la siguiente manera: Vargr: array[1..n] de Lista; Ahora pasemos al procedimiento de recorrido de grafos. Este es un algoritmo auxiliar que le permite ver todos los vértices del gráfico, analizar todos los campos de información. Si consideramos el recorrido del gráfico en profundidad, entonces hay dos tipos de algoritmos: recursivos y no recursivos. En Pascal, el procedimiento transversal primero en profundidad se vería así: Procedimiento Obhod(gr: Gráfico; k: Byte); Varg: Gráfico; l:Lista; Comenzar nov[k]:= falso; g:=gr; mientras g^.inf <> k hacer g:= g^.siguiente; l:= g^.smeg; Mientras que l <> nil comienzan Si nov[l^.inf] entonces Obhod(gr, l^.inf); l:= l^.siguiente; End; End; Representar un gráfico como una lista de listas Un gráfico se puede definir usando una lista de listas de la siguiente manera: ListaTipos = ^Tlista; tlist=registro información: byte; siguiente: Lista; fin; Gráfico = ^TGpaph; TGpaph = registro información: byte; smeg: Lista; siguiente: gráfico; fin; Al atravesar el gráfico a lo ancho, seleccionamos un vértice arbitrario y miramos a través de todos los vértices adyacentes a él a la vez. Aquí hay un procedimiento para atravesar un gráfico en ancho en pseudocódigo: Procedimiento Obhod2(v); Comenzar cola = O; cola <= v; nov[v] = Falso; Mientras cola <> O hacer Comenzar p <= cola; Para ti en spisok (p) haz Si es nuevo[u] entonces Comenzar nov[u]:= Falso; cola <= u; End; End; End; 25. Tipo de objeto en Pascal. El concepto de objeto, su descripción y uso Un lenguaje de programación orientado a objetos se caracteriza por tres propiedades principales: 1) encapsulación. La combinación de registros con procedimientos y funciones que manipulan los campos de estos registros forma un nuevo tipo de datos: un objeto; 2) herencia. Definición de un objeto y su uso posterior para construir una jerarquía de objetos secundarios con la capacidad de que cada objeto secundario relacionado con la jerarquía acceda al código y los datos de todos los objetos principales; 3) polimorfismo. Dar a una acción un solo nombre, que luego se comparte hacia arriba y hacia abajo en la jerarquía de objetos, con cada objeto en la jerarquía realizando esa acción de la manera que más le convenga. Hablando del objeto, presentamos un nuevo tipo de datos: el objeto. Un tipo de objeto es una estructura que consta de un número fijo de componentes. Cada componente es un campo que contiene datos de un tipo estrictamente definido o un método que realiza operaciones en un objeto. Un tipo de objeto puede heredar componentes de otro tipo de objeto. Si el tipo T2 hereda del tipo T1, entonces el tipo T2 es un hijo del tipo G, y el tipo G mismo es un padre del tipo G2. El siguiente código fuente proporciona un ejemplo de una declaración de tipo de objeto. tipo punto = objeto X, Y: entero; fin; Recto = objeto A, B: PuntoT; procedimiento Init(XA, YA, XB, YB: Entero); procedimiento Copiar (var R: TRectangle); procedimiento Move(DX, DY: Entero); procedimiento Crecer(DX, DY: Entero); procedimiento Intersecar(var R: TRectángulo); procedimiento Union(var R: TRectangle); función Contiene (P: Punto): Booleano; fin; A diferencia de otros tipos, los tipos de objetos solo se pueden declarar en la sección de declaración de tipos en el nivel más externo del alcance de un programa o módulo. Por lo tanto, los tipos de objetos no se pueden declarar en una sección de declaración de variables o dentro de un procedimiento, función o bloque de método. Un tipo de componente de tipo de archivo no puede tener un tipo de objeto ni ningún tipo de estructura que contenga componentes de tipo de objeto. 26. Herencia La herencia es el proceso de generar nuevos tipos secundarios a partir de tipos principales existentes, mientras que el secundario recibe (hereda) del principal todos sus campos y métodos. El tipo descendiente, en este caso, se denomina tipo heredero o hijo. Y el tipo del que hereda el tipo hijo se llama tipo padre. Los campos y métodos heredados se pueden usar sin cambios o redefinidos (modificados). N. Wirth en su lenguaje Pascal luchó por la máxima simplicidad, por lo que no lo complico al introducir la relación de herencia. Por lo tanto, los tipos en Pascal no pueden heredar. Sin embargo, Turbo Pascal 7.0 amplía este lenguaje para admitir la herencia. Una de esas extensiones es una nueva categoría de estructura de datos relacionada con registros, pero mucho más poderosa. Los tipos de datos en esta nueva categoría se definen utilizando la nueva palabra reservada Objeto. La sintaxis es muy similar a la sintaxis para definir registros: Tipo de Propiedad <nombre de tipo> = Objeto [(<nombre de tipo principal>)] ([<alcance>] <descripción de campos y métodos>)+ fin; El signo "+" después de una construcción de sintaxis entre paréntesis significa que esta construcción debe aparecer una o más veces en esta descripción. El ámbito es una de las siguientes palabras clave: ▪ Privado; ▪ Protegido; ▪ Público. El alcance caracteriza para qué partes del programa estarán disponibles los componentes cuyas descripciones siguen a la palabra clave que nombra este alcance. Para obtener más información sobre los alcances de los componentes, consulte la pregunta n.º 28. La herencia es una poderosa herramienta utilizada en el desarrollo de programas. Permite implementar en la práctica la descomposición orientada a objetos del problema, utilizando el lenguaje para expresar la relación entre objetos de tipos que forman una jerarquía, y también promueve la reutilización del código del programa. 27. Crear instancias de objetos Una instancia de un objeto se crea declarando una variable o constante de un tipo de objeto, o aplicando el procedimiento New estándar a una variable de tipo "puntero a tipo de objeto". El objeto resultante se denomina instancia del tipo de objeto. Si un tipo de objeto contiene métodos virtuales, las instancias de ese tipo de objeto deben inicializarse llamando a un constructor antes de llamar a cualquier método virtual. La asignación de una instancia de un tipo de objeto no implica la inicialización de la instancia. Un objeto se inicializa mediante un código generado por el compilador que se ejecuta entre la invocación del constructor y el punto en el que la ejecución llega realmente a la primera instrucción en el bloque de código del constructor. Si la instancia del objeto no se inicializa y la verificación de rango está habilitada (mediante la directiva {$R+}), la primera llamada al método virtual de la instancia del objeto genera un error en tiempo de ejecución. Si la directiva {$R-} desactiva la verificación de rango), la primera llamada a un método virtual de un objeto no inicializado puede provocar un comportamiento impredecible. La regla de inicialización obligatoria también se aplica a instancias que son componentes de tipos de estructuras. Por ejemplo: var Comentario: matriz [1..5] de TStrField; yo: entero comenzar para I:= 1 a 5 hacer Comentario [I].Init (1, I + 10, 40, 'first_name'); . . . para I:= 1 a 5 hacer comentario [I].Listo; fin; Para las instancias dinámicas, la inicialización suele ser la colocación y la limpieza es la eliminación, lo que se logra a través de la sintaxis extendida de los procedimientos estándar New y Dispose. Por ejemplo: var SP: StrFieldPtr; comenzar Nuevo (SP, Init (1, 1, 25, 'nombre'); SP^.Put('Vladímir'); SP^.Pantalla; . . . Desechar (SP, Listo); fin. Un puntero a un tipo de objeto es compatible con la asignación de un puntero a cualquier tipo de objeto principal, por lo que en tiempo de ejecución un puntero a un tipo de objeto puede apuntar a una instancia de ese tipo o a una instancia de cualquier tipo secundario. 28. Componentes y alcance El alcance de un identificador de bean se extiende más allá del tipo de objeto. Además, el alcance de un identificador de bean se extiende a través de los bloques de procedimientos, funciones, constructores y destructores que implementan los métodos del tipo de objeto y sus descendientes. Según estas consideraciones, el identificador del componente debe ser único dentro del tipo de objeto y dentro de todos sus descendientes, así como dentro de todos sus métodos. En una declaración de tipo de objeto, un encabezado de método puede especificar los parámetros del tipo de objeto que se describe, incluso si la declaración aún no está completa. Considere el siguiente esquema para una declaración de tipo que contiene componentes de todos los ámbitos válidos: Tipo de Propiedad <nombre de tipo> = Objeto [(<nombre de tipo principal>)] Privado <descripciones privadas de campos y métodos> Robusto <descripciones de métodos y campos protegidos> Público <descripciones públicas de campos y métodos> fin; Los campos y métodos descritos en la sección Privado solo se pueden usar dentro del módulo que contiene sus declaraciones y en ningún otro lugar. Los campos y métodos protegidos, es decir, los descritos en la sección Protegido, son visibles en el módulo donde se define el tipo y en los descendientes del tipo. Los campos y métodos de la sección Public no tienen restricciones en su uso y pueden usarse en cualquier parte del programa que tenga acceso a un objeto de este tipo. El alcance del identificador de componente descrito en la parte privada de la declaración de tipo se limita al módulo (programa) que contiene la declaración de tipo de objeto. En otras palabras, los beans identificadores privados actúan como identificadores públicos ordinarios dentro del módulo que contiene la declaración del tipo de objeto, y fuera del módulo, los beans e identificadores privados son desconocidos e inaccesibles. Al colocar tipos de objetos relacionados en el mismo módulo, puede hacer que estos objetos accedan a los componentes privados de los demás, y estos componentes privados serán desconocidos para otros módulos. 29. Métodos Una declaración de método dentro de un tipo de objeto corresponde a una declaración de método hacia adelante (forward). Por lo tanto, en algún lugar después de una declaración de tipo de objeto, pero dentro del mismo alcance que el alcance de la declaración de tipo de objeto, se debe implementar un método definiendo su declaración. Para métodos procedimentales y funcionales, la declaración de definición toma la forma de una declaración normal de procedimiento o función, con la excepción de que en este caso el identificador de procedimiento o función se trata como un identificador de método. La descripción definitoria de un método siempre contiene un parámetro implícito con identificador Self correspondiente a un parámetro variable formal de un tipo de objeto. Dentro de un bloque de método, Self representa la instancia cuyo componente de método se especificó para invocar el método. Por lo tanto, cualquier cambio en los valores de los campos Self se refleja en la instancia. Métodos virtuales Los métodos son estáticos por defecto, pero a excepción de los constructores, pueden ser virtuales (al incluir la directiva virtual en la declaración del método). El compilador resuelve las referencias a las llamadas a métodos estáticos durante el proceso de compilación, mientras que las llamadas a métodos virtuales se resuelven en tiempo de ejecución. Esto a veces se denomina vinculación tardía. Anular un método estático es independiente de cambiar el encabezado del método. Por el contrario, una anulación de método virtual debe conservar el orden, los tipos y nombres de parámetros y los tipos de resultados de funciones, si los hubiera. Además, la redefinición debe incluir nuevamente la directiva virtual. Métodos dinámicos Borland Pascal admite métodos enlazados en tiempo de ejecución adicionales denominados métodos dinámicos. Los métodos dinámicos difieren de los métodos virtuales solo en la forma en que se distribuyen en tiempo de ejecución. En todos los demás aspectos, los métodos dinámicos se consideran equivalentes a los métodos virtuales. Una declaración de método dinámico es equivalente a una declaración de método virtual, pero la declaración de método dinámico debe incluir el índice de método dinámico, que se especifica inmediatamente después de la palabra clave virtual. El índice de un método dinámico debe ser una constante entera entre 1 y 656535 y debe ser único entre los índices de otros métodos dinámicos contenidos en el tipo de objeto o sus ancestros. Por ejemplo: procedimiento FileOpen(var Msg: TMessage); 100 virtuales; Una anulación de un método dinámico debe coincidir con el orden, los tipos y los nombres de los parámetros, y debe coincidir exactamente con el tipo de resultado de la función del método principal. La anulación también debe incluir una directiva virtual seguida del mismo índice de método dinámico que se especificó en el tipo de objeto principal. 30. Constructores y destructores Los constructores y destructores son formas especializadas de métodos. Usados en conexión con la sintaxis extendida de los procedimientos estándar New y Dispose, los constructores y destructores tienen la capacidad de colocar y eliminar objetos dinámicos. Además, los constructores tienen la capacidad de realizar la inicialización requerida de objetos que contienen métodos virtuales. Como todos los métodos, los constructores y destructores se pueden heredar, y los objetos pueden contener cualquier número de constructores y destructores. Los constructores se utilizan para inicializar objetos recién creados. Normalmente, la inicialización se basa en los valores pasados al constructor como parámetros. Un constructor no puede ser virtual porque el mecanismo de despacho de un método virtual depende del constructor que inicializó el objeto primero. Estos son algunos ejemplos de constructores: constructor Field.Copy(var F: Campo); comenzar Yo:=F; fin; La acción principal de un constructor de un tipo derivado (hijo) es casi siempre llamar al constructor apropiado de su padre inmediato para inicializar los campos heredados del objeto. Después de ejecutar este procedimiento, el constructor inicializa los campos del objeto que pertenecen solo al tipo derivado. Los destructores son lo opuesto a los constructores y se usan para limpiar objetos después de que se hayan usado. Normalmente, la limpieza consiste en eliminar todos los campos de puntero del objeto. Nota Un destructor puede ser virtual, y con frecuencia lo es. Un destructor rara vez tiene parámetros. Estos son algunos ejemplos de destructores: campo destructor hecho; comenzar FreeMem(Nombre, Longitud(Nombre^) + 1); fin; destructor StrField.Hecho; comenzar FreeMem(Valor, Longitud); Campo Hecho; fin; El destructor de un tipo secundario, como el TStrField anterior. Listo, generalmente primero elimina los campos de puntero introducidos en el tipo derivado y luego, como último paso, llama al colector-destructor adecuado del padre inmediato para eliminar los campos de puntero heredados del objeto. 31. Destructores Borland Pascal proporciona un tipo especial de método llamado recolector de basura (o destructor) para limpiar y eliminar un objeto asignado dinámicamente. El destructor combina el paso de eliminar un objeto con cualquier otra acción o tarea requerida para ese tipo de objeto. Puede definir varios destructores para un solo tipo de objeto. Los destructores se pueden heredar y pueden ser estáticos o virtuales. Dado que los diferentes finalizadores tienden a requerir diferentes tipos de objetos, generalmente se recomienda que los destructores sean siempre virtuales para que se ejecute el destructor correcto para cada tipo de objeto. No es necesario especificar el destructor de palabras reservadas para cada método de limpieza, incluso si la definición de tipo del objeto contiene métodos virtuales. Los destructores realmente solo funcionan en objetos asignados dinámicamente. Cuando se limpia un objeto asignado dinámicamente, el destructor realiza una función especial: asegura que siempre se libere el número correcto de bytes en el área de memoria asignada dinámicamente. No puede haber preocupación por usar un destructor con objetos asignados estáticamente; de hecho, al no pasar el tipo de objeto al destructor, el programador priva a un objeto de ese tipo de todos los beneficios de la gestión de memoria dinámica en Borland Pascal. Los destructores en realidad se convierten en ellos mismos cuando los objetos polimórficos deben borrarse y cuando la memoria que ocupan debe desasignarse. Los objetos polimórficos son aquellos objetos que han sido asignados a un tipo padre debido a las reglas de compatibilidad de tipos extendidos de Borland Pascal. El término "polimórfico" es apropiado porque el código que procesa un objeto "no sabe" exactamente en el momento de la compilación qué tipo de objeto necesitará procesar eventualmente. Lo único que sabe es que este objeto pertenece a una jerarquía de objetos que son descendientes del tipo de objeto especificado. El método destructor en sí puede estar vacío y realizar solo esta función: destructorAnObject.Done; comenzar fin; Lo que es útil en este destructor no es la propiedad de su cuerpo, sin embargo, el compilador genera código de epílogo en respuesta a la palabra reservada del destructor. Es como un módulo que no exporta nada, pero hace un trabajo invisible al ejecutar su sección de inicialización antes de iniciar el programa. Toda la acción tiene lugar entre bastidores. 32. Métodos virtuales Un método se vuelve virtual si su declaración de tipo de objeto va seguida de la nueva palabra reservada virtual. Si un método en un tipo principal se declara como virtual, entonces todos los métodos con el mismo nombre en tipos secundarios también deben declararse virtuales para evitar un error de compilación. Los siguientes son los objetos de la nómina de ejemplo, debidamente virtualizados: escribe PEmpleado = ^TEmpleado; temployee = objeto Nombre, Título: cadena[25]; Tasa: Real; constructor Init(AName, ATitle: String; ARate: Real); función GetPayAmount: Real; virtual; función ObtenerNombre: Cadena; función ObtenerTítulo: Cadena; función GetRate: Real; procedimiento Mostrar; virtual; fin; PPor hora = ^Tpor hora; Cada hora = objeto (Empleado); Tiempo: Entero; constructor Init(AName, ATitle: String; ARate: Real; tiempo: entero); función GetPayAmount: Real; virtual; función GetTime: Entero; fin; PSasalariado = ^TSalariado; TSalariado = objeto(TEmpleado); función GetPayAmount: Real; virtual; fin; PComisionado = ^TComisionado; TComisionado = objeto (asalariado); Comisión: Real; Monto de Ventas: Real; constructor Init(AName, ATitle: String; ARate, AComisión, ASimporte de Ventas: Real); función GetPayAmount: Real; virtual; fin; Un constructor es un tipo especial de procedimiento que realiza algún trabajo de configuración para el mecanismo del método virtual. Además, el constructor debe llamarse antes de llamar a cualquier método virtual. Llamar a un método virtual sin llamar primero al constructor puede bloquear el sistema y el compilador no tiene forma de verificar el orden en que se llama a los métodos. Cada tipo de objeto que tiene métodos virtuales debe tener un constructor. Se debe llamar al constructor antes de llamar a cualquier otro método virtual. Llamar a un método virtual sin una llamada previa al constructor puede provocar un bloqueo del sistema y el compilador no puede verificar el orden en que se llama a los métodos. 33. Campos de datos de objetos y parámetros de métodos formales La implicación del hecho de que los métodos y sus objetos comparten un ámbito común es que los parámetros formales de un método no pueden ser idénticos a ninguno de los campos de datos del objeto. Esta no es una nueva limitación impuesta por la programación orientada a objetos, sino las mismas viejas reglas de alcance que Pascal siempre ha tenido. Esto es lo mismo que prohibir que los parámetros formales de un procedimiento sean idénticos a las variables locales del procedimiento. Considere un ejemplo que ilustra este error para un procedimiento: procedimiento CrunchIt(Crunchee: MyDataRec, Crunchby, código de error: entero); var A, B: carbón; Código de error: entero; comenzar . . . fin; Se produce un error en la línea que contiene la declaración de la variable local ErrorCode. Esto se debe a que los identificadores del parámetro formal y la variable local son los mismos. Las variables locales de un procedimiento y sus parámetros formales comparten un ámbito común y, por lo tanto, no pueden ser idénticos. Recibirá un mensaje de "Error 4: identificador duplicado" si intenta compilar algo como esto. El mismo error ocurre al intentar asignar un parámetro de método formal al nombre del campo del objeto al que pertenece este método. Las circunstancias son algo diferentes, ya que poner el encabezado de la subrutina dentro de una estructura de datos es un guiño a una innovación en Turbo Pascal, pero los principios básicos del alcance de Pascal no han cambiado. Aún debe respetar una cultura particular al elegir identificadores de variables y parámetros. Algunos estilos de programación ofrecen formas de nombrar campos de tipo para reducir el riesgo de identificadores duplicados. Por ejemplo, la notación húngara sugiere que los nombres de campo comiencen con un prefijo "m". 34. Encapsulación La combinación de código y datos en un objeto se denomina encapsulación. En principio, es posible proporcionar suficientes métodos para que el usuario de un objeto nunca acceda directamente a los campos del objeto. Algunos otros lenguajes orientados a objetos, como Smalltalk, requieren una encapsulación obligatoria, pero Borland Pascal tiene una opción. Por ejemplo, los objetos TEmployee y THourly están escritos de tal manera que no hay absolutamente ninguna necesidad de acceder directamente a sus campos de datos internos: tipo temployee = objeto Nombre, Título: cadena[25]; Tasa: Real; procedimiento Init(AName, ATitle: cadena; ARate: Real); función ObtenerNombre: Cadena; función ObtenerTítulo: Cadena; función GetRate: Real; función GetPayAmount: Real; fin; Cada hora = objeto (Empleado) Tiempo: Entero; procedimiento Init(AName, ATitle: string; ARate: Real, Atime: Entero); función GetPayAmount: Real; fin; Aquí solo hay cuatro campos de datos: Nombre, Título, Tarifa y Hora. Los métodos GetName y GetTitle muestran el apellido y el cargo del trabajador, respectivamente. El método GetPayAmount utiliza Tasa, y en el caso de una jornada laboral THora y Hora para calcular el importe de los pagos a la jornada laboral. Ya no es necesario referirse directamente a estos campos de datos. Asumiendo la existencia de una instancia de AnHourly de tipo THourly, podríamos usar un conjunto de métodos para manipular los campos de datos de AnHourly, así: con un hacer por hora comenzar Init (Aleksandr Petrov, Operador de montacargas' 12.95, 62); {Muestra el apellido, la posición y la cantidad pagos} Espectáculo; fin; Cabe señalar que el acceso a los campos de un objeto se realiza solo con la ayuda de los métodos de este objeto. 35. Objetos desplegables Si se define un tipo derivado, los métodos del tipo principal se heredan, pero se pueden invalidar si se desea. Para anular un método heredado, simplemente declare un nuevo método con el mismo nombre que el método heredado, pero con un cuerpo diferente y (si es necesario) un conjunto diferente de parámetros. Definamos un tipo secundario de TEmployee que represente a un empleado al que se le paga una tarifa por hora en el siguiente ejemplo: const Períodos de pago = 26; { períodos de pago } Umbral de horas extras = 80; { para el período de pago } Factor de tiempo extra = 1.5; { tarifa por hora } tipo Cada hora = objeto (Empleado) Tiempo: Entero; procedimiento Init(AName, ATitle: string; ARate: Real, Atime: Entero); función GetPayAmount: Real; fin; procedimiento THourly.Init(AName, ATitle: string; ARate: Real, Atime: Entero); comenzar TEmployee.Init(UNNombre, ATítulo, ARate); Hora:= HoraA; fin; función THourly.GetPayAmount: Real; var Horas extra: Entero; comenzar Horas extras:= Tiempo - Umbral de horas extras; si Horas extra > 0 entonces GetPayAmount:= RoundPay(Overtime Threshold * Rate + Tasa de tiempo extra * Factor de tiempo extra *Velocidad) más GetPayAmount:= RoundPay(Tiempo * Tasa) fin; Al llamar a un método anulado, debe asegurarse de que el tipo de objeto derivado incluya la funcionalidad del padre. Además, cualquier cambio en el método principal afecta automáticamente a todos los descendientes. Nota importante: si bien los métodos se pueden anular, los campos de datos no se pueden anular. Una vez que se ha definido un campo de datos en una jerarquía de objetos, ningún tipo secundario puede definir un campo de datos con exactamente el mismo nombre. 36. Compatibilidad de tipos de objetos La herencia modifica las reglas de compatibilidad de tipos de Borland Pascal hasta cierto punto. Un descendiente hereda la compatibilidad de tipos de todos sus antepasados. Esta compatibilidad de tipo extendida adopta tres formas: 1) entre implementaciones de objetos; 2) entre punteros a implementaciones de objetos; 3) entre parámetros formales y reales. La compatibilidad de tipos solo se extiende de hijo a padre. Por ejemplo, TSalaried es hijo de TEmployee y TCommissioned es hijo de TSalaried. Considere las siguientes descripciones: var UnEmpleado: TEmpleado; A Asalariado: T Asalariado; PComisionado: TComisionado; TEmployeePtr: ^TEmployee; TSalariadoPtr: ^TSalariado; TComisionadoPtr: ^TComisionado; Bajo estas descripciones, los siguientes operadores de asignación son válidos: UnEmpleado:=ASalariado; ASalariado:= AComisionado; TComisionadoPtr:= AComisionado; En general, la regla de compatibilidad de tipos se formula de la siguiente manera: la fuente debe poder llenar completamente el receptor. Los tipos derivados contienen todo lo que contienen sus tipos principales debido a la propiedad de herencia. Por lo tanto, el tipo derivado tiene un tamaño no menor que el tamaño del padre. Asignar un objeto principal a un objeto secundario podría dejar algunos campos del objeto principal sin definir, lo que es peligroso y, por lo tanto, ilegal. En las declaraciones de asignación, solo los campos que son comunes a ambos tipos se copiarán del origen al destino. En el operador de asignación: UnEmpleado:= UnComisionado; Solo los campos Nombre, Título y Tarifa de AComisionado se copiarán a AnEmployee, ya que estos son los únicos campos que se comparten entre TComisionado y TEmployee. La compatibilidad de tipos también funciona entre punteros a tipos de objetos y sigue las mismas reglas generales que para las implementaciones de objetos. Un puntero a un hijo se puede asignar a un puntero al padre. Dadas las definiciones anteriores, las siguientes asignaciones de punteros son válidas: TSalariadoPtr:= TComisionadoPtr; TEmployeePtr:= TSalariadoPtr; TEmployeePtr:= PComisionadoPtr; Un parámetro formal (ya sea un valor o un parámetro variable) de un tipo de objeto dado puede tomar como parámetro real un objeto de su propio tipo u objetos de todos los tipos secundarios. Si define un encabezado de procedimiento como este: procedimiento CalcFedTax(Víctima: TSalariado); entonces los tipos de parámetros reales pueden ser TSalariado o TComisionado, pero no TEmployee. La víctima también puede ser un parámetro variable. En este caso, se siguen las mismas reglas de compatibilidad. El parámetro de valor es un puntero al objeto real que se envía como parámetro, y el parámetro variable es una copia del parámetro real. Esta copia incluye solo aquellos campos que forman parte del tipo del parámetro de valor formal. Esto significa que el parámetro real se convierte al tipo del parámetro formal. 37. Sobre el ensamblador Érase una vez, el ensamblador era un lenguaje sin saberlo, era imposible hacer que una computadora hiciera algo útil. Poco a poco la situación cambió. Aparecieron medios más convenientes de comunicación con una computadora. Pero a diferencia de otros lenguajes, ensamblador no murió; además, no podía hacer esto en principio. ¿Por qué? En busca de una respuesta, intentaremos comprender qué es el lenguaje ensamblador en general. En resumen, el lenguaje ensamblador es una representación simbólica del lenguaje máquina. Todos los procesos en la máquina en el nivel de hardware más bajo son impulsados solo por comandos (instrucciones) del lenguaje de la máquina. De esto queda claro que, a pesar del nombre común, el lenguaje ensamblador para cada tipo de computadora es diferente. Esto también se aplica a la apariencia de los programas escritos en ensamblador, y las ideas que este lenguaje refleja. Resolver realmente problemas relacionados con el hardware (o, más aún, relacionados con el hardware, como acelerar un programa, por ejemplo) es imposible sin conocimientos de ensamblador. Un programador o cualquier otro usuario puede usar cualquier herramienta de alto nivel hasta programas para construir mundos virtuales y, tal vez, ni siquiera sospechar que la computadora no está ejecutando realmente los comandos del lenguaje en el que está escrito su programa, sino su representación transformada. en forma de una secuencia aburrida y aburrida de comandos de un lenguaje completamente diferente: lenguaje de máquina. Ahora imagine que ese usuario tiene un problema no estándar. Por ejemplo, su programa debe funcionar con algún dispositivo inusual o realizar otras acciones que requieren el conocimiento de los principios del hardware de la computadora. Por muy bueno que sea el lenguaje en el que el programador escribió su programa, no puede prescindir de conocer el ensamblador. Y no es casualidad que casi todos los compiladores de lenguajes de alto nivel contengan medios para conectar sus módulos con módulos en ensamblador o admitan el acceso al nivel de programación en ensamblador. Una computadora se compone de varios dispositivos físicos, cada uno conectado a una sola unidad llamada unidad del sistema. 38. Modelo de software del microprocesador En el mercado informático actual, existe una amplia variedad de diferentes tipos de computadoras. Por lo tanto, es posible suponer que el consumidor tendrá una pregunta: cómo evaluar las capacidades de un tipo (o modelo) particular de una computadora y sus características distintivas de las computadoras de otros tipos (modelos). Considerar solo el diagrama de bloques de una computadora no es suficiente para esto, ya que fundamentalmente difiere poco en diferentes máquinas: todas las computadoras tienen RAM, un procesador y dispositivos externos. Diferentes son las formas, medios y recursos utilizados por los cuales la computadora funciona como un solo mecanismo. Para reunir todos los conceptos que caracterizan a una computadora en términos de sus propiedades funcionales controladas por programa, existe un término especial: arquitectura de la computadora. Por primera vez se empezó a mencionar el concepto de arquitectura de computadores con el advenimiento de las máquinas de tercera generación para su evaluación comparativa. Tiene sentido comenzar a aprender el lenguaje ensamblador de cualquier computadora solo después de descubrir qué parte de la computadora queda visible y disponible para programar en este lenguaje. Este es el llamado modelo de programa de computadora, parte del cual es el modelo de programa de microprocesador, que contiene 32 registros que están más o menos disponibles para que los use el programador. Estos registros se pueden dividir en dos grandes grupos: 1) 16 registros de usuarios; 2) 16 registros del sistema. Los programas en lenguaje ensamblador usan registros en gran medida. La mayoría de los registros tienen un propósito funcional específico. Además de los registros enumerados anteriormente, los desarrolladores de procesadores introducen registros adicionales en el modelo de software diseñado para optimizar ciertas clases de cálculos. Entonces, en la familia de procesadores Pentium Pro (MMX) de Intel Corporation, se introdujo la extensión MMX de Intel. Incluye 8 (MM0-MM7) registros de 64 bits y le permite realizar operaciones con números enteros en pares de varios tipos de datos nuevos: 1) ocho bytes empaquetados; 2) cuatro palabras empaquetadas; 3) dos palabras dobles; 4) palabra cuádruple; En otras palabras, con una sola instrucción de extensión MMX, un programador puede, por ejemplo, sumar dos palabras dobles juntas. Físicamente no se han añadido nuevos registros. MM0-MM7 son las mantisas (64 bits inferiores) de una pila de registros FPU (unidad de punto flotante - coprocesador) de 80 bits. Además, en este momento existen las siguientes extensiones del modelo de programación: ¡3DNOW! de AMD; SSE, SSE2, SSE3, SSE4. Las últimas 4 extensiones son compatibles con los procesadores AMD e Intel. 39. Registros de usuarios Como su nombre lo indica, los registros de usuario se llaman porque el programador puede usarlos al escribir sus programas. Estos registros incluyen: 1) ocho registros de 32 bits que los programadores pueden usar para almacenar datos y direcciones (también se denominan registros de propósito general (RON)): ▪ eax/ax/ah/al; ▪ ebx/bx/bh/bl; ▪ edx/dx/dh/dl; ▪ ecx/cx/ch/cl; ▪ pb/pb; ▪ esi/si; ▪ edición/di; ▪ esp/esp. 2) registros de seis segmentos: ▪ sc; ▪ ds; ▪ ss; ▪ es; ▪fs; ▪gs; 3) registros de estado y control: ▪ banderas registran eflags/flags; ▪ registro de puntero de comando eip/ip. La siguiente figura muestra los principales registros del microprocesador: Registros de propósito general
40. Registros de propósito general Todos los registros de este grupo permiten acceder a sus partes "inferiores". Solo las partes inferiores de 16 y 8 bits de estos registros se pueden utilizar para el autodireccionamiento. Los 16 bits superiores de estos registros no están disponibles como objetos independientes. Enumeremos los registros pertenecientes al grupo de registros de propósito general. Dado que estos registros están ubicados físicamente en el microprocesador dentro de la unidad lógica aritmética (ALU), también se denominan registros ALU: 1) eax/ax/ah/al (registro acumulador) - batería. Se utiliza para almacenar datos intermedios. En algunos comandos se requiere el uso de este registro; 2) ebx/bx/bh/bl (Registro base) - registro base. Se utiliza para almacenar la dirección base de algún objeto en la memoria; 3) ecx/cx/ch/cl (registro de conteo) - registro de contador. Se utiliza en comandos que realizan algunas acciones repetitivas. Su uso suele estar implícito y oculto en el algoritmo del comando correspondiente. Por ejemplo, el comando de organización de bucles, además de transferir el control a un comando ubicado en una determinada dirección, analiza y decrementa en uno el valor del registro ecx/cx; 4) edx/dx/dh/dl (registro de datos) - registro de datos. Al igual que el registro eax/ax/ah/al, almacena datos intermedios. Algunos comandos requieren su uso; para algunos comandos esto sucede implícitamente. Los dos registros siguientes se utilizan para admitir las llamadas operaciones en cadena, es decir, operaciones que procesan secuencialmente cadenas de elementos, cada uno de los cuales puede tener 32, 16 u 8 bits de longitud: 1) esi/si (registro de índice de origen) - índice de origen. Este registro en operaciones en cadena contiene la dirección actual del elemento en la cadena fuente; 2) edi/di (Registro de índice de destino) - índice del receptor (destinatario). Este registro en operaciones en cadena contiene la dirección actual en la cadena de destino. En la arquitectura del microprocesador a nivel de hardware y software, se admite una estructura de datos como una pila. Para trabajar con la pila en el sistema de instrucciones del microprocesador hay comandos especiales, y en el modelo de software del microprocesador hay registros especiales para esto: 1) esp/sp (registro de puntero de pila) - registro de puntero de pila. Contiene un puntero a la parte superior de la pila en el segmento de pila actual. 2) ebp/bp (registro de puntero base): registro de puntero base del marco de pila. Diseñado para organizar el acceso aleatorio a los datos dentro de la pila. El uso de fijaciones fijas de registros para algunas instrucciones hace posible codificar su representación de máquina de manera más compacta. Si es necesario, conocer estas características ahorrará al menos algunos bytes de memoria ocupados por el código del programa. 41. Registros de segmento Hay seis registros de segmento en el modelo de software del microprocesador: cs, ss, ds, es, gs, fs. Su existencia se debe a los detalles de la organización y el uso de RAM por parte de los microprocesadores Intel. Se encuentra en el hecho de que el hardware del microprocesador soporta la organización estructural del programa en forma de tres partes, llamadas segmentos. En consecuencia, tal organización de la memoria se llama segmentada. Para indicar los segmentos a los que tiene acceso el programa en un momento determinado, se pretenden registros de segmento. De hecho (con una ligera corrección) estos registros contienen las direcciones de memoria a partir de las cuales comienzan los segmentos correspondientes. La lógica del procesamiento de una instrucción de máquina se construye de tal manera que cuando se obtiene una instrucción, se accede a los datos del programa o se accede a la pila, se utilizan implícitamente direcciones en registros de segmentos bien definidos. El microprocesador admite los siguientes tipos de segmentos. 1. Segmento de código. Contiene comandos de programa. Para acceder a este segmento, se utiliza el registro cs (registro de segmento de código), el registro de código de segmento. Contiene la dirección del segmento de instrucciones de la máquina al que tiene acceso el microprocesador (es decir, estas instrucciones se cargan en la canalización del microprocesador). 2. Segmento de datos. Contiene los datos procesados por el programa. Para acceder a este segmento, se utiliza el registro ds (registro de segmento de datos), un registro de datos de segmento que almacena la dirección del segmento de datos del programa actual. 3. Segmento de pila. Este segmento es una región de memoria llamada pila. El microprocesador organiza el trabajo con la pila de acuerdo con el siguiente principio: el último elemento escrito en esta área se selecciona primero. Para acceder a este segmento, se utiliza el registro ss (registro de segmento de pila), el registro de segmento de pila que contiene la dirección del segmento de pila. 4. Segmento de datos adicional. Implícitamente, los algoritmos para ejecutar la mayoría de las instrucciones de máquina asumen que los datos que procesan están ubicados en el segmento de datos, cuya dirección está en el registro del segmento ds. Si un segmento de datos no es suficiente para el programa, entonces tiene la oportunidad de usar tres segmentos de datos adicionales. Pero a diferencia del segmento de datos principal, cuya dirección está contenida en el registro del segmento ds, cuando se usan segmentos de datos adicionales, sus direcciones deben especificarse explícitamente usando prefijos especiales de redefinición de segmento en el comando. Las direcciones de los segmentos de datos adicionales deben estar contenidas en los registros es, gs, fs (registros de segmentos de datos de extensión). 42. Registros de estado y control El microprocesador incluye varios registros que contienen constantemente información sobre el estado del propio microprocesador y del programa cuyas instrucciones se cargan actualmente en la tubería. Estos registros incluyen: 1) registro de banderas eflags/banderas; 2) registro de puntero de comando eip/ip. Con estos registros, puede obtener información sobre los resultados de la ejecución de comandos e influir en el estado del propio microprocesador. Consideremos con más detalle la finalidad y el contenido de estos registros. 1. eflags/flags (registro de banderas) - registro de banderas. La profundidad de bits de eflags/flags es de 32/16 bits. Los bits individuales de este registro tienen un propósito funcional específico y se denominan banderas. La parte inferior de este registro es completamente análoga al registro de banderas para i8086. Dependiendo de cómo se utilicen, las banderas del registro eflags/flags se pueden dividir en tres grupos: 1) ocho banderas de estado. Estos indicadores pueden cambiar después de que se hayan ejecutado las instrucciones de la máquina. Las banderas de estado del registro de banderas electrónicas reflejan los detalles del resultado de la ejecución de operaciones aritméticas o lógicas. Esto hace posible analizar el estado del proceso computacional y responder a él mediante comandos de salto condicional y llamadas a subrutinas. 2) una bandera de control. Denotado df (bandera de directorio). Se encuentra en el bit 10 del registro de banderas electrónicas y lo utilizan los comandos encadenados. El valor de la bandera df determina la dirección del procesamiento elemento por elemento en estas operaciones: desde el principio de la cadena hasta el final (df = 0) o viceversa, desde el final de la cadena hasta su principio (df = 1). Para trabajar con la bandera df, existen comandos especiales: cld (eliminar la bandera df) y std (establecer la bandera df). El uso de estos comandos le permite ajustar el indicador df de acuerdo con el algoritmo y garantizar que los contadores se incrementen o disminuyan automáticamente al realizar operaciones en cadenas. 3) cinco banderas del sistema. Controla la E/S, las interrupciones enmascarables, la depuración, el cambio de tareas y el modo virtual 8086. No se recomienda que los programas de aplicación modifiquen estos indicadores innecesariamente, ya que esto hará que el programa finalice en la mayoría de los casos. 2. eip/ip (registro de puntero de instrucción) - registro de puntero de instrucción. El registro eip/ip tiene 32/16 bits de ancho y contiene el desplazamiento de la siguiente instrucción a ejecutar en relación con el contenido del registro del segmento cs en el segmento de instrucción actual. El programador no puede acceder directamente a este registro, pero su valor se carga y cambia mediante varios comandos de control, que incluyen comandos para saltos condicionales e incondicionales, procedimientos de llamada y retorno de procedimientos. La ocurrencia de interrupciones también modifica el registro eip/ip. 43. Registros del sistema del microprocesador El mismo nombre de estos registros sugiere que realizan funciones específicas en el sistema. El uso de los registros del sistema está estrictamente regulado. Son ellos quienes proporcionan el modo protegido. También se pueden considerar como parte de la arquitectura del microprocesador, que se deja visible deliberadamente para que un programador de sistemas calificado pueda realizar las operaciones de más bajo nivel. Los registros del sistema se pueden dividir en tres grupos: 1) cuatro registros de control; El grupo de registros de control incluye 4 registros: ▪ cr0; ▪ cr1; ▪ cr2; ▪ cr3; 2) cuatro registros de dirección del sistema (también llamados registros de gestión de memoria); Los registros de dirección del sistema incluyen los siguientes registros: ▪ registro de tabla de descriptores globales gdtr; ▪ registro de tabla de descriptores locales Idtr; ▪ idtr del registro de la tabla de descriptores de interrupción; ▪ registro de tareas tr de 16 bits; 3) ocho registros de depuración. Éstos incluyen: ▪ dr0; ▪ dr1; ▪ dr2; ▪ dr3; ▪ dr4; ▪ dr5; ▪ dr6; ▪ dr7. El conocimiento de los registros del sistema no es necesario para escribir programas en Assembler, debido a que se utilizan principalmente para las operaciones de más bajo nivel. Sin embargo, las tendencias actuales en el desarrollo de software (especialmente a la luz de las capacidades de optimización significativamente mayores de los compiladores modernos de lenguajes de alto nivel, que a menudo generan código que es superior en eficiencia al código humano) están reduciendo el alcance de Assembler para resolver los problemas más bajos. -Problemas de nivel, donde el conocimiento de los registros anteriores puede resultar muy útil. 44. Registros de control El grupo de registros de control incluye cuatro registros: cr0, cr1, cr2, cr3. Estos registros son para el control general del sistema. Los registros de control solo están disponibles para programas con nivel de privilegio 0. Aunque el microprocesador tiene cuatro registros de control, solo tres de ellos están disponibles: se excluye cr1, cuyas funciones aún no están definidas (está reservado para uso futuro). El registro cr0 contiene indicadores del sistema que controlan los modos de funcionamiento del microprocesador y reflejan su estado globalmente, independientemente de las tareas específicas que se realicen. Propósito de las banderas del sistema: 1) pe (habilitación de protección), bit 0: habilita el modo protegido. El estado de esta bandera indica en cuál de los dos modos, real (pe = 0) o protegido (pe = 1), el microprocesador está funcionando en un momento dado; 2) mp (Math Present), bit 1 - la presencia de un coprocesador. Siempre 1; 3) ts (Tarea cambiada), bit 3 - cambio de tarea. El procesador establece automáticamente este bit cuando cambia a otra tarea; 4) am (Máscara de alineación), bit 18 - máscara de alineación. Este bit habilita (am = 1) o deshabilita (am = 0) el control de alineación; 5) cd (deshabilitar caché), bit 30: deshabilita la memoria caché. Usando este bit, puede deshabilitar (cd = 1) o habilitar (cd = 0) el uso del caché interno (el caché de primer nivel); 6) pg (paginación), bit 31: habilitar (pg = 1) o deshabilitar (pg = 0) paginación. La bandera se utiliza en el modelo de paginación de la organización de la memoria. El registro cr2 se usa en la paginación de RAM para registrar la situación cuando la instrucción actual accedió a la dirección contenida en una página de memoria que actualmente no está en la memoria. En tal situación, ocurre una excepción número 14 en el microprocesador y la dirección lineal de 32 bits de la instrucción que provocó esta excepción se escribe en el registro cr2. Con esta información, el manejador de excepciones 14 determina la página deseada, la cambia a memoria y reanuda la operación normal del programa; El registro cr3 también se usa para paginar la memoria. Este es el llamado registro de directorio de páginas de primer nivel. Contiene la dirección base física de 20 bits del directorio de la página de la tarea actual. Este directorio contiene 1024 descriptores de 32 bits, cada uno de los cuales contiene la dirección de la tabla de páginas de segundo nivel. A su vez, cada una de las tablas de páginas de segundo nivel contiene 1024 descriptores de 32 bits que direccionan los marcos de página en la memoria. El tamaño del marco de la página es de 4 KB. 45. Registros de direcciones del sistema Estos registros también se denominan registros de gestión de memoria. Están diseñados para proteger programas y datos en el modo multitarea del microprocesador. Cuando se opera en modo protegido por microprocesador, el espacio de direcciones se divide en: 1) global - común a todas las tareas; 2) local - separado para cada tarea. Esta separación explica la presencia de los siguientes registros del sistema en la arquitectura del microprocesador: 1) el registro de la tabla de descriptores globales gdtr (Global Descriptor Table Register), que tiene un tamaño de 48 bits y contiene una dirección base de 32 bits (bits 16-47) de la tabla de descriptores globales GDT y una dirección base de 16 bits (bits 0-15) valor límite, que es el tamaño en bytes de la tabla GDT; 2) el registro de tabla de descriptor local ldtr (Registro de tabla de descriptor local), que tiene un tamaño de 16 bits y contiene el llamado selector de descriptor de la tabla de descriptor local LDT. Este selector es un puntero a la GDT que describe el segmento que contiene la tabla de descriptores locales LDT; 3) el registro de la tabla de descriptores de interrupciones idtr (Registro de tabla de descriptores de interrupciones), que tiene un tamaño de 48 bits y contiene una dirección base de 32 bits (bits 16-47) de la tabla de descriptores de interrupciones IDT y una dirección base de 16 bits (bits 0-15). XNUMX-XNUMX) valor límite, que es el tamaño en bytes de la tabla IDT; 4) registro de tareas de 16 bits tr (registro de tareas), que, al igual que el registro ldtr, contiene un selector, es decir, un puntero a un descriptor en la tabla GDT. Este descriptor describe el estado actual del segmento de tareas (TSS). Este segmento se crea para cada tarea del sistema, tiene una estructura estrictamente regulada y contiene el contexto (estado actual) de la tarea. El objetivo principal de los segmentos TSS es guardar el estado actual de una tarea en el momento de cambiar a otra tarea. 46. Registros de depuración Este es un grupo muy interesante de registros destinados a la depuración de hardware. Las herramientas de depuración de hardware aparecieron por primera vez en el microprocesador i486. En el hardware, el microprocesador contiene ocho registros de depuración, pero solo se utilizan seis de ellos. Los registros dr0, dr1, dr2, dr3 tienen un ancho de 32 bits y están diseñados para establecer direcciones lineales de cuatro puntos de interrupción. El mecanismo utilizado en este caso es el siguiente: cualquier dirección generada por el programa actual se compara con las direcciones de los registros dr0... dr3, y si hay coincidencia se genera una excepción de depuración con el número 1. El registro dr6 se denomina registro de estado de depuración. Los bits en este registro se establecen de acuerdo con las razones que causaron que ocurriera la última excepción número 1. Enumeramos estos bits y su propósito: 1) b0: si este bit se establece en 1, la última excepción (interrupción) ocurrió como resultado de alcanzar el punto de control definido en el registro dr0; 2) b1: similar a b0, pero para un punto de control en el registro dr1; 3) b2: similar a b0, pero para un punto de control en el registro dr2; 4) b3: similar a b0, pero para un punto de control en el registro dr3; 5) bd (bit 13) - sirve para proteger los registros de depuración; 6) bs (bit 14) - establecido en 1 si la excepción 1 fue causada por el estado de la bandera tf = 1 en el registro de banderas electrónicas; 7) bt (bit 15) se establece en 1 si la excepción 1 fue causada por un cambio a una tarea con el bit de captura establecido en TSS t = 1. Todos los demás bits en este registro se llenan con ceros. El controlador de excepciones 1, según el contenido de dr6, debe determinar el motivo por el cual ocurrió la excepción y tomar las acciones necesarias. El registro dr7 se denomina registro de control de depuración. Contiene campos para cada uno de los cuatro registros de punto de interrupción de depuración que le permiten especificar las siguientes condiciones bajo las cuales se debe generar una interrupción: 1) ubicación de registro del punto de control: solo en la tarea actual o en cualquier tarea. Estos bits ocupan los 8 bits inferiores del registro dr7 (2 bits para cada punto de interrupción (en realidad un punto de interrupción) establecidos por los registros dr0, drl, dr2, dr3, respectivamente). El primer bit de cada par es la denominada resolución local; configurarlo le dice al punto de interrupción que tenga efecto si está dentro del espacio de direcciones de la tarea actual. El segundo bit de cada par define el permiso global, que indica que el punto de interrupción dado es válido dentro de los espacios de direcciones de todas las tareas que residen en el sistema; 2) el tipo de acceso por el cual se inicia la interrupción: solo al buscar un comando, al escribir o al escribir/leer datos. Los bits que determinan la naturaleza de la ocurrencia de una interrupción se encuentran en la parte superior de este registro. La mayoría de los registros del sistema son accesibles mediante programación. 47. La estructura del programa en ensamblador Un programa en lenguaje ensamblador es una colección de bloques de memoria llamados segmentos de memoria. Un programa puede constar de uno o más de estos bloques-segmentos. Cada segmento contiene una colección de oraciones de lenguaje, cada una de las cuales ocupa una línea separada de código de programa. Las declaraciones de ensamblaje son de cuatro tipos. Comandos o instrucciones que son contrapartes simbólicas de instrucciones de máquina. Durante el proceso de traducción, las instrucciones de ensamblaje se convierten en los comandos correspondientes del conjunto de instrucciones del microprocesador. Una instrucción de ensamblador, por regla general, corresponde a una instrucción de microprocesador, lo que, en términos generales, es típico de los lenguajes de bajo nivel. Aquí hay un ejemplo de una instrucción que incrementa en uno el número binario almacenado en el registro eax: inc. ▪ macrocomandos: oraciones de texto de programa formateadas de cierta manera, reemplazadas durante la transmisión por otras oraciones. Un ejemplo de una macro es la siguiente macro de fin de programa: salir de macro movax,4c00h Int 21h fin ▪ directivas, que son instrucciones para que el traductor ensamblador realice ciertas acciones. Las directivas no tienen equivalentes en la representación de máquinas; Como ejemplo, aquí está la directiva TITLE que establece el título del archivo de listado: %TITLE "Listado 1" ▪ líneas de comentarios que contengan caracteres, incluidas letras del alfabeto ruso. El traductor ignora los comentarios. Ejemplo: ; esta linea es un comentario 48. Sintaxis de ensamblaje Las oraciones que componen un programa pueden ser una construcción sintáctica correspondiente a un comando, macro, directiva o comentario. Para que el traductor ensamblador los reconozca, deben estar formados de acuerdo con ciertas reglas sintácticas. Para ello, lo mejor es utilizar una descripción formal de la sintaxis del lenguaje, como las reglas de la gramática. Las formas más comunes de describir un lenguaje de programación de esta manera son los diagramas de sintaxis y las formas extendidas de Backus-Naur. Cuando trabaje con diagramas de sintaxis, preste atención a la dirección de recorrido, indicada por las flechas. Los diagramas de sintaxis reflejan la lógica del traductor al analizar las oraciones de entrada del programa. Caracteres válidos: 1) todas las letras latinas: A - Z, a - z; 2) números del 0 al 9; 3) signos? ps 4) separadores. Las fichas son las siguientes. 1. Identificadores: secuencias de caracteres válidos utilizados para designar códigos de operación, nombres de variables y nombres de etiquetas. Un identificador no puede comenzar con un número. 2. Cadenas de caracteres: secuencias de caracteres entre comillas simples o dobles. 3. Números enteros. Posibles tipos de sentencias en ensamblador. 1. Operadores aritméticos. Éstos incluyen: 1) "+" y "-" unarios; 2) "+" y "-" binarios; 3) multiplicación "*"; 4) división entera "/"; 5) obtener el resto de la división "mod". 2. Los operadores de desplazamiento desplazan la expresión por el número especificado de bits. 3. Los operadores de comparación (devuelven "verdadero" o "falso") están diseñados para formar expresiones lógicas. 4. Los operadores lógicos realizan operaciones bit a bit en expresiones. 5. Operador de índice []. 6. El operador de redefinición de tipo ptr se utiliza para redefinir o calificar el tipo de una etiqueta o variable definida por una expresión. 7. El operador de redefinición de segmento ":" (dos puntos) hace que la dirección física se calcule en relación con el componente de segmento especificado. 8. Operador de denominación de tipo de estructura "." (punto) también hace que el compilador realice ciertos cálculos si ocurre en una expresión. 9. El operador para obtener el segmento componente de la dirección de la expresión seg devuelve la dirección física del segmento para la expresión, que puede ser una etiqueta, variable, nombre de segmento, nombre de grupo o algún nombre simbólico. 10. El operador para obtener el desplazamiento de la expresión desplazamiento le permite obtener el valor del desplazamiento de la expresión en bytes con respecto al comienzo del segmento en el que se define la expresión. 49. Directivas de segmentación La segmentación es parte de un mecanismo más general relacionado con el concepto de programación modular. Implica la unificación del diseño de los módulos de objetos creados por el compilador, incluidos los de diferentes lenguajes de programación. Esto le permite combinar programas escritos en diferentes idiomas. Los operandos en la directiva SEGMENT están destinados a la implementación de varias opciones para tal unión. Permítanos considerarlos con más detalle. 1. El atributo de alineación del segmento (tipo de alineación) le dice al enlazador que se asegure de que el comienzo del segmento se coloque en el límite especificado: 1) BYTE: no se realiza la alineación; 2) PALABRA: el segmento comienza en una dirección que es un múltiplo de dos, es decir, el último bit (menos significativo) de la dirección física es 0 (alineado con el límite de la palabra); 3) DWORD: el segmento comienza en una dirección que es un múltiplo de cuatro; 4) PARA: el segmento comienza en una dirección que es un múltiplo de 16; 5) PÁGINA: el segmento comienza en una dirección que es un múltiplo de 256; 6) MEMPAGE: el segmento comienza en una dirección que es un múltiplo de 4 KB. 2. El atributo de segmento de combinación (tipo combinatorio) le dice al enlazador cómo combinar segmentos de diferentes módulos que tienen el mismo nombre: 1) PRIVADO: el segmento no se fusionará con otros segmentos con el mismo nombre fuera de este módulo; 2) PÚBLICO: obliga al enlazador a conectar todos los segmentos con el mismo nombre; 3) COMÚN: tiene todos los segmentos con el mismo nombre en la misma dirección; 4) AT xxxx: ubica el segmento en la dirección absoluta del párrafo; 5) PILA - definición de un segmento de pila. 3. Un atributo de clase de segmento (tipo de clase) es una cadena entre comillas que ayuda al enlazador a determinar el orden de segmento adecuado al ensamblar un programa a partir de varios segmentos de módulo. 4. Atributo de tamaño de segmento: 1) USE16: esto significa que el segmento permite el direccionamiento de 16 bits; 2) USE32: el segmento será de 32 bits. Tiene que haber alguna manera de compensar la imposibilidad. controlar directamente la colocación y combinación de segmentos. Para hacer esto, comenzaron a usar la directiva para especificar el modelo de memoria MODEL. Esta directiva vincula segmentos, que en el caso de usar directivas de segmentación simplificadas, tienen nombres predefinidos, con registros de segmento (aunque aún debe inicializar ds explícitamente). El parámetro obligatorio de la directiva MODEL es el modelo de memoria. Este parámetro define el modelo de segmentación de memoria para la POU. Se supone que un módulo de programa puede tener solo ciertos tipos de segmentos, que están definidos por las directivas de descripción de segmento simplificadas que mencionamos anteriormente. 50. Estructura de instrucciones de la máquina Un comando de máquina es una indicación al microprocesador, codificada según ciertas reglas, para realizar alguna operación o acción. Cada comando contiene elementos que definen: 1) ¿Qué hacer? 2) objetos en los que se debe hacer algo (estos elementos se denominan operandos); 3) ¿cómo hacer? La longitud máxima de una instrucción máquina es de 15 bytes. 1. Prefijos. Elementos de instrucción de máquina opcionales, cada uno de los cuales es de 1 byte o puede omitirse. En la memoria, los prefijos preceden al comando. El propósito de los prefijos es modificar la operación realizada por el comando. Una aplicación puede utilizar los siguientes tipos de prefijos: 1) prefijo de reemplazo de segmento; 2) el prefijo de longitud de bit de dirección especifica la longitud de bit de la dirección (32 bits o 16 bits); 3) el prefijo de longitud de bits del operando es similar al prefijo de longitud de bits de la dirección, pero indica la longitud de bits del operando (32 bits o 16 bits) con la que funciona el comando; 4) El prefijo de repetición se usa con comandos encadenados. 2. Código de operación. Elemento obligatorio que describe la operación realizada por el comando. 3. Modo de direccionamiento byte modr/m. El valor de este byte determina la forma de dirección del operando utilizada. Los operandos pueden estar en la memoria en uno o dos registros. Si el operando está en la memoria, entonces el byte modr/m especifica los componentes (registros de compensación, base e índice) utilizado para calcular su domicilio efectivo. El byte modr/m consta de tres campos: 1) el campo mod determina el número de bytes ocupados en la instrucción por la dirección del operando; 2) el campo reg/cop determina el registro ubicado en el comando en lugar del primer operando, o una posible extensión del código de operación; 3) el campo r/m se usa junto con el campo mod y determina el registro ubicado en el comando en el lugar del primer operando (si mod = 11), o los registros base e índice usados para calcular la dirección efectiva (junto con el campo de desplazamiento en el comando). 4. Escala de bytes - índice - base (byte sib). Se utiliza para ampliar las posibilidades de direccionamiento de operandos. El byte sib consta de tres campos: 1) campos de escala ss. Este campo contiene el factor de escala para el índice del componente de índice, que ocupa los siguientes 3 bits del byte sib; 2) campos de índice. Se utiliza para almacenar el número de registro de índice que se utiliza para calcular la dirección efectiva del operando; 3) campos base. Se utiliza para almacenar el número de registro base, que también se utiliza para calcular la dirección efectiva del operando. 5. Comando de campo compensado. Un entero con signo de 8, 16 o 32 bits que representa, en su totalidad o en parte (sujeto a las consideraciones anteriores), el valor de la dirección efectiva del operando. 6. El campo del operando inmediato. Un campo opcional que representa 8-, Operando inmediato de 16 o 32 bits. La presencia de este campo, por supuesto, se refleja en el valor del byte modr/m. 51. Métodos para especificar operandos de instrucción El operando se establece implícitamente en el nivel de firmware En este caso, la instrucción explícitamente no contiene operandos. El algoritmo de ejecución de comandos utiliza algunos objetos predeterminados (registros, banderas en eflags, etc.). El operando se especifica en la propia instrucción (operando inmediato) El operando está en el código de instrucción, es decir, es parte de él. Para almacenar dicho operando, se asigna un campo de hasta 32 bits de longitud en la instrucción. El operando inmediato solo puede ser el segundo operando (fuente). El operando de destino puede estar en la memoria o en un registro. El operando está en uno de los registros.Los operandos de registro se especifican mediante nombres de registro. Los registros se pueden utilizar: 1) registros de 32 bits EAX, EBX, ECX, EDX, ESI, EDI, ESP, EBP; 2) registros de 16 bits AX, BX, CX, DX, SI, DI, SP, BP; 3) registros de 8 bits AH, AL, BH, BL, CH, CL, DH, DL; 4) registros de segmento CS, DS, SS, ES, FS, GS. Por ejemplo, el comando add ax,bx agrega el contenido de los registros ax y bx y escribe el resultado en bx. El comando dec si decrementa el contenido de si en 1. El operando está en la memoria. Esta es la forma más compleja y al mismo tiempo más flexible de especificar operandos. Le permite implementar los siguientes dos tipos principales de direccionamiento: directo e indirecto. A su vez, el direccionamiento indirecto tiene las siguientes variedades: 1) direccionamiento base indirecto; su otro nombre es registro de direccionamiento indirecto; 2) direccionamiento indirecto de base con desplazamiento; 3) direccionamiento de índice indirecto con desplazamiento; 4) direccionamiento de índice base indirecto; 5) direccionamiento de índice base indirecto con desplazamiento. El operando es un puerto de E/S. Además del espacio de direcciones de RAM, el microprocesador mantiene un espacio de direcciones de E/S, que se utiliza para acceder a los dispositivos de E/S. El espacio de direcciones de E/S es de 64 KB. Las direcciones se asignan para cualquier dispositivo informático en este espacio. Un valor de dirección particular dentro de este espacio se denomina puerto de E/S. Físicamente, el puerto de E/S corresponde a un registro de hardware (que no debe confundirse con un registro de microprocesador), al que se accede mediante instrucciones especiales de entrada y salida del ensamblador. El operando está en la pila. Las instrucciones pueden no tener operandos, pueden tener uno o dos operandos. La mayoría de las instrucciones requieren dos operandos, uno de los cuales es el operando de origen y el otro es el operando de destino. Es importante que un operando pueda ubicarse en un registro o memoria, y el segundo operando debe estar en un registro o directamente en la instrucción. Un operando inmediato solo puede ser un operando fuente. En una instrucción de máquina de dos operandos, son posibles las siguientes combinaciones de operandos: 1) registro - registro; 2) registro - memoria; 3) memoria - registro; 4) operando inmediato - registro; 5) operando inmediato - memoria. 52. Métodos de direccionamiento Direccionamiento directo Esta es la forma más sencilla de direccionar un operando en la memoria, ya que la dirección efectiva está contenida en la instrucción misma y no se utilizan fuentes o registros adicionales para formarla. La dirección efectiva se toma directamente del campo de compensación de la instrucción de la máquina, que puede ser de 8, 16 o 32 bits. Este valor identifica de forma única el byte, la palabra o la palabra doble que se encuentra en el segmento de datos. El direccionamiento directo puede ser de dos tipos. Direccionamiento directo relativo Se utiliza para instrucciones de salto condicional para indicar la dirección de salto relativa. La relatividad de tal transición radica en el hecho de que el campo de compensación de la instrucción de la máquina contiene un valor de 8, 16 o 32 bits que, como resultado de la operación de la instrucción, se agregará al contenido de el registro de puntero de instrucción ip/eip. Como resultado de esta adición, se obtiene la dirección a la que se realiza la transición. Direccionamiento directo absoluto En este caso, la dirección efectiva es parte de la instrucción de la máquina, pero esta dirección se forma solo a partir del valor del campo de compensación en la instrucción. Para formar la dirección física del operando en la memoria, el microprocesador agrega este campo con el valor del registro del segmento desplazado en 4 bits. Se pueden usar varias formas de este direccionamiento en una instrucción del ensamblador. Direccionamiento indirecto básico (registro) Con este direccionamiento, la dirección efectiva del operando puede estar en cualquiera de los registros de propósito general, excepto sp/esp y bp/ebp (son registros específicos para trabajar con un segmento de pila). Sintácticamente en un comando, este modo de direccionamiento se expresa encerrando el nombre del registro entre corchetes []. Direccionamiento base indirecto (registro) con desplazamiento Este tipo de direccionamiento es una adición al anterior y está diseñado para acceder a datos con un desplazamiento conocido en relación con alguna dirección base. Este tipo de direccionamiento es conveniente para acceder a los elementos de las estructuras de datos, cuando el desplazamiento de los elementos se conoce de antemano, en la etapa de desarrollo del programa, y la dirección base (de inicio) de la estructura debe calcularse dinámicamente, en la etapa de ejecución del programa. Direccionamiento de índice indirecto con desplazamiento Este tipo de direccionamiento es muy similar al direccionamiento indirecto de base con un desplazamiento. Aquí también se utiliza uno de los registros de propósito general para formar la dirección efectiva. Pero el direccionamiento de índices tiene una característica interesante que es muy conveniente para trabajar con arreglos. Está conectado con la posibilidad del llamado escalado de los contenidos del registro de índice. Direccionamiento de índice base indirecto Con este tipo de direccionamiento, la dirección efectiva se forma como la suma del contenido de dos registros de propósito general: base e índice. Estos registros pueden ser cualquier registro de propósito general y, a menudo, se usa la escala del contenido de un registro de índice. Direccionamiento de índice base indirecto con desplazamiento Este tipo de direccionamiento es el complemento del direccionamiento indirecto indexado. La dirección efectiva se forma como la suma de tres componentes: el contenido del registro base, el contenido del registro de índice y el valor del campo de compensación en el comando. 53. Comandos de transferencia de datos Comandos generales de transferencia de datos Este grupo incluye los siguientes comandos: 1) mov es el comando principal de transferencia de datos; 2) xchg: se utiliza para la transferencia de datos bidireccional. Comandos de E/S de puerto Fundamentalmente, administrar dispositivos directamente a través de los puertos es fácil: 1) en acumulador, número de puerto: entrada al acumulador desde el puerto con el número de puerto; 2) puerto de salida, acumulador: envía el contenido del acumulador al puerto con el número de puerto. Comandos de conversión de datos Muchas instrucciones de microprocesador se pueden atribuir a este grupo, pero la mayoría de ellas tienen ciertas características que requieren que se atribuyan a otros grupos funcionales. Comandos de pila Este grupo es un conjunto de comandos especializados enfocados en organizar un trabajo flexible y eficiente con la pila. La pila es un área de memoria especialmente asignada para el almacenamiento temporal de datos de programas. Hay tres registros para trabajar con la pila: 1) ss - registro de segmento de pila; 2) sp/esp - registro de puntero de pila; 3) bp/ebp - registro de puntero base del marco de pila. Para organizar el trabajo con la pila, existen comandos especiales para escribir y leer. 1. empujar la fuente: escribir el valor de la fuente en la parte superior de la pila. 2. asignación pop: escribir el valor desde la parte superior de la pila hasta la ubicación especificada por el operando de destino. Por lo tanto, el valor se "elimina" de la parte superior de la pila. 3. pusha: un comando de escritura grupal en la pila. 4. pushaw es casi sinónimo del comando pusha. El atributo bitness puede ser use16 o use32. R 5. pushad: se realiza de manera similar al comando pusha, pero hay algunas peculiaridades. Los siguientes tres comandos realizan el reverso de los comandos anteriores: 1) papá; 2) papaya; 3) pop. El grupo de instrucciones que se describe a continuación le permite guardar el registro de bandera en la pila y escribir una palabra o palabra doble en la pila. 1. pushf - guarda el registro de banderas en la pila. 2. pushfw: guarda un registro de banderas del tamaño de una palabra en la pila. Siempre funciona como pushf con el atributo use16. 3. pushfd - guardar el registro flags o eflags flags en la pila dependiendo del atributo de ancho de bits del segmento (es decir, lo mismo que pushf). De manera similar, los siguientes tres comandos realizan el reverso de las operaciones discutidas anteriormente: 1) popf; 2) ventana emergente; 3) popfd. 54. Comandos aritméticos Dichos comandos funcionan con dos tipos: 1) números binarios enteros, es decir, con números codificados en el sistema numérico binario. Los números decimales son un tipo especial de representación de información numérica, que se basa en el principio de codificar cada dígito decimal de un número por un grupo de cuatro bits. El microprocesador realiza la suma de operandos de acuerdo con las reglas para sumar números binarios. Hay tres instrucciones de suma binaria en el conjunto de instrucciones del microprocesador: 1) inc operando - aumenta el valor del operando; 2) agregar operando1, operando2 - suma; 3) adc operando1, operando2 - suma, teniendo en cuenta la bandera de acarreo cf. Resta de números binarios sin signo Si el minuendo es mayor que el sustraendo, entonces la diferencia es positiva. Si el minuendo es menor que el restado, hay un problema: el resultado es menor que 0, y este ya es un número con signo. Después de restar números sin signo, debe analizar el estado de la bandera CF. Si se establece en 1, entonces se ha tomado prestado el bit más significativo y el resultado está en el código de complemento a dos. Resta de números binarios con un signo Pero para la resta mediante la suma de números con un signo en un código adicional, es necesario representar ambos operandos, tanto el minuendo como el sustraendo. El resultado también debe tratarse como un valor de complemento a dos. Pero aquí surgen dificultades. En primer lugar, están relacionados con el hecho de que el bit más significativo del operando se considera un bit de signo. De acuerdo con el contenido de la bandera de desbordamiento de. Establecerlo en 1 indica que el resultado está fuera del rango de los números con signo (es decir, el bit más significativo ha cambiado) para un operando de este tamaño y el programador debe tomar medidas para corregir el resultado. El principio de restar números con un rango de representación que excede las cuadrículas de bits de operandos estándar es el mismo que para la suma, es decir, se usa la bandera de acarreo cf. Solo necesita imaginar el proceso de restar en una columna y combinar correctamente las instrucciones del microprocesador con la instrucción sbb. El comando para multiplicar números sin signo es mulfactor_1 El comando para multiplicar números con signo es [imul operando_1, operando_2, operando_3] El comando div divisor es para dividir números sin signo. El comando idiv divisor es para dividir números con signo. 55. Comandos lógicos De acuerdo con la teoría, las siguientes operaciones lógicas se pueden realizar en declaraciones (en bits). 1. Negación (NO lógico): una operación lógica en un operando, cuyo resultado es el recíproco del valor del operando original. 2. Suma lógica (OR inclusivo lógico): una operación lógica en dos operandos, cuyo resultado es "verdadero" (1) si uno o ambos operandos son verdaderos (1) y "falso" (0) si ambos operandos son falso (0). 3. Multiplicación lógica (AND lógico): una operación lógica en dos operandos, cuyo resultado es verdadero (1) solo si ambos operandos son verdaderos (1). En todos los demás casos, el valor de la operación es "falso" (0). 4. Adición exclusiva lógica (OR exclusivo lógico): una operación lógica en dos operandos, cuyo resultado es "verdadero" (1), si solo uno de los dos operandos es verdadero (1) y falso (0), si ambos operandos son falsos (0) o verdaderos (1). 4. Adición exclusiva lógica (OR exclusivo lógico): una operación lógica en dos operandos, cuyo resultado es "verdadero" (1), si solo uno de los dos operandos es verdadero (1) y falso (0), si ambos operandos son falsos (0) o verdaderos (1). El siguiente conjunto de comandos que admiten trabajar con datos lógicos: 1) y operando_1, operando_2 - operación de multiplicación lógica; 2) u operando_1, operando_2 - operación de suma lógica; 3) xor operando_1, operando_2 - operación de suma exclusiva lógica; 4) prueba operando_1, operando_2 - operación de "prueba" (por multiplicación lógica) 5) no operando - operación de negación lógica. a) para poner a 1 ciertos dígitos (bits), se utiliza el comando u operando_1, operando_2; b) para restablecer ciertos dígitos (bits) a 0, se utiliza el comando y operando_1, operando_2; c) se aplica el comando xor operando_1, operando_2: ▪ descubrir qué bits del operando_1 y del operando_2 son diferentes; ▪ invertir el estado de los bits especificados en el operando_1. El comando probar operando_1, operando_2 (comprobar operando_1) se utiliza para comprobar el estado de los bits especificados. El resultado del comando es establecer el valor de la bandera cero zf: 1) si zf = 0, entonces, como resultado de la multiplicación lógica, se obtuvo un resultado cero, es decir, un bit unitario de la máscara, que no coincidía con el bit unitario correspondiente del operando1; 2) si zf = 1, entonces la multiplicación lógica dio como resultado un resultado distinto de cero, es decir, al menos un bit unitario de la máscara coincidió con el bit correspondiente del operando1. Todas las instrucciones de desplazamiento mueven bits en el campo del operando hacia la izquierda o hacia la derecha según el código de operación. Todas las instrucciones de turno tienen la misma estructura: operando policía, contador de turno. 56. Comandos de transferencia de control Qué instrucción de programa debe ejecutarse a continuación, el microprocesador aprende del contenido del par de registros cs: (e) ip: 1) cs - registro de segmento de código, que contiene la dirección física del segmento de código actual; 2) eip/ip - registro puntero de instrucción, contiene el valor de compensación en memoria de la siguiente instrucción a ejecutar. Saltos incondicionales Lo que necesita ser modificado depende de: 1) en el tipo de operando en la instrucción de bifurcación incondicional (cerca o lejos); 2) de especificar un modificador antes de la dirección de transición; en este caso, la propia dirección de salto puede estar directamente en la instrucción (salto directo) o en un registro de memoria (salto indirecto). Valores del modificador: 1) cerca de ptr: transición directa a la etiqueta; 2) far ptr - transición directa a una etiqueta en otro segmento de código; 3) palabra ptr - transición indirecta a la etiqueta; 4) dword ptr: transición indirecta a una etiqueta en otro segmento de código. instrucción de salto incondicional jmp jmp [modificador] jump_address Un procedimiento o subrutina es la unidad funcional básica de la descomposición de alguna tarea. Un procedimiento es un grupo de comandos. Saltos condicionales El microprocesador tiene 18 instrucciones de salto condicional. Estos comandos le permiten verificar: 1) la relación entre operandos con signo (“más es menos”); 2) relación entre operandos sin signo ("mayor menor"); 3) estados de las banderas aritméticas ZF, SF, CF, OF, PF (pero no AF). Las instrucciones de salto condicional tienen la misma sintaxis: etiqueta de salto jcc El comando cmp compare tiene una forma interesante de trabajar. Es exactamente lo mismo que el comando de resta: sub operando_1, operando_2. El comando cmp, como el comando sub, resta operandos y establece indicadores. Lo único que no hace es escribir el resultado de la resta en lugar del primer operando. La sintaxis del comando cmp - cmp operando_1, operando_2 (comparar) - compara dos operandos y establece indicadores en función de los resultados de la comparación. Organización de ciclos Puede organizar la ejecución cíclica de una determinada sección del programa, por ejemplo, utilizando la transferencia condicional de comandos de control o el comando de salto incondicional jmp: 1) etiqueta de transición de bucle (Loop): repite el bucle. El comando le permite organizar bucles similares a los bucles for en lenguajes de alto nivel con disminución automática del contador de bucles; 2) etiqueta de salto loope/loopz Los comandos loope y loopz son sinónimos absolutos; 3) etiqueta de salto loopne/loopnz Los comandos loopne y loopnz también son sinónimos absolutos. Los comandos loope/loopz y loopne/loopnz son recíprocos en su funcionamiento. Autor: Tsvetkova A.V.
▪ Derecho constitucional de la Federación Rusa. Cuna ▪ Traumatología y ortopedia. Cuna ▪ Informática y tecnologías de la información. Cuna
Trampa de aire para insectos.
01.05.2024 La amenaza de los desechos espaciales al campo magnético de la Tierra
01.05.2024 Solidificación de sustancias a granel.
30.04.2024
▪ Transceptor de 60 GHz con autocalibración integrada ▪ Lentes que restauran la visión
▪ sección del sitio Relojes, temporizadores, relés, interruptores de carga. Selección de artículos ▪ artículo Juventud dorada. expresión popular ▪ artículo ¿Quién dibujó la primera caricatura? Respuesta detallada ▪ artículo de Ferul Lehmann. Leyendas, cultivo, métodos de aplicación. ▪ artículo Masillas de caucho para vidrio. recetas simples y consejos
Hogar | Biblioteca | Artículos | Mapa del sitio | Revisiones del sitio
www.diagrama.com.ua |


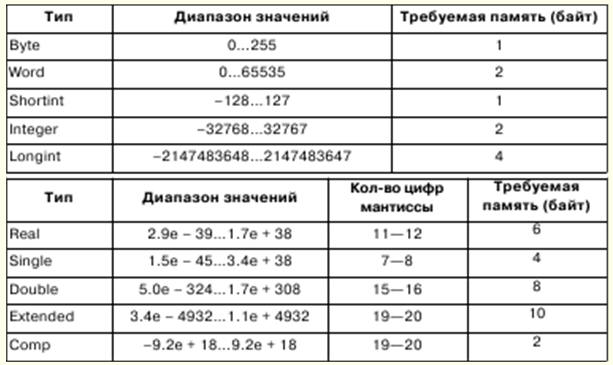

 Ver otros artículos sección
Ver otros artículos sección 